Oracle 9i New Features
Dynamic SGA
The dynamic SGA infrastructure will allow for the sizing of the Buffer
Cache, Shared Pool and the Large Pool (see note below) without having
to shutdown the database. In this new model, a new unit of allocation
is created called the 'Granule'. A granule is a unit of contiguous
virtual memory allocation. The size of a granule depends on the
estimated total SGA size, whose calculation is based on the value of
the parameter SGA_MAX_SIZE. This would be 4MB if the SGA size is less
than 128MB, else it will be 16MB. The Buffer Cache, Shared Pool and
Large Pool are allowed to grow and shrink based on granule boundaries.
At instance startup the Oracle Server allocates the granule entries,
one for each granule to support SGA_MAX_SIZE bytes of address space.
During the startup each component acquires as many granules as it
requires. The minimum SGA is three granules, as follows:
1. One Granule for Fixed SGA (includes redo buffers)
2. One Granule for Buffer Cache
3. One Granule for Shared Pool
We can alter the granules allocated to components using the 'ALTER
SYSTEM' command. The granules are rounded up to the nearest of the
default graunule size (4MB or 16MB). Example:
alter system set shared_pool_size=64M
You can create an SPFILE from an init.ora file and vice versa with the
CREATE SPFILE and CREATE PFILE commands.
Most parts of the SGA can be dynamically resized and have default
sizes.
Changing init.ora parameters
Before Oracle9i, Oracle instances were always started using a text file
called an init<SID>.ora. This file is by default located in the
"$ORACLE_HOME/dbs" directory. In Oracle9i, Oracle has also introduced
the 'SPFILE', which is a binary file stored on the database Server.
Changes which are applied to the instance parameters may be persistent
accross all startup/shutdown procedures. In Oracle9i, you can startup
the instance using either an spfile or an init.ora file.
The default initialization files must are located as follows:
- on Unix ---> $ORACLE_HOME/dbs
- on WindowsNT/2000 ---> %ORACLE_HOME%\database
1. Specifying neither file:
sqlplus /nolog
SQL> connect / as sysdba
SQL> startup
Oracle first searches if the spfile<SID>.ora exists. If it does
not, Oracle searchs for the spfile.ora parameter file. If neither
spfile<SID>.ora nor spfile.ora exist, Oracle will use the
init<SID>.ora parameter file.
2. Specifying init.ora file:
This behavior is the same as in previous database versions.
SQL> startup pfile=d:\ora901\database\initORA901.ora
3. Specifying spfile:
In this case, you must startup with an init.ora file in which you only
specify the spfile parameter full name:
spfile=d:\ora901\database\spfiletest.ora
SQL> startup pfile=d:\ora901\database\inittest.ora
So in order to modify an init.ora parameter and make it persistant you
should:
1- Backup your init.ora file
2- sqlplus "/ as sysdba"
3- create pfile from spfile;
4- edit your init.ora file created by the previous command and
add/modify your parameter
5- shutdown immediate
6- create spfile from pfile;
7- startup
Startup the DB Remotely
1- Check that the server has a SPFILE
2- Create at the client PC the file pfilename.ora with just one line
with
spfile=/u01/app/oracle/...../spfileSID.ora -->
Location of the spfile on the server
3- Sqlplus /nolog
4- connect user/password@DB as sysdba
5- startup pfile=pfilename.ora
Parameter Scope
The scope of the ALTER SYSTEM SET command can be defined using the
following:
ALTER SYSTEM SET parameter
= value SCOPE=[SPFILE/MEMORY/BOTH];
The actions of the scope parameters are:
A parameter value can be reset to the default using:
ALTER SYSTEM RESET
OPEN_CURSORS SID='*' SCOPE='SPFILE';
In a Real Application Cluster (RAC) environment node-specific
parameters
can be set using the SID parameter:
ALTER SYSTEM SET
OPEN_CURSORS=500 SID='SID1' SCOPE='SPFILE';
Multiple
Block Sizes
Oracle 9i supports tablespaces with different block sizes. This allows
large tables and indexes to have a larger block size than smaller
objects. This is especially useful for indexes on OLTP. The database is
created with a standard block size and up to 5 none-standard block
sizes.
The DB_BLOCK_SIZE is used to
specify the standard block size which is used for the SYSTEM and
TEMPORARY tablespaces. All subsequent tablespaces will also be assigned
this block size unless specified otherwise.
The DB_CACHE_SIZE parameter,
rather than DB_BLOCK_BUFFERS, is used to define the size of the buffer
cache for the standard block size. This can be set to any size, but it
will be rounded to the nearest whole granule. If the total SGA is less
then 128M the granule size is 4M, greater than 128M and it becomes 16M.
The DB_CACHE_SIZE must be at least 1 granule in size and defaults to
48M.
An individual buffer cache must be defined for each non-standard block
size used. These are set up with the following parameters which default
to a size of 0M:
DB_2K_CACHE_SIZE = 0M
DB_4K_CACHE_SIZE = 0M
DB_8K_CACHE_SIZE = 0M
DB_16K_CACHE_SIZE = 0M
DB_32K_CACHE_SIZE = 0M
The instance must be restarted before changes to these parameters take
effect. The DB_nK_CACHE_SIZE parameters can only be set to zero if
there are no online tablespace with a nK block size.
alter system
set DB_2K_CACHE_SIZE = 8M scope=pfile;
alter system
set DB_16K_CACHE_SIZE = 8M scope=pfile;
Once the caches are defined the tablespaces can be defined:
CREATE TABLESPACE TS_2k datafile '.../....' size xxx BLOCKSIZE 2K
extent management local;
CREATE TABLESPACE TS_8k datafile '.../....' size xxx BLOCKSIZE 8K
extent management local;
The KEEP and RECYCLE buffer caches can only be defined for the
standard block size. In 8i these were defined using the
BUFFER_POOL_KEEP and BUFFER_POOL_RECYCLE parameters, with their memory
was taken from the total DB_BLOCK_BUFFERS.
In 9i the parameters have been changed to DB_KEEP_CACHE_SIZE and DB_RECYLE_CACHE_SIZE, with their
memory allocations being totally separate to the main buffer cache.
A number of rules apply to the use of variable block sizes:
Automatic
SQL Execution Memory Management and Oracle self-tune PGA memory
The performance of complex long running queries, typical in a DSS
environment, depends to a large extent on the memory available in the
Program Global Area (PGA). In Oracle8i and previous releases of the
database, administrators sized the PGA by carefully adjusting a number
of initialization parameters. Oracle9i completely automates the
management of PGA memory. Administrators merely need to specify the
maximum amount of PGA memory available to an instance using a newly
introduced parameter PGA_AGGREGATE_TARGET. The database server
automatically distributes this memory among various active queries in
an intelligent manner so as to ensure maximum performance benefits and
the most efficient utilization of memory. Furthermore, Oracle9i can
adapt itself to changing workload thus utilizing resources efficiently
regardless of the load on the system. The amount of the PGA memory
available to an instance can be dynamically changed by altering the
value of the PGA_AGGREGATE_TARGET parameter making it possible to add
to and remove PGA memory from an active instance online. In the
automatic mode, administrators no longer have to manually tune the
sizes of the individual work areas using parameters such as
SORT_AREA_SIZE,
HASH_AREA_SIZE, BITMAP_MERGE_AREA_SIZE and CREATE_BITMAP_AREA_SIZE.
The automatic SQL execution memory management feature is enabled by
setting the parameter WORK_AREA_SIZE to AUTO. For backward
compatibility reasons, Oracle9i continues to support the manual PGA
management mode. The manual mode can be activated by either setting the
WORK_AREA_SIZE parameter to MANUAL or not specifying a value for
PGA_AGGREGATE_TARGET.
In Summary, you can have Oracle self-tune PGA memory usage
instead of setting sort_area_size, hash_area_size,
bitmap_merge_area_size, and create_bitmap_area_size manually.
- Set PGA_AGGREGATE_TARGET to the total amount of physical memory
available for use by all dedicated server processes.
- Oracle will then self-tune the *_AREA_SIZE parameters for all
dedicated server connections.
- You can still set the *_AREA_SIZE parameters manually and omit
PGA_AGGREGATE_TARGET for manual tuning.
How To Tune PGA_AGGREGATE_TARGET (from ML note
223730.1)
To determine the appropriate setting for PGA_AGGREGATE_TARGET
parameter I recommend to follow the following steps:
1- Make a first estimate
for PGA_AGGREGATE_TARGET based on the
following rule:
PGA_AGGREGATE_TARGET = (<Total Physical
Memory > * 0.16) - For OLTP systems (16% of
Server Physical Mem)
PGA_AGGREGATE_TARGET = (<Total Physical
Memory > * 0 .4 ) - For DSS systems
(40% of Server Physical Mem)
So for example if we have an Oracle instance configured on system with
16G of Physical memory, then the suggested PGA_AGGREGATE_TARGET
parameter value we should start with incase we have OLTP system
is (16 G * .16) ~= 2.5G and in case we have DSS system is (16 G * 0.4)
~= 6.5 G.
In the above equation we assume that 20 % of the memory will be used by
the OS, and in OLTP system 20 % of the remaining memory will be
used for PGA_AGGREGATE_TARGET and the remaining memory is going
for Oracle SGA memory and non-oracle processes memory. So make sure
that you have enough memory for your SGA and also for non-oracle
processes
2- Use the view v$sysstat
to check PGA_AGGREGATE_TARGET
values.
The following query gives the total number and the percentage of times
work areas were executed in these three modes since the database
instance was started.
select substr(name,1,32) profile,
cnt count,
decode(total, 0, 0, round(cnt*100/total)) percentage
from (select name, value
cnt, (sum(value) over ()) total
from v$sysstat
where name like 'workarea exec%');
PROFILE
CNT PERCENTAGE
--------------------------------
---------- ----------
workarea executions -
optimal
9378431 99
--> operations performed in memory
workarea executions -
onepass
47 1 -->
operations performed in disk
workarea executions -
multipass
14 0 -->
operations performed in disk
This output of this query is used to tell the DBA when to dynamically
adjust pga_aggregate_target. These executions fall into three
categories:
OPTIMAL: Operations that were performed in memory
ONEPASS: When the operation was too big to be performed in memory, then
part of it spills onto disk.
MULTIPASS: If more that one pass was needed on disk.
Ideally all executions should be in the optimal statistics and the
onepass and multipass should be 0.
3- Monitor
performance using available PGA statistics and see if
PGA_AGGREGATE_TARGET
is under-sized or over-sized. Several dynamic performance views are
available for this purpose:
- V$PGASTAT
This view provides instance-level statistics on the PGA memory usage
and the automatic PGA memory manager. For example:
select substr(name,1,40) name, value, unit from V$PGASTAT;
NAME
VALUE UNIT
---------------------------------------- ---------- ------------
aggregate PGA target
parameter
250609664 bytes (a)
aggregate PGA auto
target
103809024 bytes
global memory
bound
12529664 bytes (b)
total PGA
inuse
135284736 bytes (c)
total PGA
allocated
149349376 bytes (d)
maximum PGA
allocated
250475520 bytes
total freeable PGA
memory
2883584 bytes
PGA memory freed back to
OS
6.0456E+11 bytes
total PGA used for auto
workareas
0 bytes (e)
maximum PGA used for auto
workareas 13918208 bytes
total PGA used for manual
workareas
0 bytes
maximum PGA used for manual
workareas
0 bytes
over allocation
count
0
(f)
bytes
processed
1.2039E+12 bytes
extra bytes
read/written
107754496 bytes
cache hit
percentage
99.99 percent (g)
Main statistics to look at :
(a) aggregate PGA auto target
: This gives the amount of PGA memory
Oracle can use for work areas running in automatic mode. This
part of memory represent the tunable part of PGA memory,i.e. memory
allocated for intensive memory
SQL operators like sorts, hash-join, group-by, bitmap merge and
bitmap index create. This memory part can be shrinked/expanded in
function of the system load. Other parts of PGA memory are known
as untunable, i.e. they require a size that can't be negociated
(e.g. context information for each session, for each open/active
cursor, PL/SQL or Java memory).
So, the aggregate PGA auto target should not be small compared to the
value of PGA_AGGREGATE_TARGET. You must ensure that enough PGA
memory is left for work areas running in automatic mode.
(b) Global memory bound – This
statistic measures the max size of a work area, and Oracle recommends
that whenever this statistics drops below one megabyte, then you should
increase the value of the pga_aggregate_target parameter
(c) total PGA in used: This
gives the total PGA memory in use. The
detail of this value can be found in the PGA_USED_MEM column of the
v$process view. At this time it will be very useful to use the
following query to see allocated, used and maximum memory for all
connections to Oracle. We can see the RAM demands of each of the
background processes and we also have detailed information about
individual connections.Note that it is possible to join the v$process
view with the v$sql_plan table to take a closer look at the RAM memory
demands of specific connections.
select substr(program,1,30) program, pga_used_mem, pga_alloc_mem,
pga_max_mem
from v$process;
(d)Total PGA allocated – This
statistic display the high-water mark of all PGA memory usage on the
database. You should see this value approach the value of
pga_aggregate_target as usage increases.
(e) total PGA used for auto workarea:
This gives the actual tunable PGA
memory used by the system. This statistic monitors RAM consumption or
all connections that are running in automatic memory mode.
Remember, not all internal processes may use the automatic memory
feature. For example, Java and PL/SQL will allocate RAM memory,
and this will not be counted in this statistic. Hence, we can
subtract value to the total PGA allocated to see the amount of memory
used by connections and the RAM memory consumed by Java and PL/SQL
(f) over allocation count:
Over-allocating PGA memory can happen if the
value of PGA_AGGREGATE_TARGET is too small to accommodate the untunable
PGA memory part plus the minimum memory required to execute the work
area workload. When this happens, Oracle cannot honor the
initialization parameter PGA_AGGREGATE_TARGET, and extra PGA memory
needs to be allocated. Over allocation count is the number of time the
system was detected in this state since database startup. This count
should ideally be equal to zero.
(g) cache hit percentage: This
metric is computed by Oracle to reflect
the performance of the PGA memory component. It is cumulative from
instance start-up. A value of 100% means that all work areas executed
by the system since instance start-up have used an optimal amount of
PGA memory. This is, of course, ideal but rarely happens except maybe
for pure OLTP systems. In reality, some work areas run one-pass or even
multi-pass, depending on the overall size of the PGA memory. When a
work area cannot run optimally, one or more extra passes is performed
over the input data. This reduces the cache hit percentage in
proportion to the size of the input data and
the number of extra passes performed. this value if computed from the
"total bytes processed" and "total extra bytes read/written" statistics
available in the same view using the following formula:
total bytes processed * 100
PGA Cache Hit Ratio =
------------------------------------------------------
(total bytes processed + total extra bytes read/written)
- V$SQL_WORKAREA_HISTOGRAM (Oracle92 only)
This view shows the number of work areas executed with optimal memory
size, one- pass memory size, and multi-pass memory size since instance
start-up. Statistics in this view are subdivided into buckets that are
defined by the
optimal memory requirement of the work area. Each bucket is identified
by a range of optimal memory requirements specified by the values
of the columns LOW_OPTIMAL_SIZE and HIGH_OPTIMAL_SIZE. The
following query shows statistics for all nonempty buckets:
SELECT
low_optimal_size/1024 AS
low_kb,
(high_optimal_size+1)/1024 AS high_kb,
ROUND(100*optimal_executions/total_executions) AS "Opt_Executions",
ROUND(100*onepass_executions/total_executions) AS "OnePass_Execut",
ROUND(100*multipasses_executions/total_executions) AS "MultiPass_Execut"
FROM
v$sql_workarea_histogram
WHERE
total_executions != 0
ORDER
BY low_kb;
LOW_KB HIGH_KB Opt_Executions
OnePass_Execut MultiPass_Execut
------ ------- ------------------ ------------------
----------------------
8 16
156255
0
0
16 32
150
0
0
32 64
89
0
0
64 128
13
0
0
128 256
60
0
0
256 512
8
0
0
512 1024
657
0
0
1024 2048
551
16
0
2048 4096
538
26
0
4096 8192
243
28
0
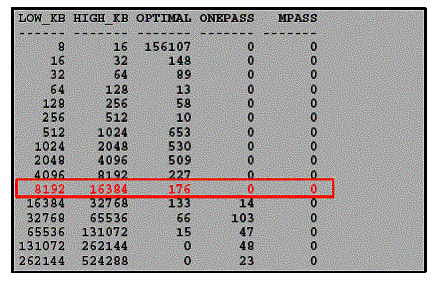
8192 16384
137
35
0
16384 32768
45
107
0
32768 65536
0
153
0
65536 131072
0
73
0
131072 262144
0
44
0
262144 524288
0
22
0
The query result shows that, in the 1024 KB to 2048 KB bucket, 551 work
areas used an optimal amount of memory, while 16 ran in one-pass mode
and none ran in multi-pass mode. It also shows that all work areas
under 1 MB were able to run in optimal mode. You can also use
V$SQL_WORKAREA_HISTOGRAM to find the percentage of
times work areas were executed in optimal, one-pass, or multi-pass mode
since start-up. Example :
SELECT optimal_count, round(optimal_count*100/total, 2) optimal_perc,
onepass_count,
round(onepass_count*100/total, 2) onepass_perc,
multipass_count,
round(multipass_count*100/total, 2) multipass_perc
FROM (SELECT
decode(sum(total_executions), 0, 1, sum(total_executions)) total,
sum(OPTIMAL_EXECUTIONS) optimal_count,
sum(ONEPASS_EXECUTIONS) onepass_count,
sum(MULTIPASSES_EXECUTIONS) multipass_count
FROM
v$sql_workarea_histogram
WHERE
low_optimal_size > 64*1024); ---- for 64 K optimal
size
3- The Third and last step is
tuning the PGA_AGGREGATE_TARGET. In
Oracle 9i Release 2 we have 2 new views that help us in this task
- V$PGA_TARGET_ADVICE
- V$PGA_TARGET_ADVICE_HISTOGRAM
By examining these two views, you will be able to determine how key PGA
statistics will be impacted if you change the value of
PGA_AGGREGATE_TARGET.
To enable automatic generation of PGA advice performance views, make
sure the following parameters are set:
- PGA_AGGREGATE_TARGET
- STATISTICS_LEVEL. Set this to TYPICAL (the default) or ALL; setting
this parameter to BASIC turns off generation of PGA performance advice
views.
The content of these PGA advice performance views is reset at instance
start-up or when PGA_AGGREGATE_TARGET is altered.
V$PGA_TARGET_ADVICE view predicts how the statistics cache hit
percentage and over allocation count in V$PGASTAT will be
impacted if you change
the value of the initialization parameter PGA_AGGREGATE_TARGET.
The following select statement can be used to find this
information
SELECT round(PGA_TARGET_FOR_ESTIMATE/1024/1024) target_mb,
ESTD_PGA_CACHE_HIT_PERCENTAGE
cache_hit_perc,
ESTD_OVERALLOC_COUNT
FROM v$pga_target_advice;
TARGET_MB CACHE_HIT_PERC ESTD_OVERALLOC_COUNT
---------- -------------- --------------------
63
23
367
125
24
30
250
30
3
375
39
0 --Lowest value that could be
assigned
500
58
0
600
59
0
700
59
0
800
60
0
900
60
0
1000
61
0
1500
67
0
2000
76
0
3000
83
0
4000
85
0
From the above results we should set the PGA_AGGREGATE_TARGET parameter
to a value where we avoid any over allocation, so the lowest
PGA_AGGREGATE_TARGET value we can set is 375 ( where
ESTD_OVERALLOC_COUNT is 0)
After eliminating over-allocations, the goal is to maximize the PGA
cache hit percentage, based on your response-time requirement and
memory constraints.
V$PGA_TARGET_ADVICE_HISTOGRAM view predicts how the statistics
displayed by the performance view V$SQL_WORKAREA_HISTOGRAM will be
impacted if you
change the value of the initialization parameter PGA_AGGREGATE_TARGET.
You can use that dynamic view to view
detailed information on the predicted number of optimal, one-pass and
multi-pass work area executions for the set of PGA_AGGREGATE_TARGET
values you use for the prediction.
Oracle Advice
Oracle9i r2 now has three predictive utilities:
These advisory utilities are extremely important for the Oracle DBA
who must adjust the sizes of the RAM areas to meet current processing
demands.
Using Data Cache Advice with v$db_cache_advice
You can have Oracle estimate what cache hit ratios would be like if
buffer caches were larger or smaller.
The following query can be used to perform the cache advice
function, once the db_cache_advice has been enabled and the database
has run long enough to give representative results
cache_advice.sql
-- ****************************************************************
-- Display cache advice. Example for 304MB Size
-- ****************************************************************
--# db_cache_advice.sql
col size_for_estimate for 999999 head 'Cache Size (MB)'
col estd_physical_read_factor for 999.90 head 'Estd Phys|Read Factor'
col estd_physical_reads for 999,999,999 head 'Estd Phys| Reads'
SELECT name, block_size, size_for_estimate, estd_physical_read_factor,
estd_physical_reads
FROM V$DB_CACHE_ADVICE
WHERE advice_status = 'ON';
The output from the script is shown below. Note that the values
range from 10 percent of the current size to double the current size of
the db_cache_size.
Estd Phys Estd Phys
NAME
BLOCK_SIZE Cache Size (MB) Read
Factor Reads
-------------------- ---------- --------------- ----------- ------------
DEFAULT
8192
112 4.03
22,276,175 10% SIZE
DEFAULT
8192
224 2.69
14,840,036
DEFAULT
8192
336 1.49
8,241,584
DEFAULT
8192
448 1.37
7,584,065
DEFAULT
8192
560 1.27
7,009,869
DEFAULT
8192
672 1.20
6,644,218
DEFAULT
8192
784 1.11
6,153,303
DEFAULT
8192
896 1.06
5,859,825
DEFAULT
8192
1008 1.03
5,684,688
DEFAULT
8192
1120 1.02
5,628,375
DEFAULT
8192
1200 1.00
5,523,760 CURRENT SIZE
DEFAULT
8192
1232
.99 5,446,959
DEFAULT
8192
1344
.97 5,383,602
DEFAULT
8192
1456
.96 5,314,650
DEFAULT
8192
1568
.95 5,271,983
DEFAULT
8192
1680
.94 5,200,616
DEFAULT
8192
1792
.92 5,082,878
DEFAULT
8192
1904
.90 4,956,648
DEFAULT
8192
2016
.88 4,863,947
DEFAULT
8192
2128
.85 4,668,080
DEFAULT
8192
2240
.68 3,763,293 2X TIMES SIZE
From the above listing we see that increasing the db_cache_size from
1200MB to 1232MB would result in approximately 100,000 less physical
reads.
Using Shared Pool Advice to size your Shared Pool properly
This advisory functionality has been extended in Oracle9i release 2 to
include a new advice called v$shared_pool_advice, and there is talk to
expending the advice facility to all SGA RAM areas in future releases
of Oracle.
