Oracle
10g New Features
The G stands for Grid Computing. A common missconception seems to be
that grid is just the new name for RAC (having improved RAC) This is
not the case. 10g comes with both RAC and grid. One will be able to
install 10g with RAC only, with grid only, without either and with
both. There is a profound difference between grid and RAC. 10g is said
to have 149 new features. 10g provides a wealth of features that can be
used to automate almost every aspect of its database administration. It
is important to note that these automation features are optional, and
they are not intended to replace standard DBA activities. Rather, the
Oracle10g automation features are aimed at shops that do not have the
manpower or expertise to manually perform the tasks.
Oracle Enhancements by Oracle Release
New Utilities in Oracle10g release 10.1.0:
• Oracle10g Grid – RAC enhanced for Oracle10g dynamic
scalability with server blades
(extra-cost option)
• Completely reworked 10g Enterprise Manager (OEM)
• AWR and ASH tables incorporated into OEM
Performance Pack and Diagnostic Pack options (extra-cost option)
• Automated Session History (ASH) materializes the
Oracle Wait Interface over time (extra-cost
option)
• Data Pump replaces imp utility with impdp
• Automatic Database Diagnostic Monitor (ADDM) (extra-cost option)
• Automatic Storage Management (ASM) introduced
Stripe And Mirror Everywhere (SAME) standard
• Automatic Workload Repository (AWR) replaces
STATSPACK (extra-cost option)
• SQLTuning Advisor
• SQLAccess Advisor
• Rolling database upgrades (using Oracle10g RAC)
• dbms_scheduler package replaces dbms_job for
scheduling
OEM Partition Manager introduced
Miscellaneous Oracle10g enhancements:
• Set Database Default Tablespace syntax
• Run Faster PL/SQL Programs because The new PL/SQL
optimizing compiler and Implicit array fetching. So even if you use
For x in (select * from table)
Loop
Process data;
End loop;
PL/SQL is silently "array fetching" 100 rows at a time.
• Rename Tablespace command
• Introduced RECYCLEBIN command for storing objects
before they are dropped. Required new PURGE command for maintenance.
• sqlplus / as sysdba accessibility without quote
marks
• SYSAUX tablespace
• Multiple Temporary Tablespaces supported to reduce
stress on sorting in TEMP
• RMAN introduces compression for backups
• New drop database syntax
• New alter database begin backup syntax
• Oracle10g Data Guard Broker introduced
• Oracle10g RAC supports secure Redo Log transport
• Flashback enhancements for flashback database and
flashback table syntax
• SQL Apply feature
• VPD (FGAC, RLS) supports both row-level and
column-level VPD
• Cross Platform Transportable Tablespaces
• External Table unload utility
• SQL Regular Expression Support with the evaluate
syntax
• New ROW TIMESTAMP column
• Improvement to SSL handshake speed
• Automatic Database Tuning of Checkpoints, Undo
Segments and shared memory
• Automated invoking of dbms_stats for CBO statistics
collection
• RAC introduces Integrated Cluster ware
• Oracle Application Builder supports HTML DB
• Browser Based Data Workshop and SQL Workshop
• PL/SQL Compiler enhanced for compile-time Warnings
in utl_mail and utl_compress
• VPD (FGAC, RLS) supports both row-level and
column-level VPD
So, if your 10g database does not require detailed, expert tuning, then
the automated features might be a good choice. They are targeted at
these market segments:
- Small shops: Small installations that can't afford a trained
Oracle DBA.
- Shops with over-worked DBAs: Large shops with hundreds of
instances where the DBA does not have time to properly tune each
system.
Statistics Collection
These
new feature
include
collection of data dictionary statistics, new behaviors associated with
the dbms_stats
package,
and new features
related to monitoring tables in the database. The
Rule Based Optimizer (RBO) is
desupported with 10g. Oracle Database 10g includes
new
statistics-gathering features. This includes the ability to collect
data
dictionary statistics, which is now recommended as a best practice by
Oracle.