The v$shared_pool_advice show
the marginal
difference in SQL parses as the shared pool changes in size from 10% of
the current value to 200% of the current value. The Oracle
documentation contains a complete description for the set-up
and use of shared pool advice, and it is very simple to configure. Once
it is installed, you can run a simple script to query the
v$shared_pool_advice view and
see the marginal changes in SQL parses
for different shared_pool sizes
-- *************************************************************
-- Display shared pool advice. Example for current Size = 96MB
-- *************************************************************
set lines 100
set pages 999
column
c1 heading 'Pool |Size(M)'
column
c2 heading 'Size|Factor'
column
c3 heading 'Est|LC(M) '
column
c4 heading 'Est LC|Mem. Obj.'
column
c5 heading 'Est|Time|Saved|(sec)'
column
c6 heading 'Est|Parse|Saved|Factor'
column c7 heading 'Est|Object
Hits' format 999,999,999
SELECT
shared_pool_size_for_estimate c1,
shared_pool_size_factor c2,
estd_lc_size
c3,
estd_lc_memory_objects
c4,
estd_lc_time_saved
c5,
estd_lc_time_saved_factor c6,
estd_lc_memory_object_hits c7
FROM
v$shared_pool_advice;
Est Est
Time Parse
Pool
Size
Est Est LC
Saved
Saved Est
Size(M)
Factor LC(M) Mem.
Obj. (sec)
Factor Object Hits
---------- ---------- ---------- ---------- ---------- ----------
------------
48
.5
48 20839
1459645 1
135,756,032
64
.6667
63 28140
1459645 1
135,756,101
80
.8333
78 35447
1459645 1
135,756,149
96
1
93 43028
1459645 1
135,756,253
112
1.1667
100 46755
1459646 1
135,756,842
128
1.3333
100 46755
1459646 1
135,756,842
144
1.5
100 46755
1459646 1
135,756,842
160
1.6667
100 46755
1459646 1
135,756,842
176
1.8333
100 46755
1459646 1
135,756,842
192
2
100 46755
1459646 1
135,756,842
Here we see the statistics for the shared pool in a range from 50% of
the current size to 200% of the current size. These statistics can give
you a great idea about the proper size for the shared_pool_size. If you
are automatic the SGA region sizes with automated "alter system"
commands, creating this output and writing a program to interpret the
results is a great way to ensure that the shared pool and library cache
always have enough RAM.
The Oracle Enterprise Manager Shared Pool Sizing Advisor guides you
in finding the optimal size for the shared pool, based on the relative
change in parse time savings. The SGA Advisor is available from
Enterprise Manager by selecting:
Databases > Database Name > Instance > Configuration >
Memory tab > Advice in the SGA section.
Using PGA Advice Utility
The new statistics to help you monitor the performance of the PGA
memory component for a particular value of PGA_AGGREGATE_TARGET are
based on two concepts: work areas groups and a computed PGA cache hit
percentage value. By grouping work areas based on their optimal memory
requirement, statistics can be collected for each group based on the
number of optimal, one-pass, and multi-pass executions for each of
these work area groups. So now you can more accurately predict
how much memory is required across the instance to maximize the number
of optimal executions.
The PGA cache hit percentage summarizes statistics on work area
executions into a single measure of PGA performance for a given value
of PGA_AGGREGATE_TARGET. The PGA cache hit percentage is derived from
the number of work areas, which run optimal, the number of passes for
the non-optimal work areas, and the sizes of the work areas.
The new
view, v$sql_workarea_histogram,
enables you to study the nature of the
work area workload over a chosen time period. The work areas are split
into 33 groups based on their optimal memory requirements. Each group
is defined by the lower bound on its optimal memory requirement,
displayed in the low_optimal_size
column, and its upper bound,
displayed in the high_optimal_size
column. For each group, the view
accumulates the number of executions using optimal, one-pass,
multi-pass memory since instance start up. These are displayed in the
optimal_executions, onepass-executions, and multipasses_executions
columns respectively. The total_executions
column contains the sum of
the other three execution counts. To determine if you have set a good
value for the PGA target size, query the v$sql_workarea_histogram view
using a statement such as the following, which converts the
low_optimal_size and high_optimal_size column values to kilobytes:
SELECT
low_optimal_size/1024 AS
low_kb,
(high_optimal_size+1)/1024 AS high_kb,
ROUND(100*optimal_executions/total_executions) AS "Opt_Executions",
ROUND(100*onepass_executions/total_executions) AS "OnePass_Execut",
ROUND(100*multipasses_executions/total_executions) AS "MultiPass_Execut"
FROM
v$sql_workarea_histogram
WHERE
total_executions != 0
ORDER
BY low_kb;
LOW_KB HIGH_KB Opt_Executions OnePass_Execut
MultiPass_Execut
---------- ---------- -------------- -------------- ----------------
8
16
100
0
0
16
32
100
0
0
32
64
100
0
0
64
128
100
0
0
128
256
100
0
0
256
512
100
0
0
512
1024
100
0
0
1024
2048
100
0
0
2048
4096
100
0
0
4096
8192
100
0
0
8192
16384
100
0
0
16384
32768
100
0
0
32768
65536
17
83
0
65536
131072
0
100
0
131072
262144
0
100
0
262144
524288
0
100
0
524288
1048576
0
100
0
Oracle9i also introduces a new parameter called
WORKAREA_SIZE_POLICY. When this parameter is set to automatic
(default), all
Oracle connections will benefit from the shared PGA memory.
When WORKAREA_SIZE_POLICY is set to manual, connections will allocate
memory according to the values for the sort_area_size parameter.
Although it would
be ideal for all work areas to execute in the optimal size, this goal
is typically achieved by over-allocating memory to the PGA. If you
graph the results of your query as a histogram, you can quickly
identify the location in the graph where work groups begin to use
one-pass, or even multi-pass, sizes
If you monitor the PGA space consumption with the various views
provided for that purpose (v$sql_workarea_histogram,
v$pgastat,
v$sql_workarea, and v$sql_workarea_active), you may decide that
you
need to reset your PGA_AGGREGATE_TARGET initialization parameter value
to make better use of your available memory. To help you determine by
what factor you should
change the parameter value, you can use two new views(v$pga_target_advice and v$pga_target_advice_histogram)
that accumulate advice statistics to help you tune the
PGA_AGGREGATE_TARGET
value.
The views are only populated if PGA_AGGREGATE_TARGET is set to a
non-zero value that enables auto management of the PGA. Also the
initialization parameter STATISTICS_LEVEL value must be set to Typical
or All. . Further, the view contents are refreshed when you shut down
the instance or when you change the value of PGA_AGGREGATE_TARGET
dynamically.
Rows in these two views correspond to setting the PGA_AGGREGATE_TARGET
from
0.125 to 8 times its current value. However, if these values are either
less
than 10MB or more than 256GB, they will not be included in the output.
To begin monitoring and tuning the PGA target size, you should issue
query against the v$pga_target_advice
view similar to:
-- ************************************************
-- Display pga target advice
-- ************************************************
column c1 heading 'Estimated|Target(M)'
column c2 heading 'Estimated|Cache Hit %'
column c3 heading 'Estimated|Over-Alloc'
column c4 heading 'Size|Factor'
SELECT ROUND(pga_target_for_estimate /(1024*1024)) c1,
pga_target_factor c4,
estd_pga_cache_hit_percentage c2,
estd_overalloc_count c3
FROM v$pga_target_advice;
Estimated
Size Estimated Estimated
Target(M) Factor
Cache Hit % Over-Alloc
---------- ------- -----------
-----------
188
.125
93 0
376
.25
95 0
752
.5
96 0
1128
.75
97 0
1504
1
98 0
1805
1.2
8 0
2106
1.4
98 0
2406
1.6
98 0
2707
1.8
98 0
3008
2
98 0
4512
3
98 0
6016
4
98 0
9024
6
98 0
12032
8
98 0
The output from the query contains estimated statistics based on the
multiples of the current
PGA_AGGREGATE_TARGET value. Assuming that your query produced the
output shown above with the PGA_AGGREGATE_TARGET value set to 1500MB,
follow these steps to evaluate the results:
Step 1: Identify the
first row with a value of zero in the "Estimated Over-Alloc" column.
The rows over this one are for PGA_AGGREGATE_TARGET values (shown in
the target_mb column) that are too small for the minimum PGA memory
needs. In this case, this is the fifth row, which contains data for the
current PGA_AGGREGATE_TARGET value, 500MB. Had the target_mb column
value in the first row with a zero estd_overallocation_count
been
larger than the current setting, you should increase the
PGA_AGGREGATE_TARGET parameter to at least this size.
Step 2: Examine the
rows with PGA values larger than the minimum required to find the first
pair of adjacent rows with values in the cache_hit_percent column that
are within a few percentage points of each other. These rows indicate
where, were you to graph the values, you would see an inflection point
(sometimes referred to as a “knee”) in the curve. The optimal value for
the PGA_AGGREGATE_TARGET parameter is at this inflection point,
represented by the target_mb
column value in the first of these two
rows. Based on the above results, you should set the
PGA_AGGREGATE_TARGET to 3000MB if you have sufficient memory. If you
have even more memory available, you should assign it to some other
use, such as one of the SGA components, rather than increasing the PGA
target size.
To refine your analysis, you can look at the contents of the v$pga_target_advice_histogram view. This view is based on the v$sql_workarea_histogram view discussed earlier and contains rows for each of the same 33 work area groups used in that view. However, as with the v$pga_target_advice view, estimated data for each value is created for 14 multiples of the current PGA_AGGREGATE_TARGET setting. Therefore the v$pga_target_advice_histogram view potentially contains 14 different sets of values for each of the 33 work area groups, giving a possible total of 462 rows.
In addition to the columns corresponding to the
work area
lower and upper bounds and execution count columns in
v$sql_workarea_histogram,
v$pga_target_advice_histogram
contains columns showing the size of
PGA_AGGREGATE_TARGET used for the estimates in the row, the factor
(multiple)
of the current PGA_AGGREGATE_TARGET size this represents, whether
advice is
currently off or on (based on the setting of the STATISTICS_LEVEL
parameter),
and the number of work areas not included in the estimates due to space
limitations in the instance. You would typically execute queries
against the v$pga_target_advice_histogram
view in the same way, and over the same
period,
as you do for your queries against v$pga_target_advice.
This way, you
can check
if a new value for PGA_AGGREGATE_TARGET that you identify by the method
just
discussed would result in reasonable optimal, one-pass, and multi-pass
mode
processing. You can select the appropriate rows by querying an
appropriate
value for the pga_target_factor
column.
The following statement would generate output based
on the
value of 3000MB (that is, 6 times the current size) identified in the
previous
step.
SELECT low_optimal_size/1024 AS
low_kb,
(high_optimal_size+1)/1024 AS high_kb,
estd_optimal_executions AS optimal,
estd_onepass_executions AS onepass,
estd_multipasses_executions AS mpass
FROM
v$pga_target_advice_histogram
WHERE pga_target_factor = 6
AND
estd_total_executions != 0
ORDER BY low_kb;
The Power of Cursor
Sharing in 9i
Oracle9i allows existing applications to improve SQL reuse by setting
the CURSOR_SHARING initialization parameter dinamically:
In an ideal world the application should be written to encourage
cursor sharing, but existing applications may gain reduced memory
usage, faster parses, and reduced latch contention when using this
option.
CASE
statements
and expressions
CASE statements and expressions are a shorthand way of representing
IF/THEN choices with multiple alternatives The CASE expression was
first added to SQL in Oracle8i. Oracle9i extends its support to PL/SQL
to allow CASE to be used as an expression or statement:
Value Match CASE Expression
The CASE expression is a more flexible version of the DECODE function.
In its simplest form it is used to return a value when a match is found:
SELECT ename, empno,
(CASE deptno
WHEN 10 THEN 'Accounting'
WHEN 20 THEN 'Research'
WHEN 30 THEN 'Sales'
WHEN 40 THEN 'Operations'
ELSE 'Unknown'
END) department
FROM emp
ORDER BY ename;
The value match CASE expression is also supported in PL/SQL:
SET SERVEROUTPUT ON
DECLARE
deptno NUMBER := 20;
dept_desc VARCHAR2(20);
BEGIN
dept_desc := CASE deptno
WHEN 10 THEN 'Accounting'
WHEN 20 THEN 'Research'
WHEN 30 THEN 'Sales'
WHEN 40 THEN 'Operations'
ELSE 'Unknown'
END;
DBMS_OUTPUT.PUT_LINE(dept_desc);
END;
/
Searched CASE Expression
A more complex version is the searched CASE expression where a
comparison expression is used to find a match. In this form the
comparison is not limited to a single column:
SELECT ename, empno,
(CASE
WHEN sal < 1000 THEN 'Low'
WHEN sal BETWEEN 1000 AND 3000 THEN
'Medium'
WHEN sal > 3000 THEN 'High'
ELSE 'N/A'
END) salary
FROM emp
ORDER BY ename;
The searched CASE expression is also supported in PL/SQL:
SET SERVEROUTPUT ON
DECLARE
sal NUMBER := 2000;
sal_desc VARCHAR2(20);
BEGIN
sal_desc := CASE
WHEN sal < 1000 THEN 'Low'
WHEN sal BETWEEN 1000 AND 3000 THEN 'Medium'
WHEN sal > 3000 THEN 'High'
ELSE 'N/A'
END;
DBMS_OUTPUT.PUT_LINE(sal_desc);
END;
/
Value Match CASE Statement
The CASE statement supported by PL/SQL is very similar to the CASE
expression. The main difference is that the statement is finished with
an END CASE statement rather than just END. The PL/SQL statements
are essentially an alternative to lists of IF .. THEN .. ELSIF
statements:
SET SERVEROUTPUT ON
BEGIN
FOR cur_rec IN (SELECT ename, empno, deptno FROM emp ORDER BY
ename) LOOP
DBMS_OUTPUT.PUT(cur_rec.ename || ' : ' ||
cur_rec.empno || ' : ');
CASE cur_rec.deptno
WHEN 10 THEN
DBMS_OUTPUT.PUT_LINE('Accounting');
WHEN 20 THEN
DBMS_OUTPUT.PUT_LINE('Research');
WHEN 30 THEN
DBMS_OUTPUT.PUT_LINE('Sales');
WHEN 40 THEN
DBMS_OUTPUT.PUT_LINE('Operations');
ELSE
DBMS_OUTPUT.PUT_LINE('Unknown');
END CASE;
END LOOP;
END;
/
Searched CASE Statement
As with its expression counterpart, the searched CASE statement allows
multiple comparisons using mulitple variables:
SET SERVEROUTPUT ON
BEGIN
FOR cur_rec IN (SELECT ename, empno, sal FROM emp ORDER BY
ename) LOOP
DBMS_OUTPUT.PUT(cur_rec.ename || ' : ' ||
cur_rec.empno || ' : ');
CASE
WHEN
cur_rec.sal < 1000 THEN
DBMS_OUTPUT.PUT_LINE('Low');
WHEN
cur_rec.sal BETWEEN 1000 AND 3000 THEN
DBMS_OUTPUT.PUT_LINE('Medium');
WHEN
cur_rec.sal > 3000 THEN
DBMS_OUTPUT.PUT_LINE('High');
ELSE
DBMS_OUTPUT.PUT_LINE('Unknown');
END CASE;
END LOOP;
END;
/
New Date/Time Types
The new datatype TIMESTAMP records time values including fractional
seconds. New datatypes TIMESTAMP WITH TIME ZONE and TIMESTAMP WITH
LOCAL TIME ZONE allow you to adjust date and time values to account for
time zone differences. You can specify whether the time zone observes
daylight savings time, to account for anomalies when clocks shift
forward or backward. New datatypes INTERVAL DAY TO SECOND and INTERVAL
YEAR TO MONTH represent differences between two date and time values,
simplifying date arithmetic. Examples:
TIMESTAMP (fractional_seconds_precision)
Year, month, and day values of date, as well as hour, minute, and
second values of time, where fractional_seconds_precision is the number
of digits in the fractional part of the SECOND datetime field. Accepted
values of fractional_seconds_precision are 0 to 9. The default is 6.
TIMESTAMP (fractional_seconds_precision) WITH TIME ZONE
All values of TIMESTAMP as well as time zone displacement value, where
fractional_seconds_precision is the number of digits in the fractional
part of the SECOND datetime field. Accepted values are 0 to 9. The
default is 6.
TIMESTAMP (fractional_seconds_precision) WITH LOCAL TIME ZONE
All values of TIMESTAMP WITH TIME ZONE, with the following exceptions:
Data is normalized to the database time zone when it is stored in the
database.
When the data is retrieved, users see the data in the session time zone.
INTERVAL YEAR (year_precision) TO MONTH
Stores a period of time in years and months, where year_precision is
the number of digits in the YEAR datetime field. Accepted values are 0
to 9. The default is 2.
INTERVAL DAY (day_precision) TO SECOND (fractional_seconds_precision)
Stores a period of time in days, hours, minutes, and seconds, where
day_precision is the maximum number of digits in the DAY datetime
field. Accepted values are 0 to 9. The default is 2.
fractional_seconds_precision is the number of digits in the fractional
part of the SECOND field. Accepted values are 0 to 9. The default is 6.
SELECT SYSDATE,
TO_CHAR(SYSDATE,
'MM/DD/YYYY HH24:MI:SS')
sysdate_prior9i,
TO_CHAR(SYSDATE,
'MM/DD/YYYY
HH24:MI:SS.SSSSSSSSSSSS') sysdate_9i
FROM DUAL;
SYSDATE SYSDATE_PRIOR9I
SYSDATE_9I
--------- ------------------- --------------------------------
21-MAY-03 05/21/2003 12:23:01 05/21/2003 12:23:01.445814458101
Oracle9i DataGuard (previously
called Standby)
DataGuard
maintains one or more synchronized copies of a customers production
data.
An Oracle9i DataGuard configuration consists of a collection of
loosely
connected systems, that combine the primary database and physical
standby
databases into a single, easily managed disaster recovery solution.
Often,
the sites in a DataGuard configuration are dispersed geographically
and
connected by Oracle*Net. As the primary database is modified, the
physical
standby database is sent log information generated by changes made to
the primary database. These changes are applied to the standby
database, which runs in managed recovery mode. While the primary
database is open and active, a standby database is either performing a
recovery or open for reporting access. Should something go wrong with
primary, a standby database can be activated to replace it. A new
background process DMON monitors the primary and standby
databases and can be configured either by OEM using the new DataGuard
Manager tool or through the command line using the new DGMGRL utility.
DMON processes run on both primary and standby servers. There are 2 new
terms of reference to learn:
alter database add standby logfile group 1 '/u01/oradata/SID1/SID1_g1.rdo' size 80M;
Oracle standby server can now run in 4
data protection modes as follows:
| Guaranteed
Protection (no data loss mode) (no data divergence) |
The
strictest mode possible. Primary node's LGWR transmits the redo stream synchronously
to the standby nodes. Standby node must acknowledge, or affirm receipt
of the transaction before it can be committed on Primary. The primary
node will shutdown if LGWR cannot transmit. Performance penalties are
severe.
In addtion, the following command is required to be issued on Primary to differentiate this mode from Instant Protection Mode:
|
| Instant Protection (no data loss mode) |
Behaves
exactly the same as Guaranteed Protection with the exception that data
divergence is permitted. ie. primary operation can continue and will
therefore diverge if the links to the standbys are broken. Performance
penalties are still severe. Switchover to standby is not
permitted until contact is re-established and synchronised.
|
| Rapid Protection (no data loss mode) |
Primary
node's LGWR transmits the redo stream asynchronously to the
standby nodes. No need to wait for acknowledgement from standby node
that the transaction has been received (noaffirm). Performance
penalties are not so severe.
|
| Delayed Protection | ARCH
transmits archived redo logs to standby node(s) in the same way as it
did in Oracle8i. |
The last mode there,
delayed protection is exactly how the old form of standby database
behaved. It cannot guarantee no data loss because ARCH is responsible
for transmitting redo logs that already contain committed transactions.
Database switchover
On Primary (primary becomes new standby): Oracle9i LogMiner
Have you ever wondered who was responsible for changing the salary
table to zero? Would it be useful
to locate the offending SQL statement and be provided with SQL required
to correct it? This is a great tool for undoing a single erroneous
transaction without having to go through a database restore.
Every change made to an Oracle database by default generates undo and
redo information which is accumulated in Oracle redo log files.
Oracle9i LogMiner is an integrated feature of the Oracle9i that
provides DBA's and auditors with the infrastructure required for
relational access to Oracle's redo stream. Some significant
enhancements to LogMiner for Oracle9i generated log
files include:
The online data dictionary can be extracted into the redo log
stream. This enables off-line analysis and provides a snapshot of the
data dictionary that matches the database objects in logs created at
that time. When mining logs in the same database that generated it, the
user
can choose to use the online data dictionary for SQL reconstruction and
internal identifier to name mapping which would otherwise be a manual
process.
The user can group DML statements into transactions with a
COMMITTED_DATA_ONLY option which directs LogMiner to group DML
statements into complete transactions. Only committed transactions will
be returned in the commit SCN order. When the DDL_DICT_TRACKING option
is enabled and LogMiner is run in the context of an open database, it
will automatically apply DDL statements executed in the original redo
stream to its internal dictionary. This enables correct reconstruction
of correct SQL statements on tables whose definition has been altered
or were missing when the original dictionary dump was captured.
LogMiner automatically versions the metadata kept in the database.
New DDL statements have been added to Oracle's vocabulary to allow for
logging of additional column values in case of updates. The extra
information can be used either to identify the updated row logically or
to capture a before-row image. This allows a DBA or auditor to use the
additional column information to construct more complete statements to
undo changes or to create SQL statements for applying to a different
databases.
A powerful new capability allows for queries that can filter out rows
based on actual data values of the columns updated. For instance it is
possible to write a query for a postal database that identifies all
lottery winners who moved to 90210 after making it big in Redwood
Shores.
LogMiner improves data availability by providing a window into all
changes made to a database. It enables auditing of database changes and
reduces the time and effort needed for data recovery.
Oracle9i
Flashback Query
Oracle9i's flashback query provides users with the capability of
viewing data in the past. In the first release of Oracle9i, the only
method available to invoke
flashback query was to execute the system supplied package
DBMS_FLASHBACK. Here is an example that goes back five minutes:
EXECUTE
DBMS_FLASHBACK.ENABLE_AT_TIME (SYSDATE -
(5/(24*60)));
The above statement sends the session back in time for the duration of
that session or until the EXECUTE DBMS_FLASHBACK.DISABLE is executed.
Standard date and time SQL functions are used to determine the time in
the past the data will be retrieved from. The drawback was that data
could not be updated during a flashback
query enabled session. Savvy programmers were able to save historical
data by placing it into a cursor and then dumping the contents of the
cursor into a worktable after the FLASHBACK.DISABLE procedure was
executed.