Also, 10g includes new features that enhance the
generation of
object level statistics within the database. Let’s look at these next.
Data
Dictionary Statistics
Collection
Oracle
recommends
that
you analyze the data dictionary. You can collect these statistics by
using
either the dbms_stats.gather_schema_stats
or
dbms_stats.gather_database_stats
Oracle-supplied
procedures, as shown here:
Exec
dbms_stats.gather_schema_stats(’SYS’)
The
gather_schema_stats
and
gather_database_stats
procedures
are
not new in Oracle Database 10 g, but using them to collect data
dictionary
statistics is new, as are some new parameters that are available with
these
procedures. Oracle Database 10g also offers two new procedure in the dbms_stats
package.
First, the dbms_stats.gather_dictionary_stats
procedure
facilitates analysis of the data dictionary.
Second the dbms_stats.delete_dictionary_
stats procedure
allows you to remove data dictionary stats.
Here is an example of the use of the dbms_stats.gather_dictionary_stats
procedure:
exec
dbms_stats.gather_dictionary_stats;
This
example gathers statistics from
the SYS and SYSTEM schemas as well as any other schemas that are
related to
RDBMS components (e.g., OUTLN or DBSNMP).
Any
user with SYSDBA privileges can analyze the data dictionary.
Gathering
Fixed Table
Statistics
A
new parameter to the dbms_stats.gather_database_stats
and
dbms_stats.gather_database_stats
packages
is gather_fixed.
This parameter is set to false
by
default, which disallows statistics collection for
fixed data dictionary tables (e.g., x$tables). Oracle suggests that you
analyze
fixed tables only once during a typical system workload. You should do
this as
soon as possible after your upgrade to Oracle Database 10 g, but again
it
should be under a normal workload. Here is an example of the use of the
gather_fixed
argument
within the dbms_stats.gather_schema_stats
procedure:
Exec
dbms_stats.gather_schema_stats(’SYS’,gather_fixed=>TRUE)
Yet
another new procedure, dbms_stats.gather_fixed_objects_stats,
has been provided in Oracle Database 10g to collect object
statistics on fixed objects. It also has a brother, delete_fixed_objects_stats,
which
will remove the object statistics. Second cousins and new Oracle
Database 10
gprovided procedures include dbms_stats.export_fixed_objects_stats
and
dbms_stats.import_fixed_
objects_stats.
These allow you to export and import
statistics to user-defined statistics tables, just as you could with
normal
table statistics previously. This allows your data dictionary fixed
statistics
to be exported out of and imported into other databases as required.
One other
note: the dbms_stats
Oracle-supplied
package also supports analyzing specific data
dictionary tables.
When
to Collect Dictionary
Statistics
Oracle
recommends the following
strategy with regard to analyzing the data dictionary in Oracle
Database 10 g:
1.
Analyze
normal data dictionary objects (not fixed dictionary
objects) using the same interval that you currently use when analyzing
other
objects. Use gather_database_stats,
gather_schema_stats,
or gather_dictionary_stats
to
perform this action. Here is an example:
Exec
dbms_stats.gather_schema_stats(’SYS’,gather_fixed=>TRUE)
2.
Analyze
fixed objects only once, unless the workload footprint
changes. Generally, use the dbms_stats.gather_fixed_object_stats
supplied
procedure when connected as SYS or any other
SYSDBA privileged user. Here is an example:
Exec
dbms_stats.gather_fixed_objects_stats(’ALL’);
New
DBMS_STATS Behaviors
Oracle
has introduced some new
arguments that you can use with the dbms_stats
package
in Oracle Database 10g. The granularity
parameter
is used in several dbms_stats
subprograms
(e.g., gather_table_stats
and
gather_schema_stats)
to indicate the
granularity of the statistics that you want to collect, particularly
for
partitioned tables. For example, you can opt to only gather global
statistics
on a partitioned table, or you can opt to gather global and
partition-level
statistics. The granularity
parameter
comes with an auto
option.