In Oracle9i Release 2, the AS OF timestamp clause has been added to the
SELECT statement to enable flashback query on a specific table or set
of tables. Developers are able to specify the AS OF clause for a
single-table, multiple-tables (joins) as well as specify different
times for different tables. The AS OF timestamp clause can also be used
inside INSERT or CREATE TABLE AS SELECT statements. Here is an example
of a SELECT statement using the AS OF timestamp clause:
UPDATE
emp.employee_payroll_table SET
emp_salary =
(SELECT emp_salary
FROM emp.employee_payroll_table
AS OF TIMESTAMP (SYSTIMESTAMP - INTERVAL '1' DAY)
WHERE emp_last_name = 'FOOT')
WHERE
emp_last_name = 'FOOT';
The statement above uses the SYSTIMESTAMP value with an INTERVAL
function to update the emp.employee_payroll_table with data that is 24
hours old.
The AS OF timestamp clause (and its DBMS_FLASHBACK.ENABLE_AT_TIME
counterpart) maps the timestamp value to a SCN value. Oracle records
the SCN-TIMESTAMP mapping at five-minute intervals. This means that the
time you may actually retrieve the data from could be rounded down by
up to five minutes. For example, you could access a table using a
timestamp
that is a few minutes after the table is created and receive an error
because flashback query used a SCN value that is lower than the actual
time when the table was created.
Using Flashback Query
Before Flashback Query functionality can be used by ordinary users,
some actions are required from the database administrators:
Once these actions have been performed, users can access the old image of data that was modified by a DML statement. Before this data can be accessed, users have to call the package DBMS_FLASHBACK.ENABLE_AT_TIME(param) or DBMS_FLASHBACK.ENABLE_AT_SYSTEM_CHANGE_NUMBER(param) to enable flashback query. Once flashback query is enabled, all queries performed will apply to the state of the database at the time specified by the input parameter to the package. After all the required queries have been performed on the past data, Flashback Query feature is disabled by calling package DBMS_FLASHBACK.DISABLE. From this point on all queries will access the current data in the database.
Flashback Query Applications
The Flashback Query feature can be used for:
These applications of Flashback Query liberate database
administrators from the task of correcting user errors and empower the
users to recover from their errors by giving access to previously
unavailable data through a simple, completely non-intrusive interface.
This not only enhances database
administrator and user productivity but also reduces overall database
administration costs.
Reorganize
Tables and Indexes Online. Rename Columns and Constraints
One of the most exciting new online features in Oracle9i is the online
table redefinition feature using the DBMS_REDEFINITION package.
The new feature allows DBA's to redefine tables online:
Renaming Columns and Constraints
In addition to renaming tables and indexes Oracle9i Release 2 allows
the renaming of columns and constraints on tables. In this example I
have a table and the following PK:
SQL> DESC test1
Name
Null? Type
-------------------- -------- --------------------
COL1
NOT NULL NUMBER(10)
COL2
NOT NULL VARCHAR2(50)
SQL> SELECT constraint_name FROM
user_constraints
3 WHERE table_name
= 'TEST1'
4 AND constraint_type = 'P';
CONSTRAINT_NAME
------------------------------
TEST1_PK
SQL> SELECT index_name, column_name FROM
user_ind_columns
3 WHERE table_name = 'TEST1';
INDEX_NAME
COLUMN_NAME
-------------------- --------------------
TEST1_PK
COL1
Redefine
a Table OnLine
When a table is redefined online, it is accessible by all read and
write operations during the redefinition process. Administrators have
control over when to switch from the original to the newly redefined
table. The switch process is very brief and is independent of the size
of the table or the complexity of the redefinition. The redefinition
process effectively creates a new table and improves its data block
layout efficiency.
The new Oracle9i online table redefinition feature improves data
availability, database performance, response time and disk space
utilization.
Additionally, during an application upgrade, administrators can start
the redefinition process, then periodically synchronize the new image
of the table so that the new image of the table includes the latest
changes to the original table. This reduces the amount of time to
complete the final redefinition step. Administrators can also validate
and use the data in the new image of the table before completing the
redefinition process. This is a very useful feature for administrators,
who must ensure that the upgrade process goes smoothly. Prior to executing
this package, the EXECUTE privilege
must be granted on the DBMS_REDEFINITION package or the
EXECUTE_CATALOG_ROLE
must be granted to the schema.
There are several restrictions that you should recognize before
attempting to redefine a table online:
There are five basic steps to redefine a table:
1. Create a new image of the table with all of the desired attributes.
2. Start the redefinition process.
3. Create any triggers, indexes, grants and constraints on the new
image of the table.
4. Optionally synchronize and validate data in the new image of the
table periodically.
5. Complete the redefinition of the table
Creation Script:
dbmshord.sql
Called By:
catproc.sql script
Located in :
$ORACLE_HOME/rdbms/admin
Directory
Grant Privilege on Package to Schema: EXECUTE
Privilege or EXECUTE_CATALOG_ROLE
DBMS_REDEFINITION Package Example
Create Employee Table
CREATE TABLE s_employee
(employee_id
NUMBER(7) CONSTRAINT
s_employee_id_nn NOT
NULL,
employee_last_name VARCHAR2(25) CONSTRAINT
s_employee_last_name_nn NOT NULL,
employee_first_name VARCHAR2(25),
userid
VARCHAR2(8),
start_date
DATE,
comments
VARCHAR2(255),
manager_id
NUMBER(7),
title
VARCHAR2(25),
department_id NUMBER(7),
salary
NUMBER(11, 2),
commission_pct NUMBER(4, 2),
CONSTRAINT s_employee_id_pk PRIMARY KEY (employee_id),
CONSTRAINT s_employee_userid_uk UNIQUE (userid),
CONSTRAINT s_employee_commission_pct_ck
CHECK (commission_pct IN (10, 12.5, 15, 17.5,
20)));
25 Records Inserted into Employee Table
Assume the Following Desired:
- Remove COMMENTS Column
- Add FULL_NAME Column
- Change DEPARTMENT_ID Column Name to DEPT_ID
- Increase Salary of All Employees by 50%
Step 1: Ensure Table Can be Redefined
Execute CAN_REDEF_TABLE Procedure, If Execution Succeeds without Error,
Then can Redefine
EXECUTE
dbms_redefinition.can_redef_table('plsql_user','s_employee')
Success: s_employee Table Can be Redefined
Illustration of a Table that Cannot Be Redefined
CREATE TABLE temp (temp VARCHAR2(10));
EXECUTE dbms_redefinition.can_redef_table('plsql_user','temp')
begin dbms_redefinition.can_redef_table('plsql_user','temp'); end;
*
ERROR at line 1:
ORA-12089: cannot online redefine table "PLSQL_USER"."TEMP" with no
primary key
ORA-06512: at "SYS.DBMS_REDEFINITION", line 8
ORA-06512: at "SYS.DBMS_REDEFINITION", line 236
ORA-06512: at line 1
Set of Criteria Checked to Ensure Redefinition Allowed
Step 2: Create Temporary Table with New Structure
CREATE TABLE temp_s_employee
(employee_id
NUMBER(7) CONSTRAINT s_employee_id_nn2 NOT NULL,
employee_last_name VARCHAR2(25) CONSTRAINT
s_employee_last_name_nn2 NOT NULL,
employee_first_name VARCHAR2(25),
employee_full_name VARCHAR2(51),
userid
VARCHAR2(8),
start_date
DATE,
manager_id
NUMBER(7),
title
VARCHAR2(25),
dept_id
NUMBER(7),
salary
NUMBER(11, 2),
commission_pct NUMBER(4, 2),
CONSTRAINT s_employee_id_pk2 PRIMARY KEY (employee_id),
CONSTRAINT s_employee_userid_uk2 UNIQUE (userid),
CONSTRAINT s_employee_commission_pct_ck2
CHECK (commission_pct IN (10, 12.5, 15, 17.5,
20)));
Step 3: Start the Redefinition Process
Execute START_REDEF_TABLE Procedure, map Existing Columns to Temporary
Table Columns
BEGIN
dbms_redefinition.start_redef_table('plsql_user',
's_employee','temp_s_employee',
'employee_id employee_id,
employee_last_name employee_last_name,
employee_first_name employee_first_name,
employee_first_name||'' ''||employee_last_name
employee_full_name,
userid userid,
start_date start_date,
manager_id manager_id,
title title,
department_id dept_id,
salary * 1.5 salary,
commission_pct commission_pct');
END;
/
Step 4: Start the Redefinition Process
If Singe Quote Desired, Use 2 Single Quotes (Line 7)
Standard SELECT Capabilities Valid in Column Mapping
Once Step 3 Complete, 25 Records Inserted into Temporary Table
Step 5: Complete the Redefinition Process
Execute FINISH_REDEF_TABLE Procedure
Synchronizes the Redefinition and Applies the Temporary Architecture
and Contents to the Existing Table. Prior to Executing the
FINISH_REDEF_TABLE Procedure, Option to Execute SYNC_INTERIM_TABLE
Procedure to Synchronize Table Contents and Reduce the Completion
Process Time
DBMS_REDEFINITION Package Example
BEGIN
dbms_redefinition.sync_interim_table('plsql_user',
's_employee','temp_s_employee');
END;
/
BEGIN
dbms_redefinition.finish_redef_table('plsql_user',
's_employee','temp_s_employee');
END;
/
DESC s_employee
Name
Null? Type
------------------------------- -------- ----
EMPLOYEE_ID
NOT NULL NUMBER(7)
EMPLOYEE_LAST_NAME
NOT NULL VARCHAR2(25)
EMPLOYEE_FIRST_NAME
VARCHAR2(25)
EMPLOYEE_FULL_NAME
VARCHAR2(51)
USERID
VARCHAR2(8)
START_DATE
DATE
MANAGER_ID
NUMBER(7)
TITLE
VARCHAR2(25)
DEPT_ID
NUMBER(7)
SALARY
NUMBER(11,2)
COMMISSION_PCT
NUMBER(4,2)
SELECT * FROM s_employee WHERE employee_id = 1;
EMP_ID EMP_L_NAME EMP_F_NAME EMP_FULL_NAME USERID
------ ---------- ---------- ---------------- --------
1 VELASQUEZ
CARMEN CARMEN VELASQUEZ cvelasqu
START_DATE MANAGER_ID TITLE DEPT_ID SALARY
COMMISSION_PCT
---------- ---------- --------- ------- ------ --------------
03-MAR-90
PRESIDENT 50 3750
Step 6: Drop the Temporary Table
Aborting a Redefinition
When you invoke START_REDEF_TABLE, there's the chance that something
might go wrong. You might, for example, run out of tablespace while
copying data from the original table to the target. Or you might
suddenly realize that you've created your target table incorrectly.
Either way, you'll need to abort the redefinition process and start
over. To abort a redefinition, invoke the ABORT_REDEF_TABLE procedure.
The following aborts the redefinition for my example:
BEGIN
DBMS_REDEFINITION.ABORT_REDEF_TABLE
('gennick','gnis','gnis_redef');
END;
/
Be sure to call ABORT_REDEF_TABLE in the event that START_REDEF_TABLE
fails with an error. The abort procedure removes the materialized view
and materialized view log created by START_REDEF_ TABLE and does other
needed cleanup. You can also call ABORT_REDEF_TABLE anytime before
invoking FINISH_REDEF_ TABLE if you simply change your mind about the
redefinition.
There are two things ABORT_REDEF_TABLE does not do: It does not delete
any of the data inserted into the target table by START_REDEF_TABLE,
and it does not drop the target table. When you abort a redefinition,
you'll need to deal with the target table and any data it
contains.
Database
Resource Manager
One of the most critical challenges for database administrators is to
maintain a given performance level with limited hardware resources.
Traditionally, it has been up to the operating system (OS) to regulate
the resource management among the various applications running on a
system including Oracle databases. However, since the OS can not
distinguish one Oracle user/session from another, it can not perform
any resource management activities among different users or
applications sharing a database.
The Database Resource Manager, introduced in Oracle8i, provides database administrators the capability to distribute system resources among various users and applications sharing a database in a manner consistent with business priorities. Using this tool, a DBAs can divide the various users and applications using a database into different resource consumer groups and allocate CPU resources to each one of them in terms of percentages by creating a resource plan.
A Resource Plan can help ensure that system resources are first made available to certain critical business operations before other users or applications can use them. It is also possible to cap the resource consumption of a group of users or an application so that the critical operations are not starved for resources when they need them. The ability to allocate resources at multiple levels and create nested resource plans provides database administrators with an extremely powerful and flexible mechanism to specify how the unused resources should be divided among different resource consumer groups.
Oracle9i features a significantly enhanced Database Resource Manager with new capabilities to enable automatic and proactive management of database workload so as to ensure compliance with service level objectives. Using Oracle9i Database Resource Manager, a database administrator can
These capabilities of the Database Resource Manager allow DBAs to
create resource management policies to guarantee measured database
services to enterprise applications and users. Oracle9i Database
Resource Manager makes it extremely easy to deliver predictable service
levels with little intervention while providing a high degree of
flexibility to support changing business needs.
Resumable Statements
Large operations such as batch updates or data loads can encounter out
of space failures after executing for a long period of time, sometimes
when they are just about to complete. Under such a circumstance,
database administrators are left with no other choice but to re-execute
the failed job under a close supervision in order to ensure its
successful completion.
Oracle9i introduces a new feature called "Resumable Space Allocation"
which allows users to avoid such failures by instructing the database
to suspend any operations that encounter an out of space error rather
than aborting them. This provides an opportunity for users or
administrators to fix the problem that caused the error while the
operation is suspended and automatically resume its execution once the
problem has been resolved. By allowing administrators to intervene in
the middle of the execution of an operation, Resumable Space Allocation
obviates the need of dividing a large job into smaller sub-jobs in
order to limit the impact of any failure. Additionally, it will also
enable application developers to write applications without worrying
about running into space related errors.
A statement can be executed in the "resumable" mode when explicitly specified by using the ALTER SESSION ENABLE RESUMABLE command. Virtually any kind of operation be it a PL/SQL stored procedure, Java stored procedure, queries, SQL*loader, export/import, DML (such as UPDATE, INSERT) and DDL (CREATE TABLE AS SELECT¿., CREATE INDEX , INDEX REBUILD, ALTER TABLE MOVE PARTITION etc..) can all be run as a "resumable" statement. A "resumable" operation will be suspended whenever it encounters one of the following types of failures:
Once the operation is suspended, a warning to that effect will be written in the alert log file. A trigger can also be used on a new event called "AFTER SUSPEND" either to generate a notification or take corrective actions. Any transactions executed within the trigger will automatically be executed as an autonomous transaction and can therefore include operations such as inserts into a user table for error logging purposes. Users may also access the error data using the "DBMS_RESUMABLE" package and the DBA(USER)_RESUMABLE view.
When the problem that caused the failure is fixed, the suspended statement automatically resumes execution. If the operation encounters a transient problem which may disappear automatically after some time such as temporary tablespace shortage, no administrator intervention may be required to resume its execution. A "resumable" query running out of temporary space may resume automatically with absolutely no user or administrator intervention once other active queries complete. A "resumable" operation may be suspended and resumed multiple times during its execution.
Every "resumable" operation has a time-out period associated with
it. The default value of time-out period is 2 hours but can be set to
any value using the ALTER SESSION ENABLE RESUMABLE TIMEOUT <time-out
period in seconds> command. A suspended operation will automatically
be aborted if the error condition is not fixed within "time-out"
period. An administrator can abort a suspended operation any time using
DBMS_RESUMABLE.ABORT() procedure.
When you suspend a transaction, a log is maintained in the alert log.
We can use a view, DBA_RESUMABLE, through which we can monitor the
progress of the statement and indicate whether the statement is
currently executing or suspended. Example:
In the example below we will do the following;
1. Create a Tablespace with a small size
(1MB) datafile
CREATE TABLESPACE TBS_RESUME DATAFILE
'E:\ORACLE9I\EXAMPLES\RESUME\TEST_RESUME01.DBF' SIZE 1M;
2. Create a table which will use the
tablespace
CREATE TABLE TAB_RESUME TABLESPACE TBS_RESUME AS
SELECT * FROM EMP_EXT WHERE (1=2);
3. Switch on Resumable mode with Timeout
as 1 minute
ALTER SESSION ENABLE RESUMABLE TIMEOUT 60 NAME 'PROBLEM WITH
TABLESPACE: TBS_RESUME';
4. Insert very large data in the
table. The data to be inserted should be greater than 1MB
INSERT INTO TAB_RESUME (SELECT * FROM EMP_EXT);
Since the data is greater than 1MB the process hangs.
5. Check the alert log for error. Do
not fix the error
Error as in alert.log
statement in resumable session
'PROBLEM WITH TABLESPACE: TBS_RESUME' was suspended due to
ORA-01653: unable to extend table SJM.TAB_RESUME by 32 in tablespace
TBS_RESUME
Please note that, the alert log displays the text, PROBLEM WITH
TABLESPACE: TBS_RESUME, which we specified alongside the NAME clause
when firing the ALTER SESSION command
Error as displayed on SQL Prompt after timeout period
SQL> INSERT INTO TAB_RESUME ( SELECT * FROM EMP_EXT );
INSERT INTO TAB_RESUME ( SELECT * FROM EMP_EXT )
*
ERROR at line 1:
ORA-30032: the suspended (resumable) statement has timed out
ORA-01653: unable to extend table SJM.TAB_RESUME by 32 in tablespace
TBS_RESUME
Since the TIMEOUT specified is 60 seconds we do not get enough time to
fix the problem.
6. Switch on Resumable mode with
Timeout as 60 minutes
ALTER SESSION ENABLE RESUMABLE TIMEOUT 3600 NAME
'PROBLEM WITH TABLESPACE: TBS_RESUME'
With 60 minutes, we will have lots of time to fix the problem so that
the transaction can be resumed.
7. Insert very large data in the
table. The data to be inserted should be greater than 1MB
INSERT INTO TAB_RESUME (SELECT * FROM EMP_EXT);
8. Check the alert log for error. Fix
the error by adding one datafile
Error as in alert.log
statement in resumable session
'PROBLEM WITH TABLESPACE: TBS_RESUME' was suspended due to
ORA-01653: unable to extend table SJM.TAB_RESUME by 32 in
tablespace TBS_RESUME
To fix the problem, add one more datafile to the tablespace. Start
another sqlplus session and issue the following command
ALTER TABLESPACE TBS_RESUME ADD DATAFILE
'E:\ORACLE9I\EXAMPLES\RESUME\TEST_RESUME02.DBF' SIZE 10M;
9. Check the statement status in the
first sqlplus session.
SQL> INSERT INTO TAB_RESUME (SELECT * FROM EMP_EXT);
56644 rows created.
The statement does not hang. It completes the transaction and comes
back on the SQL prompt
10. Check alert.log for any messages.
The alert log shows that the statement resumed after the problem was
fixed.
statement in resumable session 'PROBLEM WITH TABLESPACE: TAB_RESUME'
was resumed
11. Check dba_resumable view
SQL> SELECT SQL_TEXT, START_TIME,RESUME_TIME FROM DBA_RESUMABLE;
SQL_TEXT
START_TIME RESUME_TIME
------------------------------------------
---------------------- -----------------
INSERT INTO TAB_RESUME (SELECT * FROM EMP_EXT)
01/30/03 10:24:33 01/30/03 10:28:01
Undo Tablespaces or SMU
(System Managed Undo)
Oracle Database keeps records of actions of transactions, before they
are committed and Oracle needs this information to rollback or Undo the
Changes to the database. These records in Oracle are called Rollback or
Undo Records. Until Oracle 8i, Oracle uses Rollback Segments to manage
the Undo Data.
Starting with 9i, the old rollback segment way is referred to as Manual
Undo Management Mode and the new Undo Tablespaces method as the
Automatic Undo Management Mode. Although both rollback Segments and
Undo Tablespaces are supported in Oracle 9i, both modes cannot be used.
System Rollback segment exists in both modes. Since we are all familiar
with the manual mode, lets look at the features of the Automatic Undo
Management (Undo Tablespaces )
Oracle9i Enterprise Manager allows you to create a new UNDO tablespace
for a database. In addition, under instance management, a new
"Undo" tab displays the name of the active undo tablespace and the
current undo retention time. Administrators can modify the retention
time based on their largest transaction time and immediately view the
space required for the undo tablespace. Undo generation rates are
calculated based on statistics available for undo space consumption for
the current instance. The "Undo Space Estimate" graph indicates
the space requirements
based on a maximum undo generation rate and on an average undo
generation
rate and relates them to the current Undo setting.
Init.ora Parameters for Automatic Undo Management
UNDO_MANAGEMENT : This parameter sets the mode in which oracle manages
the Undo Information. The default value for this parameter is MANUAL so
that all your old
init.ora files can be used without any changes. To set the database in
an automated mode, set this value to AUTO. (UNDO_MANAGEMENT = AUTO)
UNDO_TABLESPACE : This parameter defines the tablespaces that are to be used as Undo Tablespaces. If no value is specified Oracle grabs the first available Undo Tablespace or if there are none present, Oracle will use the system rollback segment to startup. This value is dynamic and can be changed online (UNDO_TABLESPACE = UNDO)
UNDO_RETENTION : This value specifies the amount of time, Undo is kept in the tablespace. This applies to both committed and uncommitted transactions since the introduction of FlashBack Query feature in Oracle needs this information to create a read consistent copy of the data in the past. Default value is 900 Secs (UNDO_RETENTION = 500)
UNDO_SUPRESS_ERRORS : This is a good thing to know about in case your code has the alter transaction commands that perform manual undo management operations. Set this to true to suppress the errors generated when manual management SQL operations are issued in an automated management mode.
Creating and Managing Undo Tablespaces :
Undo tablespaces use syntax that is similar to regular tablespaces
except that they use the keyword UNDO. These tablespaces can be created
during the database creation time or can be added to an existing
database using the create UNDO Tablespace command
Create DATABASE uday controlfile
...........
UNDO Tablespace undo_tbs0 datafile '/vol1/data/uday/undotbs0.dbf' ...
Create UNDO Tablespace undo_tbs1
datafile '/vol1/data/uday/undotbs1.dbf' size 25m autoextend on;
All operations like Renaming a data file, Adding a datafile, Online
/Offline Swith or Start Backup / End Backup Switch can be made using
the regular alter tablespace command. All other operations are managed
by Oracle in the automated management mode.
Shrinking the Tablespace
alter system checkpoint;
create undo tablespace UNDOTMEP datafile
'C:\ORACLE\ORA92\DIE\UNDOTMEP.DBF' size 100M AUTOEXTEND OFF;
alter system set undo_tablespace =UNDOTMEP scope=both;
drop tablespace UNDOTBS1 INCLUDING CONTENTS AND DATAFILES;
alter system checkpoint;
-- Delete the database file for that tablespace if needed
create undo tablespace UNDOTBS1 datafile
'C:\ORACLE\ORA92\DIE\UNDOTBS1.DBF' size 600M AUTOEXTEND ON NEXT 5 M
MAXSIZE 1000M;
alter system set undo_tablespace =UNDOTBS1 scope=both;
drop tablespace UNDOTMEP INCLUDING CONTENTS AND DATAFILES;
alter system checkpoint;
-- Delete the database file for that tablespace if needed
Monitoring :
v$UNDOSTAT : This view contains statistics for monitoring the effects
of transaction execution on Undo Space in the current instance. These
are available for space usage, transaction concurrency and length of
query operations. This view contains information that spans over a 24
hour period and each row in this view contains data for a 10 minute
interval specified by the BEGIN_TIME and END_TIME.
If you decide to use RESUMABLE OPERATIONS (avisa de errores x espacio),
you can wait for the event to be on the alert log file or I can query
the DBA_RESUMABLE and USER_RESUMABLE views.
Defining Size
When you are working with UNDO (instead of ROLLBACK), there are two
important things to consider:
There are two ways to proceed to optimize your resources.
You can choose to allocate a specific size for the UNDO tablespace and
then set the UNDO_RETENTION parameter to an optimal value according to
the UNDO size and the database activity. If your disk space is limited
and you do not want to allocate more space than necessary to the UNDO
tablespace, this is the way to proceed. If you are not limited by
disk space, then it would be better to choose the UNDO_RETENTION time
that is best for you (for FLASHBACK, etc.). Allocate the appropriate
size to the UNDO tablespace according to the database activity.
This tip help you get the information you need whatever the method you
choose. It was tested on Oracle9i (9.2.0.4, 9.2.0.5).
set serverout on size 1000000
set feedback off
set heading off
set lines 132
declare
cursor get_undo_stat is
select d.undo_size/(1024*1024) "C1",
substr(e.value,1,25) "C2",
(to_number(e.value) * to_number(f.value) * g.undo_block_per_sec) /
(1024*1024) "C3",
round((d.undo_size / (to_number(f.value) *
g.undo_block_per_sec)))
"C4"
from (select sum(a.bytes) undo_size
from v$datafile a,
v$tablespace b,
dba_tablespaces c
where c.contents = 'UNDO'
and c.status = 'ONLINE'
and b.name = c.tablespace_name
and a.ts# = b.ts#) d,
v$parameter e,
v$parameter f,
(select max(undoblks/((end_time-begin_time)*3600*24)) undo_block_per_sec from
v$undostat) g
where e.name = 'undo_retention'
and f.name = 'db_block_size';
begin
dbms_output.put_line(chr(10)||chr(10)||chr(10)||chr(10)
|| 'To optimize UNDO you have two choices :');
dbms_output.put_line('===================================================='
|| chr(10));
for rec1 in get_undo_stat
loop
dbms_output.put_line('A) Adjust UNDO tablespace size according to
UNDO_RETENTION :' || chr(10));
dbms_output.put_line(rpad('ACTUAL UNDO SIZE ',60,'.')|| ' : ' ||
TO_CHAR(rec1.c1,'999999') || ' MB');
dbms_output.put_line(rpad('OPTIMAL UNDO SIZE WITH ACTUAL UNDO_RETENTION
(' || ltrim(TO_CHAR(rec1.c2/60,'999999')) || ' MINUTES) ',60,'.') || '
: ' || TO_CHAR(rec1.c3,'999999') || ' MB');
dbms_output.put_line(chr(10));
dbms_output.put_line(chr(10));
dbms_output.put_line('B) Adjust UNDO_RETENTION according to UNDO
tablespace size :' || chr(10));
dbms_output.put_line(rpad('ACTUAL UNDO RETENTION ',60,'.') || ' : ' ||
TO_CHAR(rec1.c2/60,'999999') || ' MINUTES');
dbms_output.put_line(rpad('OPTIMAL UNDO RETENTION WITH ACTUAL UNDO SIZE
(' || ltrim(TO_CHAR(rec1.c1,'999999'))
|| ' MEGS) ',60,'.') || ' : ' || TO_CHAR(rec1.c4/60,'999999') || '
MINUTES');
end loop;
dbms_output.put_line(chr(10)||chr(10));
end;
/
New
Parameters for Buffer Cache Sizing and Multiple DB_BLOCK_SIZE
The Buffer Cache consists of independent sub-caches for buffer pools
and for multiple block sizes. The parameter db_block_size determines
the primary block size.
Databases can now have multiple block sizes.
The following are the Size parameters which define the sizes of the
caches for buffers for the primary block size:
DB_CACHE_SIZE
DB_KEEP_CACHE_SIZE
DB_RECYCLE_CACHE_SIZE
The db_keep_cache_size and db_recycle_cache_size are independent of
db_cache_size.
These parameters are specified in units of memory rather than in units
of buffers (as is the case in Oracle8i, or below).
Initialization Parameters Affected
The following parameters are automatically computed:
DB_BLOCK_LRU_LATCHES - The number of LRU latches in
each buffer pool for
each block size will be
equal to the half the number of CPUs.
DB_WRITER_PROCESSES - The number of DBWR's will
be equal to 1/8th the
number of CPUs.
The following parameters have been deprecated and have been maintained only for backward compatibility:
DB_BLOCK_BUFFERS
BUFFER_POOL_KEEP
BUFFER_POOL_RECYCLE
These parameters cannot be combined with the dynamic SGA feature
parameters.Setting these along with the Dynamic SGA parameters would
error out.
For example, if db_block_buffers as well as db_cache_size are set, then
startup would error out as follows:
SQL> startup pfile=initv09.ora
ORA-00381: cannot use both new and old parameters
for buffer cache size specification
Transport
tablespaces with different block sizes between databases
Tablespace transportation between databases owning different block
sizes is allowed in Oracle9i.
Oracle9i offers the possibility to plug into a 9i database any
tablespace transported from 8i databases of any block size.
Plug an 8i tablespace of 2K db block size into a 9i database of
4K db block size
1. Creation of the tablespace in the 8.1.5 database (db_block_size=2048)
SQL> create tablespace test_tts datafile
'/ora/ora815/oradata/V815/tts01.dbf' size 100k;
Tablespace created.
SQL> create table test (c number) tablespace
test_tts;
Table created.
SQL> insert into test values (1);
1 row created.
SQL> commit;
Commit complete.
SQL> execute
sys.dbms_tts.transport_set_check(ts_list => 'TEST_TTS',
incl_constraints => true);
PL/SQL procedure successfully completed.
The TRANSPORT_SET_VIOLATIONS view can be used to check
for any violations:
SQL> SELECT * FROM sys.transport_set_violations;
no rows selected
2. Assuming no violations are produced we are ready to proceed by
switching the tablespace to read only mode:
SQL> alter tablespace test_tts read only;
Tablespace altered.
3. Export the 8.1.5 tablespace for transportation
$ exp sys/manager transport_tablespace=y tablespaces=TEST_TTS
file=TEST_TTS
4. Ftp the export dump file and datafiles to the 9i database server
5. Import the 8.1.5 tablespace into the 9i database (db_block_size=4096)
$ imp 'system/manager@oracle9i as sysdba' transport_tablespace=y tablespaces=TEST_TTS datafiles='/oradata/V900/V900/tts01.dbf' file=TEST_TTS
6. The following settings must be prepared before plugging the
tablespace owning a block size different from the 9i database block
size.
SQL> alter system set db_2k_cache_size=10m;
System altered.
$ imp transport_tablespace=y tablespaces=TEST_TTS datafiles='/oradata/V900/V900/tts01.dbf'
SQL> select tablespace_name, block_size
from dba_tablespaces;
TABLESPACE_NAME
BLOCK_SIZE
------------------------------ ----------
SYSTEM
4096
UNDOTBS
4096
EXAMPLE
4096
INDX
4096
TEMP
4096
TOOLS
4096
USERS
4096
TEST_TTS
2048
Execute the following sentence in both databases:
SQL> alter tablespace test_tts read write;
Tablespace altered.
Plug an 9i tablespace of 8K block size into another 9i database
of 4K db block size
1/ Creation of an 8K block size tablespace in the 9.0.0 database
(db_block_size=4096)
SQL> create tablespace tts_8k datafile
'/export/home1/ora900/oradata/V900/tts.dbf' size 200k blocksize 8k;
Tablespace created.
SQL> create table oe.test (c number) tablespace
tts_8k;
Table created.
SQL> insert into oe.test values (1);
1 row created.
SQL> commit;
Commit complete.
2/ Prepare the 9.0.0 8K tablespace to be transported to another 9i
database
SQL> alter tablespace tts_8k read only;
Tablespace altered.
3/ Export the 9.0.0 8K tablespace for transportation
$ NLS_LANG=american_america.WE8ISO8859P1
$ export NLS_LANG
$ exp "system/manager@oracle1 as sysdba"
transport_tablespace=y tablespaces=TTS_8K file=/tmp/djeunot/expdat.dmp
4/ Ftp the export dump file and datafiles to the target 9i database server
5/ Import the 9.0.0 8K tablespace into the target 9i database (db_block_size=4096)
SQL> alter system set db_8k_cache_size =8m;
System altered.
$ NLS_LANG=american_america.WE8ISO8859P1
$ export NLS_LANG
$ imp 'sustem/manager@oracle2 as sysdba'
transport_tablespace=y tablespaces=TTS_8K
datafiles='/oradata/V900/V900/tts_8k.dbf' file=/tmp/expdat.dmp
SQL> select tablespace_name, block_size from dba_tablespaces;
TABLESPACE_NAME
BLOCK_SIZE
------------------------------ ----------
SYSTEM
4096
UNDOTBS
4096
EXAMPLE
4096
INDX
4096
TEMP
4096
TOOLS
4096
USERS
4096
TEST_TTS
2048
TTS_8K
8192
Note
The restrictions that existed in 8i regarding character sets when
transporting tablespaces from one database to another still remain.
The target database must have the same character set as the source
database.
Multi-Table Insert
Until Oracle 8i, you had to run throught the data
multiple times or write procedural code to perform inserts into
multiple tables in one pass. 9i's Multi Table Insert feature provides a
feature to insert data into multiple tables in one pass. The multitable
insert feature allows the INSERT . . . SELECT statement
to use multiple tables as targets. In addition, it can distribute data
among target tables based on logical attributes of the new rows.
Multitable insert thus enables a single scan and transformation of
source data to insert data into multiple tables, sharply increasing
performance.
Prior to Oracle9i, such processing could be done in two different ways.
It could be done through SQL with an independent INSERT . . . SELECT
statement for each table. This approach meant processing the same
source data and the transformation workload once for each target.
If the SELECT statement itself used a major transformation (which it
often does, e.g., GROUP BY), then the transformed data was either
recomputed for each scan or materialized beforehand in a temporary
table to improve performance. Alternatively, this type of work could be
performed in procedural programs: every row would be examined to
determine how to handle the insertion.
Both of these techniques had significant drawbacks. If the insert was
performed through SQL, multiple scans and transforms of the source data
would hurt performance. Creating a temporary table to hold precomputed
transformation results could consume large amounts of disk space, and
the temporary table would still be scanned multiple times. The
procedural programming approach could not use the high-speed access
paths directly available in SQL, so it also faced performance handicaps.
Example
The following example statement inserts new customer information from
the customers_new table into two tables, customers and
customers_special. If a customer has a credit limit greater than 4500,
the row is inserted into customers_special. All customer rows are
inserted into table customers.
The operation in Oracle8i could be
implemented as follows:
INSERT INTO customers_special
(cust_id,cust_credit_limit)
SELECT cust_id, cust_credit_limit
FROM customers_new
WHERE cust_credit_limit >=4500;
INSERT INTO customers
SELECT * FROM customers_new;
The same operation in Oracle9i could be implemented as follows:
INSERT FIRST
WHEN cust_credit_limit >=4500 THEN
INTO customers_special
VALUES(cust_id,cust_credit_limit)
INTO customers
ELSE
INTO customers
SELECT * FROM customers_new;
Command format for the multi-table insert.
INSERT {all|first}
[WHEN {condition1}] THEN
INTO {table_name} VALUES ....
[WHEN {condition2}] THEN
INTO {table_name} VALUES ....
[ELSE INTO {table_name} VALUES ....
…
{select_statement};
Before getting to some examples, let's take a closer look at the
different parts of the multi-table insert.
insert {all|first}
Since this is an insert statement, you start the command with the
INSERT keyword. Immediately after this keyword, you want to specify
whether this is an "all insert" or a "first insert" with the
appropriate keyword.
To specify an all insert, you use the keyword ALL. An all insert will
check every line of data against all of the conditions. If there aren't
any conditions, the data will be inserted into every table listed.
Otherwise, it will only be inserted into the tables where the
conditions are met.
To specify a first insert, you use the keyword FIRST. A first insert
will check every line of data against all of the conditions as well.
However, it will stop once one of the conditions is met. If you specify
a first insert, you need at least one condition.
[when {condition}]
This line of the multi-table insert is the condition line. Since you
can create an insert without any conditions, this line is optional.
However, if you do include one or more conditions, you have to do so in
the format shown. Each condition line starts with the WHEN keyword
followed by the actual condition statement. This statement is a Boolean
value that generally relates to the line of data being processed. For
instance, if you were inserting customer data and put the condition
line "when customer_id < 100", then only the customers that had an
id less than 100 would be subject to the into statement(s) that follow.
You can have as many condition lines as you need. If you have a first
insert, you can also use the ELSE keyword to create a special
condition. This condition will only be met if all of the other
conditions have failed. It's a catch-all condition.
VALUES
The third line is just the VALUES keyword. As you'll see in a moment, a
multi-table insert must receive the data from a select statement. For a
regular insert, when the data comes from a select statement, you don't
include this keyword. However, for this version of the insert
statement, it's required.
As with the conditions, you can include any number of INTO clauses.
The only limitation is that you need at least one INTO clause for each
condition or at least one for the entire multi-table insert if you
don't have any conditions. The last statement is:
{select_statement};
This line of the multi-table insert determines what data will be
inserted into the tables. As mentioned earlier, this data must come
from a select statement, and you can make the statement as simple or as
complex as you want to so long as it's valid.
When creating the statement, you should remember that you'll be using
the column names in the INTO clause. In order to keep things simple,
you should always name any column that's not a single field. For
instance, if you combine two fields as part of the select statement,
you should give that column a name. You can then refer to that field by
that name in the INTO clause.
Unconditional
insert
The most basic type of multi-table insert is the unconditional insert.
The name of the insert gives the details. It's unconditional–in other
words, there will be no condition lines. Instead, every row of data
that's returned by the select statement is inserted into the various
tables.
You'd use this type of insert when you need to quickly split all of the
data up onto separate tables. In order to better illustrate this, let's
look at an example. Using the customer_load table identified earlier, I
want to create an unconditional insert that will insert all of the data
into the customer and customer_address tables
The unconditional insert
example.
insert all
into customer
( customer_id,
first_name, middle_initial,
last_name, birth_date, gender, married )
values
( customer_id,
customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married )
into customer_address
( customer_id,
address1, address2, city,
state, zip )
values
( customer_id,
address1, address2, city,
state, zip )
select customer_id,
customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married,
address1,
address2, city, state, zip
from customer_load;
This example has two INTO clauses. The first one inserts records into
the customer table. The second one inserts records into the
customer_address table. Since the primary key on the customer table is
the foreign key on the customer_address table, they must be inserted in
this order. Otherwise, you'll get a constraint error, unless you're
working with deferred foreign keys.
Conditional
all insert
The conditional all insert table is the next type of multi-table
insert. Conditional simply means that there will be one or more
condition lines. There could be more, but there will be at least one.
The word "all" in the name of the insert means that the keyword ALL was
used, making this an all insert. This type of insert will compare each
of the data rows from the select statement to every condition. When a
condition is met, the INTO clause under that condition is executed.
The conditional all insert
example.
insert all
when married in ('Y','N')
then
into customer
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender, married )
values
(
customer_id, customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married )
into
customer_address
(
customer_id, address1, address2, city,
state, zip )
values
(
customer_id, address1, address2, city,
state, zip )
when married = 'Y' then
into
customer_spouse
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender )
values
(
customer_id, spouse_first_name,
spouse_middle_initial, spouse_last_name,
spouse_birth_date, spouse_gender )
select customer_id,
customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married,
spouse_first_name, spouse_middle_initial,
spouse_last_name, spouse_birth_date, spouse_gender,
address1,
address2, city, state, zip
from customer_load;
This example has two conditions. The first condition checks to see if
the married field is either 'Y' or 'N'. This field is a flag that's
always one or the other. In other words, this condition will always be
true. You always want to insert into the customer and customer_address
tables. The customer table has the important customer_id field that's
used as a foreign key on all of the other tables.
The second condition checks to see if the married field is 'Y'. If this
is the case, then the customer is married and you want to insert the
spouse information into the customer_spouse table. You wouldn't want to
always insert this row since, if the customer isn't married, all of the
spouse information would be null. Not only is it a poor practice to
insert null rows, but some of the fields on the customer_spouse table
might have a not null constraint.
Conditional
first insert
The conditional first insert table is similar in many ways to the
previous type. It will also have one or more condition lines. The major
difference is the FIRST keyword. When this keyword is used, the INTO
clause of the first true condition will be executed and none of the
others.
The conditional first insert
example.
insert first
when married = 'N' then
into customer
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender, married )
values
(
customer_id, customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married )
into
customer_address
(
customer_id, address1, address2, city,
state, zip )
values
(
customer_id, address1, address2, city,
state, zip )
when married = 'Y' then
into customer
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender, married )
values
(
customer_id, customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married )
into
customer_address
(
customer_id, address1, address2, city,
state, zip )
values
(
customer_id, address1, address2, city,
state, zip )
into
customer_spouse
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender )
values
(
customer_id, spouse_first_name,
spouse_middle_initial, spouse_last_name,
spouse_birth_date, spouse_gender )
select customer_id,
customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married,
spouse_first_name, spouse_middle_initial,
spouse_last_name, spouse_birth_date, spouse_gender,
address1,
address2, city, state, zip
from customer_load;
As with the previous example, this one has two conditions. The first
condition checks to see if the married field is set to 'N'. In other
words, it checks to see if the customer isn't married. If the condition
is true and the customer isn't married, you insert into the customer
and customer_address tables. You don't insert into the customer_spouse
table.
The second condition checks to see if the married field is Y' (the
customer is married). You could replace this condition with an ELSE
statement if you wanted to. For this situation, either would work. If
this condition is met and the customer is married, you insert
information into the customer, customer_address, and customer_spouse
tables.
Pivoting
the insert
In addition to the three main types of multi-table inserts, you can
also use the pivoting sub-type. A pivoting insert isn't truly a
separate type of insert. Instead, it's a variation of the other three
types. This type of insert is used to insert multiple rows of data into
the same table.
Remember that in the conditional first insert, I used the same INTO
clause multiple times. However, since only one of the conditions could
be true, the INTO clause was only executed once. Therefore, each table
will have a single INSERT clause. For a pivoting insert, this isn't the
case. Each table could have multiple INSERT clauses.
On the customer_load table, there's one column for each phone
type–phone_number, cell_number, and fax_number. In this example, I want
to pivot those three columns into three inserts of the customer_phone
table.
The pivoting insert.
insert all
when married in ('Y','N')
then
into customer
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender, married )
values
(
customer_id, customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married )
into
customer_address
(
customer_id, address1, address2, city,
state, zip )
values
(
customer_id, address1, address2, city,
state, zip )
when married = 'Y' then
into
customer_spouse
(
customer_id, first_name, middle_initial,
last_name, birth_date, gender )
values
(
customer_id, spouse_first_name,
spouse_middle_initial, spouse_last_name,
spouse_birth_date, spouse_gender )
when phone_number is not
null then
into
customer_phone
(
customer_id, phone_type, phone_number )
values
(
customer_id, 'Phone', phone_number )
when fax_number is not
null then
into
customer_phone
(
customer_id, phone_type, phone_number )
values
(
customer_id, 'Fax', fax_number)
when cell_number is not
null then
into
customer_phone
(
customer_id, phone_type, phone_number )
values
(
customer_id, 'Cell', cell_number )
select customer_id,
customer_first_name,
customer_middle_initial, customer_last_name,
customer_birth_date, customer_gender, married,
spouse_first_name, spouse_middle_initial,
spouse_last_name, spouse_birth_date,
spouse_gender,
address1, address2, city, state,
zip,
phone_number, fax_number, cell_number
from customer_load;
The last three conditions show the pivoting insert. In the first
condition, the phone_number field is checked on the customer_load table
to make sure it's not null (in other words, if it exists). If this
field does exist, the INTO clause loads that data into the
customer_phone table. If it doesn't exist, you don't want to insert an
empty row. The phone_type field isn't populated from the customer_load
table. Instead, you use a constant, 'Phone', as the type.
The second and third conditions do the exact same thing, except for the
fax_number and cell_number fields. The phone_type fields for these two
INTO clauses are set to 'Fax' and 'Cell', respectively. Each row of
data in the customer_load table can create up to three rows of data in
the customer_phone table.
Performance
issues
Another reason to use a multi-table insert is the performance gains. In
a six inserts statement (for example), each statement uses a similar
select statement to provide the data for the insert. This means that
each insert will have to complete a full access on the customer_load
table. Since this is a loader table, it could have a huge amount of
data on it. Cycling through this potentially large amount of data could
be resource-intensive.
Fortunately, we can get around this problem. Regardless of the number
of INTO clauses or conditions, a multi-table insert will only need to
do one full access
The restrictions on multitable INSERTs are:
MERGE Statement (Insert or Update data)
The MERGE statement can be used to conditionally insert or update data
depending on its presence in one Statement. This method reduces table
scans and can perform the operation in parallel. Consider the following
example where data from the HR_RECORDS table is merged into the
EMPLOYEES table:
SELECT * FROM DEPTBIG;
DEPTNO DNAME
LOC
--------- ------------- ----------
10
ACCOUNTING NEW YORK
20
RESEARCH DALLAS
30
SALES CHICAGO
40 RESEARCH
BOSTON
SELECT * FROM DEPT2;
DEPTNO DNAME LOC
------- ----------- ----------------
40 OPERATIONS
CHICAGO (to update)
50 OPERATIONS
CHICAGO (to insert)
merge into DEPTBIG a
using (select deptno, dname, loc from dept2) b
on (a.deptno = b.deptno)
when matched then
update set a.loc = b.loc
when not matched then
insert (a.deptno, a.dname, a.loc)
values (b.deptno,
b.dname, b.loc);
2 rows merged.