When auto
is
used, Oracle collects global, partition-level, and sub-partition-level
statistics for a range-list partitioned table. For other partitioned
tables,
only global and partition-level statistics will be gathered. A second granularity
option,
global
and partition,
will gather the
global and partition-level statistics but no sub-partition-level
statistics,
regardless of the type of partitioning employed on the table. Here are
some
examples of using these new options:
Exec
dbms_stats.gather_table_stats(’my_user’,’my_tab’,granularity=>’AUTO’);
Exec
dbms_stats.gather_table_stats(’my_user’,’my_tab’,
granularity=>’GLOBAL
AND PARTITION’);
New
options are also available with
the degree
parameter,
which
allows you to parallelize the statistics-gathering process. Using the
new auto_degree
option,
Oracle will determine
the degree of parallelism that should be used when analyzing the table.
Simply
use the predefined value, dbms_stats.auto_degree,
in the degree
parameter.
Oracle will then decide
the degree of parallelism to use. It may choose to use either
no
parallelism or a default degree
of parallelism, which is dependent on the number of CPUs and the value
of
various database parameter settings. Here is an example of the use of
the new degree
option:
Exec
dbms_stats.gather_table_stats
(’my_user’,’my_tab’,degree=>dbms_stats.auto_degree);
Finally,
the stattype
parameter
is a new parameter
that allows you the option of gathering both data and caching
statistics (which
is the default) or only data statistics or only caching statistics.
Valid
options are all,
cache,
or data,
depending on the type of statistics you wish to gather. Here
is an example of the use of the stattype
parameter:
Exec
dbms_stats.gather_table_stats
(’my_user’,’my_tab’,stattype=>’ALL’);
Flushing
the Buffer Cache
Prior
to Oracle Database 10g, the only way to flush the database buffer
cache was to shut down the database and restart it. Oracle Database 10g
now allows you to flush the database buffer cache with the alter system
command using the flush buffer_cache parameter. The FLUSH Buffer Cache
clause is useful if you need to measure
the performance of rewritten queries or a suite of queries from
identical starting points. Use the following statement to flush the
buffer cache.
ALTER SYSTEM FLUSH BUFFER_CACHE;
ALTER SYSTEM FLUSH SHARED POOL;
However,
note that this clause is intended for use only on a test
database. It is not advisable to use this clause on a production
database, because subsequent queries will have no hits, only misses.
Database Resource Manager New
Features
The
Database Resource Manager in
Oracle Database 10g offers a few new features that you need to be aware
of:
■
The
ability
to revert to the original consumer group at the end of an operation
that caused
a change of consumer groups
■
The
ability
to set idle timeout values for consumer groups
■
The
ability
to create mappings for the automatic assignment of sessions to specific
consumer groups
Each
of these topics is discussed,
in turn, in more detail in the following sections.
Reverting
Back to the Original Consumer Group
Prior
to Oracle Database 10g, if a
SQL call caused a session to be put into a different consumer group
(for
example, because a long-running query exceeded a SWITCH_TIME directive
value in
the consumer group), then that session would remain assigned to the new
resource
group until it was ended. Oracle Database 10g allows you to use the new
SWITCH_BACK_AT_CALL_END directive to indicate that the session should
be
reverted back to the original consumer group once the call that caused
it to
switch consumer groups (or the top call) is complete. This is very
useful for
n-tier applications that create a pool of sessions in the database for
clients
to share. Previously, after the consumer group had been changed, all
subsequent
connections would be penalized based on the settings of the consumer
group
resource plan. The new SWITCH_BACK_AT_CALL_END directive allows the
session to
be reset, thus eliminating the impact to future sessions. Here is an
example of
the use of this new feature:
EXEC
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(PLAN => 'main_plan',
GROUP_OR_SUBPLAN => 'goonline',
COMMENT => 'Online sessions', CPU_P1 => 80,
SWITCH_GROUP => 'ad-hoc',
SWITCH_TIME => 3,SWITCH_ESTIMATE => TRUE,
SWITCH_BACK_AT_CALL_END=>TRUE);
In
this case, I have created a plan
directive that is a part of an overall plan called MAIN_PLAN. This
particular
plan directive is designed to limit the impact of online ad-hoc users
(or
perhaps applications that are throwing out a great deal of dynamic SQL
that’s
hard to tune) if they issue queries that take a long time (in this
example, 3
seconds). This directive causes a switch to a consumer group called
ad-hoc,
which would likely further limit CPU and might also provide for an
overall
run-time limit on executions in this particular plan/resource group.