SELECT * FROM DEPTBIG;
DEPTNO DNAME LOC
------- ----------- ----------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30
SALES CHICAGO
40 RESEARCH
CHICAGO (was updated)
50 OPERATIONS CHICAGO (new
record)
Another Example
Trial Recovery
Some problems that may occur during media recovery are not
"recoverable". For example, if a redo log was somehow corrupted and
recovery could not pass changes in the redo stream, the recovered
database becomes useless. This is known as "stuck
recovery". When problems such as stuck
recovery occur, you have a difficult choice. If the block is relatively
unimportant, and if the problem is isolated, then it is better to
corrupt the block. But if the problem is not isolated, then it may be
better to open the database with the RESETLOGS option. This means
that one must restore the backup and recover the database again to an
SCN before the point where the corruption occurred. For a large
database, restoring a backup and recovering the database can take a
long time.
To address this problem, the concept of Trial Recovery is introduced. Trial recovery applies redo in a way similar to normal media recovery, but it never writes its changes to disk, and it always rolls back its changes at the end of the test. Trial recovery is designed to allow a DBA to peek ahead in the redo stream to see if there are additional problems.
Trial Recovery provides database administrators the following enhancements so that almost all practical problems during media recovery are recoverable.
The database provides a lot of information about the problem in the alert logs. The alert log indicates if recovery is capable of recovering past the problem by marking as corrupted the data block causing the problem. The alert log also provides information about the block: its file name, file number, block number, block type, data object number, and so on. You can then investigate the impact of corrupting the problematic block according to the information provided in the alert logs. The database can be opened read-only, provided that all of the database files have been recovered to the same point in time, and query the database to see to what table this data block belongs. Trial Recovery allows you to assess the entire extent of damage.
How Trial Recovery Works
By default, if a trial recovery encounters a stuck recovery or similar
problem, then it always marks the data block as corrupt in memory when
this action can allow recovery to proceed. Oracle writes errors
generated during trial recovery to alert files. Oracle clearly marks
these errors as test run errors.
Like normal media recovery, trial recovery can prompt you for archived
log filenames and ask you to apply them. Trial recovery ends when:
When trial recovery ends, Oracles removes all effects of the test
run from the system--except the possible error messages in the alert
files. If the instance fails during trial recovery, then Oracle removes
all effects of trial recovery from the system because trial recovery
never
writes changes to disk.
RMAN NEW
Recovery Manager automates backup and recovery by querying information
in the recovery catalog, the database's control file, and any datafiles
affected by the operations requested. Recovery Manager decides the most
efficient method of executing the requested backup, restore, or
recovery operation and then issues these steps to the Oracle server.
Recovery Manager
and the server automatically identify modifications to the structure of
the database, and dynamically adjust the current operation to cater to
the changes.
KEY FEATURES OF RECOVERY MANAGER
- Automation of backup, restore and recovery operations
- Block media recovery
- Whole database backups or backups of any logical unit: control file,
datafile, tablespace or archive log
- Offline and Online backups
- Integrated with 3rd Party Media Management Vendors to backup to tape
- Two types of backup: image copies to disk or Recovery Manager backup
sets
- Intelligent management of the archived redo logs for both backup and
recovery
- Proxy Copy Backup Accelerator for fast copy technology at the storage
subsystem level
- Corrupt block detection
- Tablespace Point-in-Time Recovery support
- Ability to catalog on disk operating system backups
- Integration with Oracle Enterprise Manager's Backup Manager GUI
- Incremental backups at the Oracle block level for high performance
backup and recovery
- Omission of empty blocks during backup for optimization
- Recoverability redundancy when both incrementals and archiving are
used
- No extra redo is generated during online database backup
- Intelligent buffering with multiplexing of multiple input files for
high speed tape streaming
- Support for Oracle Real Application Clusters backup and recovery
- Ability to recover through unrecoverable operations, when using
incremental backups
- O/S-independent scripting language
Persistent RMAN Configurations
A CONFIGURE command has been introduced in Oracle 9i, that lets you
configure various features including automatic channels, parellelism,
backup options etc., that can persist across sessions and be available
to any session. For example, the CONFIGURE command may be used to store
channel configurations and RMAN will automatically assignt the channels
as needed without having to specify the channel allocation as a part of
the script. These automatic allocations and options can be overridden
by commands in an RMAN command file.
Control File Auto Backups
Many of the database administrators stayed away from using RMAN citing
the reliance of RMAN on control files / recovery catalog for backup
and recovery options. Now you need not worry about a lost recovery
catalog or a lost control file. Control File Auto Backups give the dba
a way to
restore the backup repository contained in the control file when a
control
file and the recovery catalog are both lost. For some of us using the
nocatalog option this comes in very handy when we have to recover
without
having the control file that was used for the RMAN backup.
To use this feature, CONFIGURE CONTROLFILE AUTOBACKUP should be set to ON, and RMAN will automatically perform a control file autobackup after every BACKUP or COPY command is issued whether its in a RUN Block or at the command prompt. This control file backup occurs in addition to any control file backup that has been created as a part of the database backup.
Block Media Recovery
RMAN introduces a new blockrecover command to recovery individual
datablocks within a data file. This reduces the Mean Time to Recovery (
MTTR ) for a large datafile when individual blocks within the file are
reported as corrupt. Without this feature, even if a single block is
corrupted the dba has to restore the whole datafile and recovery using
the archived redo logs that were generated since that backup was
created.
This procedure is useful when a trace file or standard output reveals that a small number of blocks within a datafile are corrupt. A major restriction is that you can only recover from a full RMAN backup and incremental backups cannot be used for this type of recovery. Also only complete recovery can be performed on individual blocks cand you cannot stop the redo application while the recovery is in progress.
Block Media recovery can be performed by using a command at the RMAN command prompt similar to the one given below.
BLOCKRECOVER DATAFILE 6 BLOCK 23 DATAFILE 12 BLOCK 9;
Other Enhancements
To make the job of the DBA more error free, Oracle enhance the CHANGE,
CROSSCHECK, DELETE and LIST commands. Also RMAN automatically switches
out the online redo log before backing up the archived redo logs to
guarantee that the backups can be restored to a consistent state. One
cool feature I like is the "NOT BACKED UP SINCE " clause that allows
RMAN to backup only those files that were not backed up after a
specified time. So, if
a backup fails partway through, you can restart it and back up only
those
files that were not previously backed up. To help you preserve your
current server side parameter file (SPFILE), RMAN can backup your
SPFILE automatically. RMAN will do this if the instance was started
with the SPFILE and the RMAN operation includes an automatic backup of
the control file.
For backups made with the autobackup feature enabled, RMAN generates a
separate backup piece to hold the SPFILE and control file backup. You
can manually backup the SPFILE used to start your instance with the
BACKUP command. If CONTROLFILE AUTOBACKUP is ON then RMAN will
automatically back up the control file and server parameter file after
structural changes to the database. The target database records the
autobackup in the alert log. Unlike the RMAN BACKUP DATABASE command,
the RESTORE DATABASE command does not restore the SPFILE (nor the
control file) automatically.
During an RMAN recovery operation, archived log files may need to be
retrieved from a backup set and stored on disk. You can direct RMAN to
delete the archived logs after reading them, however space problems can
occur because the process to restore the archive logs to disk is faster
than the operation to apply the archived logs to the database. In
previous releases, if the target disk location ran out of space, the
whole recovery operation would fail.
To avoid this problem in Oracle9i Database Release 2, specify the
maximum disk space available for the archive backup files when you use
RECOVER…DELETE command in RMAN. This causes RMAN to delete used files
when the next part of the backup set would exceed the specified
storage. Include the MAXSIZE parameter in the RECOVER…DELETE command to
indicate how much space you have available in bytes, with an optional
K, M, or G. The example shows a recovery operation for which 100KB of
disk space is made available for the archived logs.
If MAXSIZE is too small to hold a full archive log, RMAN will terminate
the recovery operation with an error. If MAXSIZE is smaller than a
backupset containing the required archived logs, the backup set will be
read more than once, increasing the overall recovery time. In this
case, RMAN will issue a warning advising you to increase the value of
MAXSIZE.
Self
Managing Rollbacks and Files
Oracle9i databases are capable of managing their own undo (Rollback)
segments -no longer will administrators need to carefully plan and tune
the number and sizes of rollback segments or bother about how to
strategically assign transactions to a particular rollback segment.
Oracle9i also allows administrators to allocate their undo space in a
single undo tablespace with the database taking care of issues such as
undo block contention, consistent read retention and space utilization.
Oracle9i also introduces the concept of "Oracle Managed Files"
which simplifies database administration by eliminating the need for
administrators
to directly manage the files comprising an Oracle database. Oracle9i
now internally uses standard file system interfaces to create and
delete
files as needed. While administrators still need to be involved in
space
planning and administration, this feature automates the routine task
of creation and deletion of database files.
Oracle uses the standard operating system (OS) file system interfaces
internally to create and delete files as needed for tablespaces, online
logs and controlfiles. DBAs only need to specify the location of these
files using new initialization parameters. Oracle then ensures creation
of a file with a unique name and delete it when the corresponding
object
is dropped. OMF reduces errors caused by administrators specifying
incorrect
file names, reduces disk space wasted in obsolete files, and simplifies
creation of test and development databases. It also makes development
of portable third party applications easier since it eliminates the
need
to put OS specific file names in SQL scripts.
Locally managed tablespaces offer two options for extent management, Auto Allocate and Uniform (ASSM). In the Auto Allocate option, Oracle determines the size of each extent allocated without DBA intervention, whereas in the Uniform option, the DBA specifies a size and all extents allocated in that tablespaces are of that size. We recommend using the Auto Allocate option because even though it might result in objects having multiple extents, the user need not worry about it since locally managed tablespaces can handle a large number of extents (over 1000 per object) without any noticeable performance impact. With the SEGMENT SPACE MANAGEMENT AUTO option the DBA no longer needs to tune the PCTUSED, FREELIST and FREELIST GROUPS segment attributes. The following example illustrates how to create a tablespace with Automatic Segment Space Management.
CREATE TABLESPACE data DATAFILE '/u02/oracle/data/data01.dbf' SIZE 50M
EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT AUTO;
Syntax
The LOCAL option of the EXTENT MANAGEMENT clause specifies that a
tablespaces is to be locally managed.
Extent_management_clause:
[EXTENT MANAGEMENT
{DICTIONARY | LOCAL
{AUTOALLOCATE | UNIFORM [SIZE integer [K|M] }}]
where:
DICTIONARY specifies that the tablespace is managed using dictionary
tables (this is the default)
LOCAL specifies that tablespace is locally managed with a bitmap
AUTOALLOCATE specifies that the tablespace is system managed (users
cannot specify an extent size)
UNIFORM specifies that the tablespace is managed with uniform extents
of SIZE bytes (use K or M to specify the extent size in kilobytes or
megabytes. The default size is one megabyte. If you specify, LOCAL, you
cannot specify DEFAULT storage_clause, MINIMUM EXTENT or TEMPORARY.
If you use ASSM, you reduce the chances to have buffer busy waits
(several users trying to access a specific block to perform an insert).
On the other hand, tests indicates that full table scans are
going to take from 11 to 23% longer. But anyway, we HIGHLY recommend to
use it.
All objects created in the above tablespace will use the automatic
segment space management feature to manage their free space. This
means that Oracle uses bitmaps to manage space within segments instead
of using freelists, the traditional method. A new column called
SEGMENT_SPACE_MANAGEMENT has been added
to the DBA_TABLESPACES view to indicate the segment space management
mode used by a tablespace (it will show AUTO). In Summary:
- Free space within a segment is maintained using bitmaps
- Eliminates the necessity to tune parameters such as FREELISTS,
FREELIST GROUPS and PCTUSED
- Improves space utilization especially for objects with rows of highly
varying sizes
- Improves concurrency of INSERT operations
- Better multi-instance behavior in terms of performance/space
utilization
Once a table or index is allocated in this tablespace, the values
for PCTUSED for individual objects will be ignored, and Oracle9i will
automatically manage the FREELISTS for the tables and indexes inside
the tablespace. For objects created in this tablespace, the NEXT extent
clause is now obsolete because of the locally-managed tablespace
(except
when a table is created with MINEXTENTS and NEXT). The INITIAL
parameter
is still required because Oracle cannot know in advance the size of the
initial table load. When using Automatic Space Management, the minimum
value for INITIAL is three blocks
While the parameter DB_CREATE_FILE_DEST specifies the default location
of datafiles, the parameter DB_CREATE_ONLINE_LOG_DEST_<n>, where
n is any integer between 1 and 5, decides the default location for
copies of online logs and controlfiles. If neither of the last two
parameters are set, all the files (datafiles, controlfiles and online
logs) will be created at the destination specified by the
DB_CREATE_FILE_DEST parameter. Oracle Managed datafiles, created by
default, will be 100 MB in size and will be auto extensible with
unlimited maximum size. The default size of Oracle Managed online logs
will also be 100MB.
* Oracle Managed Files
* Default Temporary Tablespace
In Oracle9i, the database can be assigned a DEFAULT TEMPORARY TABLESPACE. This feature is designed for database users to have a default temporary tablespace automatically assigned other than the SYSTEM tablespace.
Restrictions on the DEFAULT TEMPORARY TABLESPACE:
1. The DEFAULT TEMPORARY TABLESPACE must be of TEMPORARY
2. The DEFAULT TEMPORARY TABLESPACE cannot be converted to PERMANENT once it has been defined as the DEFAULT TEMPORARY TABLESPACE
3. Before dropping the DEFAULT TEMPORARY TABLESPACE, create another one
4. The DEFAULT TEMPORARY TABLESPACE cannot be taken OFFLINE
To have a TEMP tablespace as a default tablespace for the database
use:
alter database default temporary tablespace TEMP;
* Delete Datafiles
Specific Information on Oracle Managed Files and its setup is HERE
List Partitioning
Oracle started providing the facility to divide a large table into
partitions right from Oracle8. But the paritioning is primarly based on
the range. That means, Oracle determines into which partition a row is
placed based on the range to which the value in the column belongs.
The following example shows how to create a partition based on the rate
of the product.
create table sales_history
( pid number(5),
qty number(3),
rate number(5),
dp date,
state char(2)
)
partition by range(rate)
( partition low values
less than (1000),
partition normal values less
than(5000),
partition high values
less than (maxvalue)
);
The above command creates SALES_HISTORY table and then places a row
into either of the three partitions based on the value of RATE column.
Now, starting from Oracle9i database, Oracle supports list partition in
addition to range partition. In list partitioning, a table is divided
into partitions based on a list of values. For example the following
command
creates SALES_HISTORY table with four partitions based on the values
of STATE column.
create table sales_history
( pid number(5),
qty number(3),
rate number(5),
dp date,
state char(2)
)
partition by list (state)
( partition south values('AP','TN','KE'),
partition north
values('DE','JK','PU'),
partition west
values('MA','PU'),
partition east
values('WB','SI')
);
If a rows contains the value AP or TN or KE in STATE column then the
row is placed in SOUTH partition. Similarly if the value of STATE is DE
or JK or PU then the row is placed in NORTH partition and so on.
Though the overall concept of partition and its benefits are the same
between range and partitions, the possible of dividing table into
partitions based on discrete values of the column is new in Oracle9i
database.
External Tables
The External Table feature allows for flat files, which reside outside
the database, to be accessed just like relational tables within the
database: the flat-file data can be queried and joined to other tables
using standard SQL. Data access can be serial or parallel for maximum
scalability. From a user's point of view, the main difference between
an external table
and a regular table is that the external table is read-only. To
understand
the value of external tables, consider that a data warehouse always
contains data from external data sources. Prior to Oracle9i, performing
complex transformations within Oracle required that the external data
be transformed using one of two possible strategies:
Load the data into Oracle and store it in a staging table. When
the transformations were finished the table could be deleted. This
approach devoted disk space, administrative resources and processing
time to data that was already available on disk.
Oracle9i's external tables avoid the problems inherent in the
approaches
described above: external tables provide a whole new model for loading
and transforming external data. The data is no longer transformed
outside
the database, nor must it be stored in a staging table. Instead, the
external data is presented to the database as a virtual table, enabling
full data processing inside the database engine. This seamless
integration of external data access with the transformation phase is
generally referred to as "pipelining." With pipelining, there is no
interruption of the
data stream, so every ETL process can show increased performance.
The structure of the external table is not enforced until the time a
query is issued against it. Only the fields accessed by a SQL query on
the External table are examined. This means that only the data elements
accessed in the SQL query are actually loaded by the SQL*Loader
process. In other words, if an invalid data element is not accessed it
will not be caught by the SQL*Loader process. However, if a different
query exposes this field, an error will occur on those records with
invalid data. This could result in a loss of records depending on the
“REJECT LIMIT” parameter.
External Table Notes
Performance of any flat file import tool, including external tables, is
impacted by the amount of parsing it must perform. Fixed width files do
not require the level of parsing that delimited files do. Although
fixed width files are larger than delimited files, they will parse and
load faster. (However, the difference in performance may be
negligible). The external table can be queried in parallel. Just like a
normal table, the external table parallel degree can be set in the DDL
or in a hint added to the query. I recommend that the parallel degree
option be withheld from the DDL. If you find that a parallel query is
to your benefit, consider applying the parallel hint. This will give
you additional flexibility in your code. Different data volumes of the
same file layout may react differently to the parallel query and in a
few cases will slow the process down. My experience has been that the
hints are not always implemented by the database (even if it is to your
benefit in the rule or cost based optimizer). To ensure that parallel
processing occurs, consider altering the session to force parallel DML:
ALTER SESSION FORCE PARALLEL DML;
select /*+ PARALLEL(EXTERNAL_TABLE_NAME,
3) */ * from external_table_name;
Oracle uses the CREATE TABLE..ORGANIZATION EXTERNAL syntax to store
metadata about the external table:
-- Create directory object to
data location
CREATE OR REPLACE DIRECTORY
EXT_TABLES AS 'C:\Oracle\External_Tables';
-- Create the external table
-- Files must exist in the
specified location
CREATE TABLE employees_ext
(empno NUMBER(8),
first_name VARCHAR2(30), last_name
VARCHAR2(30))
ORGANIZATION EXTERNAL
(
TYPE ORACLE_LOADER
DEFAULT DIRECTORY ext_tables
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE
FIELDS TERMINATED BY ','
)
LOCATION
('employees1.txt','employees2.txt')
)
PARALLEL 5
REJECT LIMIT 200;
-- Query the table
SELECT * FROM employees_ext;
Another Example (DO NOT use the
--comments inside the create table statement):
CREATE OR REPLACE DIRECTORY DIR1
AS 'C:\Temp';
GRANT READ ON DIRECTORY DIR1 to
fg82_blink_dev;
GRANT WRITE ON DIRECTORY DIR1 to
fg82_blink_dev;
-- Create the external table
-- Files must exist in the
specified location
CREATE TABLE ext_table
(documentid VARCHAR2(14),
decision
VARCHAR2(6),
Comments VARCHAR2(30)
)
ORGANIZATION EXTERNAL
(
TYPE ORACLE_LOADER
DEFAULT DIRECTORY DIR1
ACCESS PARAMETERS
(
--
RECORDS FIXED 120
RECORDS DELIMITED BY NEWLINE
LOAD WHEN ("DOCUMENTID" = "1" OR "DOCUMENTID" = "0")
badfile DIR1:'Upload_Except.bad'
-- NOBADFILE
DISCARDFILE DIR1:'Upload_Except.dis'
-- NODISCARDFILE
logfile DIR1:'Upload_Except.log'
-- NOLOGFILE
FIELDS
--
FIELDS TERMINATED BY ','
MISSING FIELD VALUES ARE NULL
-- REJECT ROWS WITH ALL NULLS FIELDS
(
documentid position(67:80) char,
decision position(84:89) char(6) NULLIF decision=BLANKS,
comments position(90:119) char
)
)
LOCATION ('Upload_Except.txt')
)
REJECT LIMIT UNLIMITED
NOPARALLEL;
-- Query the table
SELECT * FROM ext_table;
------------------
--Query
Locations
------------------
SQL> select * from dba_directories ;
OWNER DIRECTORY_NAME
DIRECTORY_PATH
----- --------------
------------------------
SYS
ADMIN_DAT_DIR e:\external_tables\data
SYS
ADMIN_DAT_DIR e:\external_tables\bad
SYS
ADMIN_DAT_DIR e:\external_tables\log
SQL> select * from dba_external_locations where
table_name='ADMIN_EXT_EMPLOYEES';
OWNER
TABLE_NAME
LOCATION DIRECTORY_OWNER DIRECTORY_NAME
--------- ------------------ ------------ ---------------
--------------
SCOTT ADMIN_EXT_EMPLOYEES
empxt1.dat
SYS
ADMIN_DAT_DIR
SCOTT ADMIN_EXT_EMPLOYEES
empxt2.dat
SYS
ADMIN_DAT_DIR
Some Notes
Syntax
RECORD {FIXED integer | VARIABLE integer | DELIMITED BY {NEWLINE
| string}}
{
CHARACTERSET string
|DATA IS {LITTLE | BIG} ENDIAN
|STRING SIZES ARE IN {BYTES | CHARACTERS}
|LOAD WHEN condition
|{NOBADFILE | BADFILE [directory name :
]filename}
|{NODISCARDFILE | DISCARDFILE [directory name : ]
filename}
|{NOLOGFILE | LOGFILE [directory name : ] filename}
|DATE_CACHE 0
|SKIP integer
}
More information on
http://www.csis.gvsu.edu/GeneralInfo/Oracle/server.920/a96652/part3.htm
http://www.quest-pipelines.com/newsletter-v4/0303_C.htm
If you get the error:
Date conversion cache disabled due
to overflow (default size: 1000)
You can use the option:
DATE_CACHE 0
Performance Manager
Oracle Enterprise Manager Performance Pack provides an enhanced
real-time diagnostics interface with a single graphical Performance
Overview
for "at-a-glance" Oracle performance assessment. The Overview chart
includes both host and database performance metrics organized by CPU,
memory and I/O resource usage. Top resources using sessions and
database contention are also displayed. Chart threshold flags
display the status of database and system performance allowing
DBAs to immediately identify performance exceptions. Trend arrows
provide a quick check on whether performance is improving or degrading.
The Diagnostics Pack also provides a set of pre-defined event
tests, known as Advanced Events, used to automatically monitor
conditions and detect problems for key elements of the Oracle
environment. The Advanced Events can be configured to check one
or more conditions for a target system. Thresholds, number
of occurrences, as well as event notification plans and corrective
actions can be customized. In addition, with version 9i,
administrators can investigate an event directly from the Console's
event viewer through direct access to the Performance Manager charts,
diagnostic help and advice, and historical data related to metrics
being monitored by the event.
First-N rows
Optimization
Oracle9i has added a new optimization mode that uses the cost based
optimizer to optimize selection of the first 'n' rows where 'n' can
equal 1, 10, 100, or 1000.
Fast response optimization is suitable for Online Transaction
Processing users. Typically, OLTP users are interested in seeing the
first few rows, and they seldom are interested in seeing the entire
query result, especially when the result size is large. For such users,
it makes sense to optimize the query to produce the first few rows as
fast as possible, even if the
time to produce the entire query result is not minimized.
More information Note:154354.1 Fast response optimization (FIRST_ROWS
variants)
This parameter can be set for the whole instance in the init.ora file,
at the session level using the ALTER SESSION command or for individual
statements as an optimizer hint:
OPTIMIZER_MODE = FIRST_ROWS_100
ALTER SESSION SET OPTIMIZER_MODE = FIRST_ROWS_10;
SELECT /*+ FIRST_ROWS(1000) */ empno, ename, sal, job FROM emp;
SQL
Aggregation Enhancements
In Oracle8i, aggregation processing was enhanced with the addition of
the CUBE and ROLLUP operators. These operators, extensions to SQL's
"GROUP BY" clause, enable a single SQL query to calculate certain
important sets of aggregation groups efficiently. Oracle9i extends SQL
aggregation capabilities further with grouping sets, concatenated
grouping
sets and composite columns. These features enable SQL queries to
specify
the exact levels of aggregation needed, simplifying development and
significantly enhancing query performance.
Grouping Sets
Grouping sets enable a single query to list multiple sets of columns
which will be grouped when calculating aggregates such as sums.
Grouping sets are specified by following the GROUP BY keyword with the
term "GROUPING SETS" and a column specification list. Here is an
example:
SELECT year, region, product, sum(sales)
FROM salesTable
GROUP BY
GROUPING SETS ((year, region, product),
(year, product),
(region, product));
The SQL above calculates aggregates over exactly 3 groupings: (year, region, product), (year, product), and (region, product). Without grouping sets, the query would need to be specified with either a CUBE operator or a UNION ALL query. Both of these alternative approaches have significant shortcomings:
The CUBE operator technique wastes processing power by
generating five unnecessary groupings. In addition, development is more
complex than when using grouping sets, since the five unneeded
groupings need to be filtered out of the results.
Concatenated Grouping Sets
The power of grouping sets is enhanced with concatenated grouping sets.
Concatenated grouping sets offer a concise way to generate large
combinations of groupings. Groupings specified with concatenated
grouping sets yield the cross-product of groupings from each grouping
set. Note that the concatenation can be performed on groupings
specified with CUBE and ROLLUP. The cross-product operation enables
even a small number of concatenated groupings to generate a large
number of final groups.
Here is an example of concatenated grouping sets:
GROUP BY GROUPING SETS (month, year),
GROUPING SETS (region, country)
The SQL above defines the following groupings:
(month, region), (month, country), (year,
region) and (year, country)
An important use for concatenated grouping sets is to generate the aggregates needed for OLAP data cubes. OLAP data cubes require aggregations along the rollup hierarchies of multiple dimensions, and this can be specified concisely by concatenating ROLLUP operators. The Oracle9i OLAP option takes advantage of this new feature for high performance processing.
Composite Columns in GROUP-BY Expressions
Oracle9i also enables the use of composite columns within GROUP BY
expressions. A composite column is a collection of columns, specified
within parentheses, that is treated as a single unit during the
computation of groupings. For example, by enclosing a subset of the
columns in a ROLLUP
list within parentheses, some levels will be skipped during ROLLUP.
Here
is a simple case where (quarter, month) is a composite column:
GROUP BY ROLLUP (year, (quarter, month), day)
Because of its composite column of (quarter, month), the SQL above
never separates the quarter and month columns in its ROLLUP. This means
that it never shows a rollup at the (year, quarter) level and thus
skips the quarter-level aggregates. Instead the query returns the
following
groupings:
(year, quarter, month, day), (year, quarter,
month), (year), ()
As with grouping sets, precise specification of the groupings
needed means simpler development and faster performance.
Oracle9i's new SQL aggregation features of grouping sets, concatenated
grouping sets and composite columns provide high efficiency
aggregations for the full range of business intelligence tasks. Oracle
products such as the Oracle9i OLAP option are already taking advantage
of the features to optimize performance, and users across the spectrum
of business intelligence processing will benefits from these features.
The SQL aggregation enhancements are just one aspect of Oracle9i
business intelligence functionality enabling more productive
development and faster query performance.
Improving
Query Performance with the SQL WITH Clause
Oracle9i significantly enhances both the functionality and performance
of SQL to address the requirements of business intelligence queries.
The
SELECT statements WITH clause, introduced in Oracle9i, provides
powerful new syntax for enhancing query performance. It optimizes query
speed by
eliminating redundant processing in complex queries. Consider a lengthy
query which has multiple references to a single subquery block.
Processing subquery blocks can be costly, so recomputing a block every
time it is referenced in the SELECT statement is highly inefficient.
The WITH clause enables a SELECT statement to define the subquery block
at the start of the query, process the block just once, label the
results, and then refer to the results multiple times.
The WITH clause, formally known as the subquery factoring clause, is
part of the SQL-99 standard. The clause precedes the SELECT statement
of a query and starts with the keyword "WITH". The WITH is followed by
the subquery definition and a label for the result set. The query below
shows a basic example of the clause:
WITH channel_summary AS
( SELECT channels.channel_desc,
SUM(amount_sold) AS
channel_total
FROM sales, channels
WHERE sales.channel_id = channels.channel_id
GROUP BY channels.channel_desc )
SELECT channel_desc, channel_total
FROM channel_summary
WHERE channel_total >
( SELECT SUM(channel_total) * 1/3
FROM channel_summary );
This query uses the WITH clause to calculate the sum of sales for
each sales channel and label the results as channel_summary. Then it
checks each channel's sales total to see if any channel's sales are
greater than one third of the total sales. By using the new clause, the
channel_summary data is calculated just once, avoiding an extra scan
through the large sales table.
Although the primary purpose of the WITH clause is performance
improvement, it also makes queries easier to read, write and maintain.
Rather than duplicating a large block repeatedly through a SELECT
statement, the block
is localized at the very start of the query. Note that the clause can
define multiple subquery blocks at the start of a SELECT statement:
when
several blocks are defined at the start, the query text is greatly
simplified
and its speed vastly improved.
Another Example:
Here’s a lengthy query that finds all departments whose total salary
bill is more than 45% of the entire company’s salary bill:
Select dname, sum(sal) as dept_total
From emp, dept
Where emp.deptno=dept.deptno
Group by dept.dname
Having sum(sal) >
(select sum(sal) *0.45
from emp, dept
where emp.deptno=dept.deptno)
order by sum(sal);
Notice in particular that the “sum(sal)” calculation appears several
times in this query: which means that the computation of the salary
summaries
has to be performed multiple times, too. Well, new in 9i, you can
write the same query like this:
With
deptsum as (
select dname, sum(sal) as dept_total
from emp, dept
where emp.deptno=dept.deptno
group by dept.dname),
grandtotals as (
select sum(sal) as grand_total from emp)
select dname, dept_total from deptsum
where dept_total>
(select (grand_total*.45) from grandtotals)
order by dept_total;
The neat thing here is that we put the summaries up front, giving them
easy names to work with (in this case “deptsum” and
“grandtotals”). Each salary summary (one in total and one by
department) is then pre-computed as those named SQL blocks are
processed –and no matter how many times your main query then references
those summaries, they don’t need to be re-computed.
Doing things this way also means rather tidier syntax –your main query
just references the potentially complex sub-queries and computations
via an alias name as specified in the ‘with’ section. In effect,
the
named entities at the top of the ‘with’ section can be referenced as
though
they were just another table later on in the query.
Index Merge
The index merge allows you to merge two separate indexes and go
directly to a table instead. Consider as an example a table with
1,000,000 records. The table is 210 MB.
create index year_idx on test2 ( year
);
create index state_idx on test2 (
state );
select /*+ rule index(test2) */
state, year
from test2
where year = ‘1972’
and state = MA
SELECT STATEMENT Optimizer=HINT: RULE
TABLE ACCESS (BY INDEX ROWID) OF ‘TEST2’
INDEX (RANGE SCAN) OF ‘STATE_IDX’ (NON-UNIQUE)
Elapsed time: 23.50 seconds
select /*+ index_join(test2 year_idx
state_idx) */
state, year
from test2
where year = ‘1972’
and state = MA
SELECT STATEMENT Optimizer=CHOOSE
VIEW OF ‘index$_join$_001’
HASH JOIN
INDEX (RANGE SCAN) OF ‘YEAR_IDX’ (NON-UNIQUE)
INDEX (RANGE SCAN) OF ‘STATE_IDX’ (NON-UNIQUE)
Elapsed time: 4.76 seconds
Index Skip Scans
"Index skip scans" are a new performance feature in Oracle9i which can
provide significant benefits to any database application which uses
composite indexes. In releases prior to Oracle9i, a composite index
would only be used for a given query if either the leading column (or
columns) of the index was included in the WHERE-clause of the query, or
(less often)
the entire index was scanned.
With Oracle9i, a composite index can be used even if the leading
column(s) are not accessed by the query, via a technique called an
'index skip scan'. During a skip scan, the composite index is accessed
once for
each distinct value of the leading column(s). For each distinct value,
the index is searched to find the query's target values. The result is
a scan that skips across the index structure.
Index skip scans provide two main benefits. First, index skip scans can
improve the performance of certain queries, since queries which
previously required table scans may now be able to take advantage of an
existing index. Second, index skip scans may allow an application to
meet its performance goals with fewer indexes; fewer indexes will
require less storage space and may improve the performance of DML and
maintenance operations. Index Skip Scan is good if the table is
analyzed and is better if the first column has low cadinality.
To illustrate index skip scans, suppose that we have a 2.5-million-row
table containing information on automobile registrations:
REGISTERED_OWNERS(
STATE VARCHAR2(2) NOT NULL,
REGISTRATION# VARCHAR2(10) NOT NULL,
FIRST_NAME VARCHAR2(30),
LAST_NAME VARCHAR2(30),
MAKE VARCHAR2(30),
MODEL VARCHAR2(15),
YEAR_MFG NUMBER,
CITY VARCHAR2(30),
ZIP NUMBER)
Furthermore, suppose that this table has a composite index on
(STATE, REGISTRATION#). The following query will be able to take
advantage of the index using
index skip scans:
SELECT first_name, last_name, zip
FROM REGISTERED_OWNERS WHERE
registration# = '4FBB428'
Index skip scans can be extremely useful, and they are transparent
to users and applications. This feature can improve performance of many
database workloads without requiring the addition of any new indexes
(and in some cases may even allow indexes to be removed without
significantly impacting performance).
Monitoring_Index_Usage
By using the 'alter index … monitoring usage' statement you can
see if a particular index is being used.
Query v$object_usage as the owner of those indexes to see if the index
has been used and during what
time period it was monitored, it will show you just whether the index
has been used or not; it will not show you how many times the index was
used or when it was last used.
To stop monitoring an index, type:
ALTER INDEX index_name NOMONITORING USAGE;
This script activates index monitoring on an entire schema (must be
run as System)
set echo off
set feedback off
set pages 0
set verify off
accept idx_owner prompt "Enter the schema name: "
spool monitor_idx.tmp
select 'alter index '||owner||'.'||index_name||' monitoring usage;'
from dba_indexes
where owner = UPPER('&idx_owner');
spool off
set echo on
set feedback on
set pages 60
spool monitor_idx.log
@monitor_idx.tmp
spool off
A sample query on V$OBJECT_USAGE confirms that monitoring has been
activated (must be run as the OWNER
of indexes)
set linesize 92
set pagesize 9999
select substr(index_name,1,25) index_name,
substr(table_name,1,15) table_name,
MONITORING, USED,
START_MONITORING, END_MONITORING
from v$object_usage
order by used;
INDEX_NAME
TABLE_NAME
MON USED
START_MONITORING END_MONITORING
------------- -------------------- --- ----
------------------- --------------
ITEM_ORDER_IX
ORDER_ITEMS
YES NO 08/15/2001 11:23:10
INVENTORY_PK
INVENTORIES
YES YES 08/15/2001 16:51:32
PROD_NAME_IX PRODUCT_DESCRIPTIONS
YES NO 08/15/2001 16:50:32
ORDER_P
ORDERS
YES YES 08/15/2001 17:10:32
PRD_DESC_PK
PRODUCT_DESCRIPTIONS YES YES 08/15/2001
17:13:32
Another useful index, is this one, to check ALL the indexes on the DB
select u.name
"OWNER",
io.name "INDEX_NAME",
t.name "TABLE_NAME",
decode(bitand(i.flags, 65536), 0, 'NO', 'YES') "MONITORING",
decode(bitand(nvl(ou.flags,0), 1), 0, 'NO', 'YES') "USED",
ou.start_monitoring "START_MONITORING",
ou.end_monitoring "END_MONITORING"
from sys.obj$
io, sys.obj$ t, sys.ind$ i, sys.object_usage ou, sys.user$ u
where t.obj#
=i.bo#
and
io.owner# = u.user#
and
io.obj# = i.obj#
and
u.name not in
('SYS','SYSTEM','XDB','WMSYS','ORDSYS','OUTLN','MDSYS','CTXSYS')
and
i.obj# =ou.obj#(+)
order by
u.name, t.name, io.name;
This script stops index monitoring on an entire schema.(must be run as
System)
set echo off
set feedback off
set pages 0
set verify off
accept idx_owner prompt "Enter the schema name: "
spool stop_monitor_idx.tmp
select 'alter index '||owner||'.'||index_name||' nomonitoring usage;'
from dba_indexes
where owner = UPPER('&idx_owner');
spool off
set echo on
set feedback on
set pages 60
spool stop_monitor_idx.log
@stop_monitor_idx.tmp
spool off
Rebuilding Indexes
Beginning in 9i, you can rebuild your indexes online and compute
statistics at the same time. Online index rebuild is also available for
reverse key indexes, function-based indexes and key compressed indexes
on both regular tables and index organized tables (including secondary
indexes). In previous releases, you could either issue one of the
following:
alter index index_name rebuild online
or
alter index index_name rebuild compute statistics
However it was not possible to combine these statements into one
operation. In 9i, you can issue:
alter index index_name rebuild compute statistics
online;
This allows your current users to be able to access the original index
while it is being rebuilt and having statistics get generated against
it. When you rebuild your indexes online, the new index is built
within your index tablespace while the old index is still being used.
The online option specifies that DML operations on the table or
partition
are allowed during rebuilding of the index. After the new index is
completed
the old index is dropped. When you rebuild your indexes and do not
specify the online option, the database locks the entire table from
being used while the index is being rebuilt. This option can also be
combined with the nologging attribute to avoid generating redo when
rebuilding your indexes (ex: alter index index_name rebuild compute
statistics online nologging;)
Rebuilding Tables
A new package DBMS_REDEFINITON has been introduced. Online table
rebuilds are achieved by utilizing incrementally maintainable
materialized views behind the scenes. This places some interesting
restrictions on the online rebuild operation:
The table must have a primary key
- Tables with materialized views and snapshot logs cannot be rebuilt
online (ORA-12091 Cannot redefine table with materialized views)
- MVIEW container tables and AQ tables cannot be reorganized online
- IOT overflow tables cannot be reorganized online
- Tables containing user-defined types, bfile or long columns cannot be
rebuilt online
To rebuild a table online:
1- Verify that the table can in fact be rebuilt online without falling
foul of the above constraints
DBMS_REDEFINTION.CAN_REDEF_TABLE(
'SCOTT' , 'EMP');
2- Create the 'new' table in the same schema (Eg. with extra column,
partitioning or storage)
3- Invoke the packaged procedures required to carry out the online
operation:
exec
dbms_redefinition.start_redef_table( ... ); # Begin
rebuild
exec
dbms_redefinition.sync_interim_table( ... ); # synch
interim
mview with original table if required
exec
dbms_redefinition.finish_redef_table( ... ); # End rebuild
Beware of the following gotchas:
- Constraints must be defined on the holding
table as this will become the new table. This means that indexes
supporting
constraints will have to be renamed
- Same goes for triggers
- Foreign key constraints created on the
holding table must be DISABLED (they will be automatically enabled when
the operation completes)
Finally, there is a fair bit of scope for things to go wrong during the
whole procedure. Depending at which point this happens, you could end
up with a rogue materialized view hanging around which will prevent you
from attempting another rebuild. To tidy things up after a failed
rebuild, you can execute the following procedure:
exec
dbms_redefinition.abort_redef_table( ... );
Get Object
Creation Info
The DBMS_METADATA package is a powerful tool for obtaining the complete
definition of a schema object. It enables you to obtain all of the
attributes of an object in one pass. The object is described as DDL
that can be used to (re)create it. It has 19 Total Procedures and
Functions. Examples:
Table Example
To punch off all table and indexes for the EMP table, we execute
dbms_metadata. get_ddl, select from DUAL, and providing all required
parameters.
set heading off;
set echo off;
Set pages 999;
set long 90000;
spool ddl_list.sql
select dbms_metadata.get_ddl('TABLE','DEPT','SCOTT') from dual;
select dbms_metadata.get_ddl('INDEX','DEPT_IDX','SCOTT') from dual;
spool off;
Another Table Example (Create and GET_DDL)
CREATE TABLE temp (temp VARCHAR2(10) NOT NULL);
SET SERVEROUTPUT ON SIZE 1000000
DECLARE
CURSOR
select_table IS
SELECT table_name
FROM user_tables
WHERE table_name = 'TEMP';
temp1
VARCHAR2(30);
temp2
VARCHAR2(4000);
BEGIN
OPEN
select_table;
FETCH
select_table INTO temp1;
temp2 :=
SUBSTR(dbms_metadata.get_ddl('TABLE',
temp1), 1, 250);
dbms_output.put_line('SQL: ' || temp2);
END;
/
Output:
SQL:
CREATE TABLE "TREZZOJ"."TEMP"
( "TEMP" VARCHAR2(10) NOT NULL ENABLE
) PCTFREE 10
PCTUSED 40 INITRANS 1 MAXTRANS 255 LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1
MAXEXTENTS 2147483645 PCTINCREASE 0
FREELISTS 1 FREELIST GROUPS
Procedure Example (Create and GET_DDL)
CREATE OR REPLACE PROCEDURE abc AS
BEGIN
NULL;
END abc;
DECLARE
CURSOR
select_procedure IS
SELECT object_name
FROM user_objects
WHERE object_type = 'PROCEDURE';
temp1
VARCHAR2(30);
temp2
VARCHAR2(4000);
BEGIN
OPEN
select_procedure;
FETCH
select_procedure INTO temp1;
temp2 :=
SUBSTR(dbms_metadata.get_ddl('PROCEDURE',temp1), 1, 250);
dbms_output.put_line('SQL: ' || temp2);
END;
/
Output:
SQL:
CREATE OR REPLACE PROCEDURE "TREZZOJ"."ABC" AS
BEGIN
NULL;
END abc;
The output can be Directed to a Flat File using the UTL_FILE Package or
Inserted into a Table for Later Use
Schema Example
Now we can modify the syntax to punch a whole schema. It us
easily done by selecting dbms_metadata. get_ddl and specifying
USER_TABLES and USER_INDEXES. :
set pagesize 0
set long 90000
set feedback off
set echo off
spool scott_schema.sql
connect scott/tiger;
SELECT DBMS_METADATA.GET_DDL('TABLE',u.table_name) FROM
USER_TABLES u;
SELECT DBMS_METADATA.GET_DDL('INDEX',u.index_name) FROM
USER_INDEXES u;
spool off;
SQL*Plus Web Reports
Both Oracle8i and Oracle9i allow the generation of HTML directly from
SQL*Plus. This can be used to build complete reports, or output to be
embedded in larger reports. The MARKUP HTML ON statement tell SQL*Plus
to produce HTML output. The SPOOL ON option of this command indicates
that the results should be encapsulated in
<html><body>...</body></html> tags. If a
complete HTML page is not required the SPOOL OFF option can be used.
The following example displays the contents of the SCOTT.EMP table as a
HTML table:
SET ECHO OFF
SET MARKUP HTML ON SPOOL ON
SPOOL emp1.html
SELECT * FROM emp;
SPOOL OFF
SET MARKUP HTML OFF
SET ECHO ON
Alternatively, the script can save as EmpHTMLReport.sql and run from
the command line:
sqlplus scott/tiger@w2k1 @EmpHTMLReport.sql
Alternatively, an individual query can be saved to EmpSQL.sql and run
with the appropriate command line parameters:
sqlplus -S -M "HTML ON" scott/tiger@w2k1 @EmpSQL.sql>emp3.html
Table Function
A table function is a function that produces a collection of rows that
can be queried just like a table. The collection of rows is either a
nested table or a VARRAY. It eliminates the need to store
intermediate data into temporary table as the data is directly passed
to next stage. The following is an example of table function that
returns the list of authors of the given book. The names of authors are
stored in AUTHORS column of BOOKS table. Author names are separated by
comma (,). Table function returns the list of author names in the form
of a table, which can be used just like a table in SELECT.
First let us create required types and table.
create or replace type authors_table as table of varchar2(30);
The above command creates AUTHORS_TABLE, which is a collection of
strings.
create table books
( title varchar2(30),
authors varchar2(500)
);
BOOKS table contains title and list of authors of the book. Author
names are separated by comma. The following is sample data of
BOOKS table.
insert into books values ('uml user guide','grady booch, james
runbaugh, ivar jacobson');
insert into books values ('core java','horstmann,cornell');
insert into books values ('oracle8i comp. ref.','kevin loney, george
koch');
The following table function takes title and returns the names of
author in the form of AUTHORS_TABLE.
create or replace function getauthors(p_title varchar2)
return authors_table
is
atab authors_table;
al varchar2(500);
p integer;
a varchar2(30);
begin
atab := authors_table();
select authors into al
from books where title = p_title;
p := instr(al,',');
while p <> 0
loop
a :=
substr(al,1,p -1);
atab.extend;
atab(atab.last) := a;
al := substr(
al, p+1);
p :=
instr(al,',');
end loop;
atab.extend;
atab( atab.last) := al;
return atab;
end;
/
Once function is created then it can be called using TABLE keyword as
following in SELECT command.
select b.title, a.* from books b,
table(getauthors(b.title)) a;
TITLE
COLUMN_VALUE
------------------------------ ------------------------------
UML User
Guide
Grady Booch
UML User
Guide
James Runbaugh
UML User
Guide
Ivar Jacobson
Core
Java
Horstmann
Core
Java
Cornell
Oracle8i Comp.
Ref.
Kevin Loney
Oracle8i Comp.
Ref.
George Koch
QUIESCING
A Database
Quiescing a database is a powerful feature that helps Oracle DBAs to do
certain kinds of work they would not be able to do otherwise, without
putting the database in the restricted mode. Using this feature, after
logging in to the SYS or SYSTEM account, the DBA can do queries,
PL/SQL, and other transactions. For other users, the system will seem
to be inactive or in the HALT stage. All of the user's transactions
will be kept in a suspended state and will resume automatically, once
the DBA puts the system back into a normal state. You can now quiesce
the instance (prevent any new
transactions from starting) with the ALTER SYSTEM QUIESCE RESTRICTED
command. However, transactions already in progress will be allowed to
continue; you'll need to wait for
these transactions to complete before the instance will be trully
quiesced. The database will be quiesed once the user resolves all the
active transaction either by COMMIT or ROLLBACK.
How do you determine what sessions are connected and waiting for
UNQUIESCING the database?
To determine this issue the following query:
SELECT
SID,EVENT,TOTAL_WAITS,TIME_WAITED "TIME WAITED[100 OF SEC]",
AVERAGE_WAIT FROM V$SESSION_EVENT
WHERE EVENT='wait for possible
QUIESCE finish'
/
SID
EVENT
TOTAL_WAITS
Time Waited[100 of Sec] AVERAGE_WAIT
---
----------------------------------
-----------
----------------------- ------------
6 wait for possible
QUIESCE
finish
412
126532 307
More Changes
With the introduction of default temporary tablespace, the SYSTEM
tablespace is no longer used as the default storage location for
temporary data. Oracle9i also allows for better control over database
downtime by
enabling administrators to specify the mean time to recover (MTTR) from
system failures in number of seconds. This feature coupled with more
dynamic initialization parameters help administrators further improve
database availability.
The Enterprise Manager interface to the MTTR Advisory helps you select
the best MTTR time for your needs by reporting the advice statistics in
a graphical as well a tabular format. The MTTR Advisor is available
from Enterprise Manager by selecting:
Databases > Database Name > Instance > Configuration >
Recovery tab > Advice next to Desired mean time to recover.
Oracle9i also supports databases created with multiple block sizes, and allows administrators to configure corresponding 'sub caches' within the buffer cache for each block size. This capability allows administrators to place objects in tablespaces of appropriate block size in order to improve I/O performance, and also allows tablespaces to be transported between different databases, for example, from an OLTP environment to a Data Warehousing environment.
To ease backup and recovery operations, Recovery Manager in
Oracle9i enables one time backup configuration, automatic management of
backups and archived logs based on a user specified recovery window,
restartable backups and restores, and test restore/recovery. Recovery
Manager implements a recovery window, a new policy to control when
backups expire. This allows
administrators to establish a period of time during which it will be
possible to discover logical errors and fix the affected objects by
doing
a database or tablespace point-in-time recovery.
Recovery Manager will also automatically expire backups that are no
longer required to restore the database to a point-in-time within the
recovery window. These features are designed to reduce the time and
effort spent by administrators
in performing routine backup tasks by providing for automation for most
commonly performed tasks. The new controlfile autobackup feature also
allows for restoring/recovering a database even when a Recovery Manager
repository is not available. Recovery Manger in Oracle9i also features
enhanced reporting, a more user friendly interface and the ability to
specify a highly flexible backup configuration to suit varied
requirements depending on the nature of database and business
needs.
Database Suspend/Resume - This feature allows you to suspend
database
activity by stopping I/O to all datafiles and queuing any further I/O
requests. When ready, you can then resume database operations and the
system will re-activate all pending I/O requests in the order they were
queued. This is extremely useful for system backups that involve
splitting mirrored disks.
"alter database end backup" command - takes all datafiles out of backup
mode in a single command. This new command allows you to script
database crash recovery procedures without the need for user
intervention.
Scrollable cursors - New cursor type in which you can move both
forwards and backwards through the result set. Can use either absolute
row numbers or relative row number offsets depending on your position
in the result set. Additional memory usage enhancements have been
included for greater efficiency.
Compile
Invalid Objects for a full Schema
exec dbms_utility.compile_schema('SCHEMA_NAME');
Cached Execution Plans
The V$SQL_PLAN view can be used to view the execution plans of recent
SQL statements. It contains similar information to an EXPLAIN PLAN,
except the EXPLAIN PLAN is a theoretical execution plan, whereas this
view contains the actual execution plans used by the server
Write/Delete Files to the OS
UTL_FILE.FREMOVE, UTL_FILE.FRENAME, UTL_FILE.FCOPY and UTL_FILE.FGETATTR
These are new packages that let you create, delete, etc files directly
from the OS. You just need to use one command to define the location of
those files. You will need to have 'GRANT CREATE ANY DIRECTORY TO'
privilege. There are some limitations like: UTL_FILE can only see
the file system on the server itself. UTL_FILE is run in the
Oracle dedicated/shared server which resides on the server -- it is not
running on the client side -- it cannot see the file systems the client
can see. For utl_file to write to a netware volumn -- that volumn
would have to be mounted as a unix file system and accessible to the
server itself.
A good example is HERE and on http://otn.oracle.com/oramag/utl_file.html
Oracle Shared Server
Oracle Shared Server is the new name for Oracle Multi-threaded Server
(MTS) and includes several new features.
In MTS, clients contacted the listener asking for a connection. The
listener sent the address of a dispatcher to the client, who then
contacted the dispatcher directly to confirm the connection. In Oracle
Shared Server the client contacts the listener to ask for a connection
resulting in a connection socket being established between the listener
and the client. The listener then hands this socket to the relevant
dispatcher
to allow instant communication between the client and the dispatcher.
This process is called a Direct Handoff.
Prior to Oracle9i, dispatchers handled network and database events
separately. Network events were handled using the UNIX system call
poll() via the network services, while database event were handled by
the Virtual Operating System (VOS), an internal abstraction layer not
visible to the DBA. Polling and coordinating both event models wasted
time. In Oracle9i the Common Event Model has poll() incorporated into
the VOS layer on the database so there is no need to poll the network
services anymore.
Performance Manager, part of the Diagnostics Pack in Oracle Enterprise
Manager (OEM), provides graphical monitoring the shared server. This
can
be done with an overall view, or detailed to the level of dispatchers,
shared server processes and listeners. In addition Performance Manager
can view the SQL statements fired for each session and provide help in
tuning the Shared Server parameters
Recovery
+ More fault tolerance
+ Ignore corruption and carry on
+ Back out of botched session
+ Selective skipping of blocks
+ Only those that apply
+ Online table re-org
+ Rollback managed in the tablespace
+ Standby database failover and failback
+ Different block size by tablespace
Bitmap join indexes
Bitmap Join Indexes are a new feature in 9i, but you might well ask,
“What the hell is a bitmap join index?”The short answer is: it’s an
index built on table A based on some value in table B, imagine the
following tables:
SALES:
ORDNO CUSTCODE VALUE
101 A 103.40
102 A 123.90
103 B 9832.90
104 C 546.75
105 D 789.34
CUSTOMERS:
CUSTCODE NAME
LOCATION
A W.H.Smith &
Sons Ltd Sydney
B Boots the
Chemist Adelaide
C
Waterhouse
Melbourne
D
Priceline
Sydney
Now suppose that you want to know the total value of sales in
Sydney. You obviously can’t get ‘Sydney’ out of the Sales
table. But if you were to join the two tables together via the
Custcode, then you could do it. Trouble is, to do that join, we’d have
to read the entire Customer table –which, in this case wouldn’t be too
bad. But if there were a million of customers that would be one
hell of a full table scan. New in 9i, we
can create a bitmap index on the SALES table, based on the Location
column
in the Customers table. The syntax would be:
Create bitmap index cust_location
On sales(customers.city)
From sales, customers
Where sales.Custcode = customers.custcode;
That would create a bitmap index looking a bit like this:
Leaf Node 1: SYDNEY 1001
Leaf Node 2: ADELAIDE 0100
Leaf Node 3: MELBOURNE 0010
Now, a select sum(sales.value) from sales, customers where
customers.location =’SYDNEY’ can be answered by querying the sales
table and the bitmap index containing the location data. The
query doesn’t even need to
touch the actual customers table at all –and that’s a potentially huge
benefit
in the right circumstances.
In effect, therefore, a bitmap join index is rather like a
function-based index (which is a b-tree index feature introduced in
8i). It means that a select for a computed (or implied) value
doesn’t need to reference the lookup table itself, but can use the main
table and the highly compressed and efficient bitmap index which
references the lookup table.
When you start to consider that a bitmap join index can be based on
more than 1 table, the advantages can be huge: “test in table A for
records
that match criterion 1 in table B AND criterion 2 in table C” –all
without
touching wither tables B or C at all.
Are there any drawbacks? Yes, naturally: bitmap indexes of any
sort and DML don’t exactly sit comfortably together. What’s
worse,
with a bitmap join in place, only one of the tables can be updated at
one
time (simultaneous updates on tables A, B and C will be queued).
What’s
more, the joining field (in our case earlier, CUSTCODE) must be
the
primary key column (or at least be declared unique).
Materialized views
More sophisticated query rewite
Fast refresh opportunities
Explicitly Named Indexes On Keys
In Oracle9i the index used to support Primary and Unique keys can be
defined independently of the constraint itself by using the CREATE
INDEX syntax within the USING UNDEX clause of the CREATE TABLE
statement:
CREATE TABLE employees
(
empno NUMBER(6),
name VARCHAR2(30),
dept_no NUMBER(2),
CONSTRAINT emp_pk primary key(empno)
USING INDEX
(CREATE INDEX emp_pk_idx ON employee(empno))
);
The constraint can subsequently be dropped without dropping the index
using either syntax:
ALTER TABLE employees DROP PRIMARY KEY KEEP INDEX;
ALTER TABLE employees DROP CONSTRAINT empno_pk;
Share Locks On Unindexed FKs
In previous versions a share lock was issued on the entire child table
while the parent table was being updated if the foreign key between
them was unindexed. This had the affect of preventing DML operations on
the child table until the parent table transaction was complete.
In Oracle9i this situation has been altered such that a table level
share lock is issued and instantly released. This action allows Oracle
to check that there are no pending changes on the child table, but the
instant release means that DML can resume almost instantly once the
parent table update has initiated. If multiple keys are updated Oracle
issues a share lock and release on the child table for each row.
PK Lookup During FK Insertion
During insertions foreign key values are checked against the primary
keys of referenced tables. This process is optimized in Oracle9i by
caching the first 256 PK values of the referenced table on insertion of
the second record of a multiple insert. The process is done on the
second record to prevent the overhead of managing the cache on a single
insert.
Function Based Index Enhancements
Function Based Indexes are now capable of doing an index-only scan. In
previous versions this was only possible if the index creation
statement explicitly prevented NULL values. Since each built-in
operator
knows implicitly whether it can produce null values when all it's input
parameters are not null, Oracle can deduce if nulls can be produced and
therefore decide if index-only scans are possible based on the columns
queried using the function based index.
SELECT .. FOR UPDATE Enhancements
Selecting a record for update that is already locked causes the current
session to hang indefinitely until the lock is released. If this
situation is unacceptable the NOWAIT keyword can be used to instantly
return an error if the record is locked. Oracle9i adds more flexibility
by allowing the programmer to specify a maximum time limit to wait for
a lock before returning an error. This gets round the problem of
indefinite
waits, but reduces the chances of lock errors being returned:
SELECT * FROM employees
WHERE empno = 20
FOR UPDATE WAIT 30;
New Built-In Functions
List of New Functions
asciistr
bin_to_num
coalesce compose
current_date
current_timestamp dbtimezone
decompose
existsnode extract
(datetime) extract (xml)
first
from_tz
group_id
grouping_id last
localtimestamp nullif
percentile_cont percentile_disc
rawtonhex
rowidtonchar
sessiontimezone
sys_connect_by_path
sys_dburigen
sys_extract_utc
sys_xmlagg sys_xmlgen
systimestamp to_char
(character) to_clob
to_dsinterval
to_nchar(character) to_nchar (datetime) to_nchar (number)
to_nclob
to_timestamp
to_timestamp_tzto
to_yminterval treat
tz_offset
unistr
width_bucket
New NULLIF Type Functions
Compares given two values and if they are same then return null
otherwise returns first expression.
NULLIF (expr1, expr2)
The following command displays employee number, name, and old job if it
is different from current job and current job
New COALESCE_Functions
Returns the first not null value in the list of values. At least one
expression out of the given expressions must not be null. The function
is extended version of NVL function
Example:
The following query returns the selling price of the product. If
dicount is not null then remove discount from the price, otherwise if
any offer price is available give at the offer price, otherwise sell
the product at the original price.
select prodid,name, coalesce( price - discount, offerprice,
price) "Selling Price"
from products;
New BIN_TO_NUM Function
Convert the given bit pattern to a number.
The following example returns 15 as binary 1111 is equivalent to 15.
select bin_to_num(1,1,1,1) from dual;
BIN_TO_NUM(1,1,1,1)
-------------------
15
New EXTRACT Function
Extracts and returns the value of the specified datetime field from
a datatime value.
EXTRACT ( datatimefield FROM
datetime)
The following example returns year from the current date.
select extract( year from sysdate) from dual;
EXTRACT(YEARFROMSYSDATE)
------------------------
2002
New Datetime Functions
1. CURRENT_DATE returns the current date in the session time
zone.
2. CURRENT_TIMESTAMP returns a TIMESTAMP WITH TIME ZONE with
current date & time in session time zone.
3. DBTIMEZONE returns the time zone offset of the database time
zone.
4. EXTRACT (datetime) returns the specified date or time field
from a datetime expression or interval expression.
5. FROM_TZ converts a TIMESTAMP value in a time zone to a
TIMESTAMP WITH TIME ZONE value.
6. LOCALTIMESTAMP returns a TIMESTAMP value with the current date
and time in the session time zone.
7. SESSIONTIMEZONE returns the time zone offset of the current
session?s time zone.
8. SYS_EXTRACT_UTC extracts the UTC (Coordinated Universal Time)
from a TIMESTAMP WITH TIME ZONE.
9. SYSTIMESTAMP returns a TIMESTAMP WITH TIME ZONE value with
system date and time zone of the database.
10. TO_CHAR (datetime) converts dates or timestamp?s to a
VARCHAR2 value. Note: timestamp conversion added.
11. TO_DSINTERVAL converts a character string to an INTERVAL DAY
TO SECOND data type.
12. TO_NCHAR (datetime) converts dates, timestamp?s, or
interval?s to a NVARCHAR2 string value.
13. TO_TIMESTAMP converts CHAR, VARCHAR2, NCHAR, or NVARCHAR2
characters to a TIMESTAMP value.
14. TO_TIMESTAMP_TZ converts a character string to a TIMESTAMP
WITH TIME ZONE value.
15. TO_YMINTERVAL converts a character string to an INTERVAL YEAR
TO MONTH data type.
16. TZ_OFFSET returns the time zone offset for the values on that
date. (Daylight savings time affects time zone offset)
Aggregate and Analytical Functions
1. FIRST returns the first row of a sorted group, but the needed
value is not the sort key.
2. LAST returns the last row of a sorted group, but the needed
value is not the sort key.
• Note: the FIRST and LAST functions eliminate the need for self-joins
or views (enabling better performance).
3. GROUP_ID distinguishes duplicate groups resulting from a GROUP
BY specification.
4. GROUPING_ID returns a number corresponding to the GROUPING
function bit vector associated with a row.
5. PERCENTILE_CONT is an inverse distribution function that
assumes a continuous distribution model.
6. PERCENTILE_DISC is an inverse distribution function that
assumes a discrete distribution model.
7. WIDTH_BUCKET is used for constructing histograms whose
intervals have identical size.
Object Functions
1. SYS_TYPEID returns the typeid of the most specific type of the
operand (must be an object type).
2. TREAT function changes the declared type of an
expression. Note: needs execute object privilege on the type.
Unicode Functions
1. COMPOSE takes a string in any data type, and returns a Unicode
string in its fully normalized form in the same character set.
For
example an 'o' qualified by an umlaut will be returned as o-umlaut.
2. DECOMPOSE takes a string in any data type, and returns a
Unicode string in canonical decomposition in the same character
set. For example o-umlaut is returned as 'o' followed by an
umlaut.
3. INSTRC searches a string for a substring using Unicode
complete characters.
4. INSTR2 searches a string for a substring using UCS2
codepoints.
5. INSTR4 searches a string for a substring using UCS4
codepoints.
6. LENGTHC returns the length of a character string using Unicode
complete characters.
7. LENGTH2 returns the length of a character string using UCS2
codepoints.
8. LENGTH4 returns the length of a character string using UCS4
codepoints.
9. SUBSTRC returns a portion of a string using Unicode complete
characters.
10. SUBSTR2 returns a portion of a string using UCS2 codepoints.
11. SUBSTR4 returns a portion of a string using UCS4 codepoints.
12. UNISTR converts a character string into the database Unicode
character set.
Conversion Functions
1. ASCIISTR takes as its argument a string in any character set
and returns an ASCII string in the database character set.
2. BIN_TO_NUM converts a bit vector (0s and 1s) to its equivalent
number.
3. CAST converts one built-in data type or collection-typed value
into another built-in data type or collection-typed value. Note: the
Oracle8i SQL Reference had a CAST expression.
4. DECODE compares an expression to a list of search
values. If a search value is found, the corresponding result is
returned. Note: the Oracle8i SQL Reference had a DECODE
expression.
5. NCHR returns the character having the binary equivalent in the
national character set. Equivalent to CHR function with the USING
NCHAR_CS
clause.
6. RAWTONHEX converts raw to an NVARCHAR2 character value
containing its hexadecimal equivalent.
7. ROWIDTONCHAR converts a rowed value to NVARCHAR2 value that is
18 characters long.
8. TO_CHAR (character) converts NCHAR, NVARCHAR2, CLOB, or NCLOB
data to the database character set.
9. TO_CLOB converts NCLOB values to CLOB values (converts from
national character set to database character set).
10. TO_NCHAR (character) converts CHAR, VARCHAR2, CLOB, or NCLOB
data to the national character set.
11. TO_NCHAR (number) converts a number to a NVARCHAR2 string
value.
12. TO_NCLOB converts character data from the database character
set to the national character set.
Data Segment Compression
Data compression reduces the amount of data being stored (faster full
table scans), reduces
memory usage (more data per memory block), and increases query
performance. It's very good for lookup tables and for reading systems,
so it's very beneficial for DW Systems.
Data compression in Oracle9I Release 2 is performed at the block level.
Administrators are able to compress entire tables and specific
table partitions. The COMPRESS attribute
can be specified in the CREATE
TABLE, CREATE TABLESPACE and CREATE
TABLESPACE …. PARTITION statements.
Block compression works by eliminating repeating column values. The
more
repeating values the columns have the greater the compression ratio
becomes.
Administrators are able to achieve higher compression ratios by sorting
the rows on a column that has a poor cardinality (high number of
repeating values).
Although UPDATE and DELETE operations can be performed on compressed
data in Oracle, the performance impact the compress and uncompress
operations have on those statements is yet to be determined. Oracle
recommends that compressed data be highly considered for data warehouse
environments because data block compression is highly optimized for
direct-load operations.
Note: tables with large amounts of DML operations are not good
candidates for compression. Syntax is too easy:
create table table2 COMPRESS tablespace users as
select * from table1;
or
create table (...) compress;
alter table AA compress; --this will not
reorganize the table, is just for new data
alter table AA move compress; -- this will
reorganize the table, reducing # of blocks
or
--Create a Compressed Tablespace so all its objects will be
compressed
create tablespace datacompress
datafile '.../...../datacompress.dbf' size 10M
default compress;
To ensure that data is actually compressed, you need to use a proper method to load or insert data into the table. Data compression takes place only during a bulk load or bulk insert process, using one of the following four methods:
Export And Import Enhancements In Oracle9i
A number of new features have been incorporated into the Export and
Import utilities including:
RESUMABLE
The RESUMABLE parameter is used to enable and disable resumable space
allocation. The default value for the parameter is 'N' so it must be
explicitly set to 'Y' for its associated parameters (RESUMABLE_NAME and
RESUMABLE_TIMEOUT) to be used.
The RESUMABLE_NAME parameter allows a text name to be assigned to the
transaction. This name can subsequently be used to identify suspended
transactions when queried using the USER_RESUMABLE or DBA_RESUMABLE
views.
The RESUMABLE_TIMEOUT parameter specifies the length of time the export
can be suspended for before the underlying transactions aborts.
STATISTICS
During Export this parameter specifies the type of database optimizer
statistics to generate when the exported data is imported. The options
are ESTIMATE (default), COMPUTE, and NONE. The export file may contain
some precalculated statistics along with the ANALYZE statements. These
statistics will not be used at export time if a table has columns with
system-generated names.
The precalculated optimizer statistics are flagged as questionable at
export time if:
During Import the parameter options are ALWAYS (default), NONE,
SAFE and RECALCULATE. The ALWAYS option imports all statistics, even
those that are questionable. The NONE option does not import or
recalculate statistics. The SAFE option imports statistics that are not
questionable, but recalculates those that are. Finally, the RECACULATE
option recaculates all statistics rather than importing them.
TABLESPACES
The TABLESPACES parameter is used to export all tables contained within
the specified tablespace or tablespace list. The table indexes are
included regardless of their tablespace location. Partitioned tables
are included if one or more partitions are located in the specified
tablespace. The EXP_FULL_DATABASE role is required to use TABLESPACES
parameter.
During Import the TABLESPACES parameter is used in conjunction with the
TRANSPORT_TABLESPACE parameter to specify the transportable tablespaces
that should be imported. This functionality is unchanged and has no
relationship to the TABLESPACES parameter used for export.
TABLES Pattern Matching
The TABLES parameter has been enhanced to allow pattern matching:
TABLES=(MYSCHEMA.ORDER%, MYSCHEMA.EMP%)
In the above example, any tables located in MYSCHEMA whose name begins
with ORDER or EMP will be exported.
Reduced Character Set Conversions
All user data in text related datatypes is exported using the character
set of the source database. If the character sets of the source and
target databases do not match a single conversion is performed.
The export and import process can require up to three conversions for
DDL. The DDL is exported using the character set specified by the
NLS_LANG environment variable. A character set conversion is performed
if this differs from the source database. If the export character set
differs from that specified by the import users NLS_LANG parameter
another conversion is performed. This conversion cannot be done for
multibyte character sets so these must match. A final characterset
conversion is needed if the import session and the target database have
different character sets. To eliminate possible data loss caused by
conversions, make sure all environments have matching character sets.
Enhanced Statistics Gathering
Oracle's query optimizer uses statistics about the objects in the
database (such as the number of rows in each table). These statistics
are gathered by database administrator's using the DBMS_STATS facility.
In Oracle9i it is now possible to automatically determine the
appropriate sampling percentage as well as the appropriate columns for
histograms. These enhancements simplify the database administrator's
task in gathering accurate statistics. There are also new system
statistics that are collected by the CBO to use and apprehend CPU and
system I/O information. For each plan candidate, the optimizer computes
estimates for I/O and CPU costs. Statistics are captured by setting the
STATISTICS_LEVEL dynamic initialization parameter to TRUE (default) or
ALL. Although a small area of the SGA is used for capturing this
information, there is no significant impact on overall database
performance.
Note:149560.1 Collect and Display System Statistics (CPU and IO) for
CBO usage
You can now use dbms_stats to estimate statistics based on a
specified sample size (from memory, earlier versions of dbms_stats only
did computation, not estimation, of statistics). DBMS_STATS also has a
number of new “method options” available. Basically, you can
specify “REPEAT”, “AUTO” or “SKEWONLY”.
“Repeat” simply repeats the collection method used to calculate
statistics previously –if there was no histogram before, there still
won’t be. If there was, there will be.
“Auto” means the package might decide to calculate new histograms if
it deems that the data is skewed sufficiently, and if it determines
that
sufficient prior use of the column as a predicate would warrant such a
calculation.
“Skewonly” means the package will create new histograms if it deems the
data to be skewed sufficiently, regardless of whether that column has
ever been a popular choice for a predicate in the past.
For example:
Execute dbms_stats.gather_schema_stats ( ownname => ‘SCOTT’,
method_opt => ‘for all columns size AUTO’)
or…
Execute dbms_stats.gather_schema_stats ( ownname => ‘SCOTT’,
method_opt => ‘for all columns size SKEWONLY’)
or…
Execute dbms_stats.gather_schema_stats ( ownname => ‘SCOTT’,
method_opt => ‘for all columns size 75’)
System Statistics Example:
Execute dbms_stats.gather_system_stats(interval => 60, stattab
=>’sometable’, statid => ‘OLTP daytime’)
That statement will cause statistics to be gathered for a period of 1
hour (60 minutes) after this command is issued, and the statistics will
be
stored in a table called ‘sometable’, with a unique identifier of ‘OLTP
daytime’.
The table in which statistics will be stored has to be created
beforehand, of course. There’s a procedure to do that, too:
execute
dbms_stats.create_stats_table(‘SYS’,’sometable’,’sometablespace’)
Once the statistics have been captured in the named table, they need
to be transferred into the data dictionary for them to actually
influence
the work of the optimiser.
Statistics Level Collection Parameter
The STATISTICS_LEVEL parameter was introduced in Oracle9i Release 2
(9.2) to control all major statistics collections or advisories in the
database. The level of the setting affects the number of statistics and
advisories that are enabled:
BASIC: No advisories or statistics are collected.
TYPICAL(default): The following advisories or statistics are collected:
ALL: All of TYPICAL, plus the following:
The parameter is dynamic and can be altered using:
ALTER SYSTEM SET statistics_level=basic;
ALTER SYSTEM SET statistics_level=typical;
ALTER SYSTEM SET statistics_level=all;
Current settings for parameters can be shown using:
SHOW PARAMETER statistics_level
SHOW PARAMETER timed_statistics
Oracle can only manage statistic collections and advisories whose
parameter setting is undefined in the spfile. By default the
TIMED_STATISTICS parameter is set to TRUE so this must be reset for it
to be controled by the statistics level, along with any other
conflicting parameters:
ALTER SYSTEM RESET timed_statistics scope=spfile sid='*';
This setting will not take effect until the database is restarted.
At this point the affect of the statistics level can be shown using the
following query:
COLUMN statistics_name FORMAT A30
HEADING "Statistics Name"
COLUMN session_status FORMAT
A10 HEADING "Session|Status"
COLUMN system_status
FORMAT A10 HEADING "System|Status"
COLUMN activation_level FORMAT A10 HEADING
"Activation|Level"
COLUMN session_settable FORMAT A10 HEADING
"Session|Settable"
SELECT statistics_name, session_status, system_status,
activation_level, session_settable
FROM v$statistics_level
ORDER BY statistics_name;
A comparison between the levels can be shown as follows:
SQL> ALTER SYSTEM SET statistics_level=basic;
System altered.
SQL> SELECT statistics_name, session_status, system_status,
activation_level, session_settable
FROM v$statistics_level
ORDER BY statistics_name;
Session System Activation
Session
Statistics
Name
Status Status
Level Settable
------------------------------ ---------- ---------- ----------
----------
Buffer Cache
Advice
DISABLED DISABLED TYPICAL
NO
MTTR
Advice
DISABLED DISABLED TYPICAL
NO
PGA
Advice
DISABLED DISABLED TYPICAL
NO
Plan Execution Statistics
DISABLED DISABLED
ALL YES
Segment Level Statistics
DISABLED DISABLED TYPICAL NO
Shared Pool
Advice
DISABLED DISABLED TYPICAL
NO
Timed OS
Statistics
DISABLED DISABLED
ALL YES
Timed
Statistics
DISABLED DISABLED TYPICAL
YES
8 rows selected.
SQL> ALTER SYSTEM SET statistics_level=typical;
System altered.
SQL> SELECT statistics_name, session_status, system_status,
activation_level, session_settable
FROM v$statistics_level
ORDER BY statistics_name;
Session System Activation
Session
Statistics
Name
Status Status
Level Settable
------------------------------ ---------- ---------- ----------
----------
Buffer Cache
Advice
ENABLED ENABLED
TYPICAL NO
MTTR
Advice
ENABLED ENABLED
TYPICAL NO
PGA
Advice
ENABLED ENABLED
TYPICAL NO
Plan Execution Statistics
DISABLED DISABLED
ALL YES
Segment Level Statistics
ENABLED ENABLED
TYPICAL NO
Shared Pool
Advice
ENABLED ENABLED
TYPICAL NO
Timed OS
Statistics
DISABLED DISABLED
ALL YES
Timed
Statistics
ENABLED ENABLED
TYPICAL YES
8 rows selected.
SQL> ALTER SYSTEM SET statistics_level=all;
System altered.
SQL> SELECT statistics_name, session_status, system_status,
activation_level, session_settable
FROM v$statistics_level
ORDER BY statistics_name;
Session System Activation
Session
Statistics
Name
Status Status
Level Settable
------------------------------ ---------- ---------- ----------
----------
Buffer Cache
Advice
ENABLED ENABLED
TYPICAL NO
MTTR
Advice
ENABLED ENABLED
TYPICAL NO
PGA
Advice
ENABLED ENABLED
TYPICAL NO
Plan Execution Statistics
ENABLED ENABLED
ALL YES
Segment Level Statistics
ENABLED ENABLED
TYPICAL NO
Shared Pool
Advice
ENABLED ENABLED
TYPICAL NO
Timed OS
Statistics
ENABLED ENABLED
ALL YES
Timed
Statistics
ENABLED ENABLED
TYPICAL YES
8 rows selected.
Oracle provides the V$STATISTICS_LEVEL view to provide information
on the status of statistics collection and advisories set by the
STATISTICS_LEVEL
parameter. V$STATISTICS_LEVEL contains a row for each statistic or
advisory
being collected.
Optimizer Dynamic Sampling
Oracle 9I Release 2 introduces optimizer dynamic sampling to overcome
the lack of accurate statistics on the objects being accessed. The
optimizer is now able to take a sampling of the data during access path
optimization. Administrators are able to activate dynamic sampling and
control the size of the dynamic sample taken by using the
OPTIMIZER_DYNAMIC_SAMPLING dynamic initialization parameter as a
throttle.
The values for OPTIMIZER_DYNAMIC_SAMPLING range from 0 to 10 with 0
telling the cost-based optimizer to not use dynamic sampling and the
value 10 telling the optimizer to sample all blocks in the table. The
DYNAMIC SAMPLING hint can be used at the statement level to override
the system setting defined by OPTIMZER_DYNAMIC_SAMPLING.
Oracle recommends that dynamic sampling only be used when the time
required to do the sample is a small fraction of the statement's total
execution time. It's a safe assumption that dynamic sampling will not
be used in many OLTP systems but it may find a home in a few decision
support and data warehouse environments.
Locally Managed System Tablespace
Locally managed tablespaces allow the Oracle system to automatically
manage an object's extents. Oracle states that locally managed
tablespaces provide increases in the concurrency and speed of space
operations and generally have a positive impact on application
performance.
Locally managed tablespaces track all extent information in the
tablespace itself, using bitmaps, resulting in the following benefits:
* Improved concurrency and speed of space operations, because
space allocations and deallocations predominantly modify locally
managed resources (bitmaps stored in header files) rather than
requiring centrally managed resources
such as enqueues
* Improved performance, because recursive operations that are
sometimes required during dictionary-managed space allocation are
eliminated
* Readable standby databases are allowed, because locally
managed temporary tablespaces (used, for example, for sorts) are
locally managed and
thus do not generate any undo or redo.
* Simplified space allocation when the AUTOALLOCATE clause is
specified, appropriate extent size is automatically selected
* Reduced user reliance on the data dictionary because necessary
information is stored in file headers and bitmap blocks
In Oracle9i Release 2, administrators are now able to create a
locally managed SYSTEM tablespace. The EXTENT MANAGEMENT LOCAL clause
can be used to create a locally managed SYSTEM tablespace during
database creation or administrators can use the stored procedure
DBMS_SPACE_ADMIN.TABLESPACE_MIGRATE_TO_LOCAL to migrate existing
dictionary managed tablespaces to locally managed. Once you create or
migrate to a locally managed SYSTEM tablespace, you are unable to
create any dictionary-managed tablespaces in the database.
Administrators must be careful when using the aforementioned package to
migrate SYSTEM tablespaces from dictionary managed to locally managed.
All tablespaces (except those containing UNDO segments) must be in READ
ONLY mode for the migration process to successfully execute. If Oracle
finds any tablespaces in READ WRITE mode, the error message states that
the tablespaces must be placed in READ ONLY mode.
The problem is that if the administrator places any dictionary managed
tablespaces in READ ONLY mode, they will be unable to place them in
READ WRITE mode after the SYSTEM tablespace is converted to locally
managed. Administrators desiring to migrate their SYSTEM tablespaces to
locally managed must migrate all READ WRITE dictionary managed
tablespaces to locally managed tablespaces BEFORE MIGRATING THE SYSTEM
TABLESPACE.
The LOCALLY MANAGED value is the default setting in the Storage tab for
all tablespaces, including the SYSTEM tablespace.
Migrate Tablespaces from Dictionary to Local Management In 9.2
Remember that all the tablespaces MUST be migrated BEFORE you migrate
the SYSTEM tablespace.
Use the DBMS_SPACE_ADMIN package as follows:
SQL> execute
sys.DBMS_SPACE_ADMIN.TABLESPACE_MIGRATE_TO_LOCAL('TABLESPACE_NAME');
This operation requires that:
--> Migrate all other dictionary tablespaces to locally
managed before migrating the SYSTEM tablespace (otherwise inescapable
situation)
--> The database has a default temporary tablespace that is
not SYSTEM:
--> There are no rollback segments in
dictionary-managed tablespaces
--> There is at least one online rollback segment in a
locally managed tablespace, or if using automatic undo management, an
undo tablespace is online.
--> All tablespaces other than the tablespace containing the
undo space (that is, the tablespace containing the rollback segment or
the undo tablespace) are in read-only mode:
--> There is a cold backup of the database
--> The system is in restricted mode:
Oracle Net Trace Assistant
Oracle administrators use tracing to provide a detailed description of
the operations performed by Oracle's internal components. The trace
information is sent to an output trace file, which can then be
investigated to provide an insight into the events that are causing the
problem. Oracle provides tracing mechanisms for both client and server
communication programs.
The information in these trace files is sometimes so cryptic that it is
unusable. Oracle9i Release 2 introduces the Oracle Net Trace assistant
to help administrators decipher information contained in the trace
files. The TRCASST [options] <tracefilename> command can be used
to provide a more readable trace
DBNEWID
(Change the Internal Database Identifier)
DBNEWID is a database utility that can change the internal database
identifier (DBID) and the database name (DBNAME) for an operational
database. This utility is also used in creating logical standby
databases.
Prior to the introduction of the DBNEWID utility, you could manually
create a copy of a database and give it a new database name (DBNAME) by
re-creating the control file. However, you could not give the database
a new identifier (DBID). The DBID is an internal, unique identifier for
a database. Because Recovery Manager (RMAN) distinguishes databases by
DBID, you could not register a seed database and a manually copied
database together in the same RMAN repository. The DBNEWID utility
solves this problem by allowing you to change any of the following:
· The DBID of a database
· The DBNAME of a database
· Both the DBNAME and DBID of a database
Recovery Time
The parameter LOG_CHECKPONT_INTERVAL and FAST_START_IO_TARGET is not
used any more, is better to use FAST_START_MTTR_TARGET.
With these parameter DBA's can specify
the average recovery time (in
seconds) from instance crashes . This feature is implemented by
limiting the number of dirty
buffers and the number of redo records generated between the most
recent redo record and
the last checkpoint. The database server essentially adjusts the
checkpoint
rate to meet the specified recovery target. If FAST_START_MTTR_TARGET
parameter is set to too low a value, then the
database will be writing to disk very frequently and this could easily
result in system slowdown. The parameter should therefore be
adjusted such that the system is not doing excessive checkpoints but at
the same time, the recovery time is still within acceptable
limits. Oracle9i R2 has an advisory
called Recovery Cost
Estimate for determining the performance impact for various settings of
the FAST_START_MTTR_TARGET. This feature greatly simplify
the determination of the right value for this parameter. Use at least
300 for this value (the maximum is 3600 = 1hour). Use show parameter
fast to see its values and select * from
V$MTTR_TARGET_ADVICE for recommendations.
The Enterprise Manager interface to the MTTR Advisory helps you select
the best MTTR time for your needs by reporting the advice statistics in
a graphical as well a tabular format. The MTTR Advisor is available
from Enterprise Manager by selecting:
Databases > Database Name > Instance > Configuration >
Recovery tab > Advice next to Desired mean time to recover.
Say goodbye
Server Manager
bstat/estat
Connect internal
Traditional temporary tablespaces
Incremental export
ANALYZE
LONG data type
NCHAR
Rollback segment management
Initialization parameters: ROLLBACK_SEGMENTS, LOG_CHECKPOINT_INTERVAL,
DB_BLOCK_BUFFERS
DBMS_XPLAN
The DBMS_XPLAN package is used to format the output of an explain plan.
It is intended as a replacement for the utlxpls.sql script.
Create a PLAN_TABLE if it does not already exist:
conn sys/password as sysdba
@$ORACLE_HOME/rdbms/admin/utlxplan.sql
CREATE PUBLIC SYNONYM plan_table FOR sys.plan_table;
GRANT INSERT, UPDATE, DELETE, SELECT ON sys.plan_table TO public;
Next we explain an SQL statement:
conn scott/tiger
EXPLAIN PLAN FOR
SELECT *
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND e.ename = 'SMITH';
Finally we use the DBMS_XPLAN.DISPLAY function to display the execution
plan:
SET LINESIZE 130
SET PAGESIZE 0
SELECT *
FROM TABLE(DBMS_XPLAN.DISPLAY);
----------------------------------------------------------------------------
| Id |
Operation
| Name | Rows | Bytes |
Cost |
----------------------------------------------------------------------------
| 0 | SELECT
STATEMENT
|
| 1 | 57
| 3 |
| 1 | NESTED
LOOPS
|
| 1 | 57
| 3 |
|* 2 | TABLE ACCESS
FULL |
EMP
| 1 | 37
| 2 |
| 3 | TABLE ACCESS BY INDEX ROWID|
DEPT
| 1 | 20
| 1 |
|* 4 | INDEX UNIQUE
SCAN |
PK_DEPT | 1
|
| |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("E"."ENAME"='SMITH')
4 - access("E"."DEPTNO"="D"."DEPTNO")
Note: cpu costing is off
The DBMS_XPLAN.DISPLAY function can accept 3 parameters:
EXPLAIN PLAN SET STATEMENT_ID='TSH' FOR
SELECT *
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND e.ename = 'SMITH';
SET LINESIZE 130
SET PAGESIZE 0
SELECT *
FROM
TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE','TSH','BASIC'));
----------------------------------------------------
| Id |
Operation
| Name |
----------------------------------------------------
| 0 | SELECT
STATEMENT
|
|
| 1 | NESTED
LOOPS
|
|
| 2 | TABLE ACCESS
FULL |
EMP |
| 3 | TABLE ACCESS BY INDEX ROWID|
DEPT |
| 4 | INDEX UNIQUE
SCAN |
PK_DEPT |
----------------------------------------------------
To use
the autotrace facility
As sys run the following:
@$ORACLE_HOME/sqlplus/admin/plustrce;
@$ORACLE_HOME/rdbms/admin/utlxplan;
grant plustrace to public ;
Then each user must run
@$ORACLE_HOME/rdbms/admin/utlxplan;
and then they can use the Sentence
set autotrace on
The get_time function in the dbms_utility package is intended
to be used to get the difference in time between two calls to it.
Its advantage is that the time is in hundredths of seconds
granularity instead of seconds.
DECLARE
time_hundredths
BINARY_INTEGER;
BEGIN
time_hundredths := dbms_utility.get_time;
--your code
dbms_output.put_line('That took ' || dbms_utility.get_time - time_hundredths || ' hsecs');
END;
Native
Compilation of PL/SQL
The PL/SQL native compiler feature in Oracle9i compiles PL/SQL code for
faster access. The greatest benefit is to applications that use stored
procedures, triggers etc. and are data intensive; whether the PL/SQL
runs in the application server or database server, performance can be
very significantly improved. By taking fewer cycles to run a piece of
logic, this also enables the Oracle server scalability to improve. This
option is perfect for computer intensive operations (like mathematical
calculations).
In Oracle9i, a PL/SQL library unit can be compiled as native C code,
rather than interpreted as byte code. It is then stored as a shared
library in the file system. The process of compiling a PL/SQL function
or procedure is very simple:
ALTER FUNCTION my_func COMPILE;
Compilation results in faster execution of PL/SQL programs. The
improvement in execution speed is due to the following factors:
· Elimination of the overhead associated with interpreting byte
code
· Better, faster Control flow in native code than in interpreted
code
The compiled code corresponding to a PL/SQL program is mapped to a PGA
as opposed to SGA to allow better concurrent access. With native
compilation, PL/SQL that does not contain SQL references can be 2-10
times faster, though performance remains dependent on a large number of
applicationspecific factors.
To turn native compilation on, you need to issue the following
statement:
ALTER SESSION SET
plsql_compiler_switches=NATIVE;
This is all you need to do after a simple 1-time setup by your DBA to
configure Oracle to run native code securely. This setting is
persistent and if the procedure is automatically recompiled it will
recompile in native mode. We have measured a reduction in elapsed time
for a computationally intensive unit (in single user tests) of about
40% when it’s compiled Native. While for data intensive programs native
compilation may give only a marginal performance improvement, we have
never seen it give performance degradation. Furthermore, the m-code is
loaded into the SGA whereas the dynamically linkable shared library is
loaded into regular operating system memory. Thus when the whole
database is compiled natively, a higher throughput may be possible due
to reduced SGA contention. The simplest way to honor the recommendation
above (Oracle recommends that all the PL/SQL library units that are
called from a given top-level unit are compiled in the same mode) is to
upgrade the whole database so that all PL/SQL library units are
compiled NATIVE. A release soon after Oracle9i Database Version 9.2.0
will include such a script together with its partner to downgrade a
whole database so that all PL/SQL library units are compiled
INTERPRETED. Meanwhile, these are posted on OTN here…
http://otn.oracle.com//tech/pl_sql/htdocs/README_2188517.htm
Removing
Examples Schemas
Check how to remove them in Metalink Notes:160861.1 and 207560.1
Temporary Tables
The definition of a temporary table persists just like a permanent
table, but contains either session-specific or transaction-specific
data. Both of these types control how temporary you want the data to
be. The session using the temporary table gets bound to the session
with the first insert into the table. This binding goes away, and thus
the data disappears, by issuing a truncate of the table or by ending
either the session or transaction depending on the temporary table type.
The DDL for creating a session-specific temporary table is presented
here:
CREATE GLOBAL TEMPORARY TABLE
search_results
(search_id NUMBER, result_key
NUMBER)
ON COMMIT PRESERVE ROWS;
or
CREATE GLOBAL TEMPORARY TABLE
search_results
(search_id NUMBER, result_key
NUMBER)
ON COMMIT DELETE ROWS;
Features of temporary tables
- Data is visible only to the session.
- The table definition is visible to all sessions.
- In rolling back a transaction to a save point, the data will be lost
but the table definition persists.
- You can create indexes on temporary tables. The indexes created are
also temporary, and the data in the index has the same session or
transaction scope as the data in the table.
- You can create views that access both temporary and permanent tables.
- You can create triggers on a temporary table.
- You can use the TRUNCATE command against the temporary table. This
will release the binding between the session and the table but won’t
affect any other sessions that are using the same temporary table.
- The export and import utilities handle the definition of the
temporary table, but not the data.
Restrictions
- Temporary tables can’t be index organized, partitioned, or clustered.
- You can’t specify foreign key constraints.
- Columns can’t be defined as either varray or nested tables.
- You can’t specify a tablespace in the storage clause. It will always
use the temporary tablespace.
- Parallel DML and queries aren’t supported.
- A temporary table must be either session- or transaction-specific it
can’t be both.
- Backup and recovery of a temporary table’s data isn’t available.
- Data in a temporary table can’t be exported using the Export utility.
Recompiling Invalid
Schema Objects
The DBA_OBJECTS view can be used to identify invalid objects using the
following query:
COLUMN object_name FORMAT A30
SELECT owner,
object_type,
object_name,
status
FROM dba_objects
WHERE status = 'INVALID'
ORDER BY owner, object_type,
object_name;
DBMS_UTILITY.compile_schema
The COMPILE_SCHEMA procedure in the DBMS_UTILITY package compiles all
procedures, functions, packages, and triggers in the specified schema.
The example below shows how it is called from SQL*Plus:
EXEC
DBMS_UTILITY.compile_schema(schema => 'SCOTT');
UTL_RECOMP
The UTL_RECOMP package contains two procedures used to recompile
invalid objects. As the names suggest, the RECOMP_SERIAL procedure
recompiles all the invalid objects one at a time, while the
RECOMP_PARALLEL procedure performs the same task in parallel using the
specified number of threads. The following examples show how
these procedures are used:
-- Schema level.
EXEC
UTL_RECOMP.recomp_serial('SCOTT');
EXEC
UTL_RECOMP.recomp_parallel(4, 'SCOTT');
-- Database level.
EXEC UTL_RECOMP.recomp_serial();
EXEC
UTL_RECOMP.recomp_parallel(4);
There are a number of restrictions associated with the use of this
package including:
utlrp.sql and utlprp.sql
The utlrp.sql and utlprp.sql scripts are provided by Oracle to
recompile all invalid objects in the database. They are typically run
after major database changes such as upgrades or patches. They are
located in the $ORACLE_HOME/rdbms/admin directory and provide a wrapper
on the UTL_RECOMP package. The utlrp.sql script simply calls the
utlprp.sql script with a command line parameter of "0". The utlprp.sql
accepts a single integer parameter that indicates the level of
parallelism as follows:
Both scripts must be run as the SYS user, or another user with
SYSDBA, to work correctly.