Since I
have included the SWITCH_BACK_AT_CALL_END directive in this plan
directive, the
consumer group will revert back to the original plan after the
completion of
the long-running operation.
Setting
the Idle Timeout
Oracle
Database 10g allows you to limit
the maximum time that a session is allowed to remain idle. The max_idle_time
parameter
allows
you to define a maximum amount of time that a given session can sit
idle, as is
shown in the upcoming example. PMON will check the session once a
minute and
kill any session that has been idle for the amount of time defined in
the plan.
EXEC
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(PLAN => 'main_plan',
GROUP_OR_SUBPLAN
=> 'online', max_idle_time=>300,
comment=> ’Set
max_idle_time’);
Creating
Mappings for Automatic Assignment of Sessions to
Consumer Groups
The
dbms_resource_manager.set_group_mapping
procedure
allows you to map a specific consumer group to a given
session based on either login or run-time attributes.
These
attributes include:
■
The
username
■
The
service
name
■
The
client
OS username
■
The
client
program name
■
The
client
machine
■
The
module
name
■
The
module
name action
You
then have to determine what
session attributes you want to map to a given consumer group. In this
example,
I have mapped the client machine called tiger to the resource consumer
group
LOW_PRIORITY:
Exec
dbms_resource_manager.set_group_mapping
(DBMS_RESOURCE_MANAGER.CLIENT_MACHINE,‘tiger’,’low_priority’);
Thus,
if anyone logs in to the
database from the machine named tiger, they will be assigned to the
consumer
group LOW_PRIORITY, which will have already been created.
Often
times, there can be a number
of mappings that apply to a given session, and a priority has to be
defined.
This is done by using the procedure dbms_resource_manager.set_mapping_priority.
This example creates two mappings:
Dbms_resource_manager.set_group_mapping
(DBMS_RESOURCE_MANAGER.CLIENT_MACHINE,
‘tiger’,’low_priority’);
Dbms_resource_manager.set_group_mapping
(DBMS_RESOURCE_MANAGER.ORACLE_USER,
‘NUMBER_ONE’,’high_priority’);
In
this case, anyone signing in from
tiger is assigned to the LOW_PRIORITY consumer group, but where will
the user
NUMBER_ONE be assigned? Well, right now it’s hard to tell. So, to make
sure
that NUMBER_ONE is always set to be assigned to the high-priority
resource
consumer group, I can use the provided procedure called dbms_resource_manager.set_mapping_priority:
Dbms_resource_manager.set_mapping_priority(ORACLE_USER=>1,
CLIENT_MACHINE=>2,
EXPLICIT=>3, MODULE_NAME=>4, SERVICE_NAME=>5,
CLIENT_OS_USER=>6,
CLIENT_PROGRAM=>7, MODULE_NAME_ACTION=>8);
This
code will cause Oracle to
prioritize consumer group selection based first on username and then on
the
client machine name. So, now the user NUMBER_ONE will always get the
higher-priority consumer group assignment. Be aware that regardless of
consumer
group assignments, a user must still be given switching privileges into
a given
consumer group. If the user has not been granted such privileges, then
sessions
will not be switched.
Scheduler Changes
Oracle
Database 10g offers a brand
new job-scheduling facility, known as The Scheduler, controlled via the
new package dbms_scheduler.
This package
replaces the dbms_job
(but
that one is still available).
The
new scheduler offers much added
functionality over the dbms_job
package.
The Scheduler enables you to execute a variety of
stored code (such as PL/SQL), a native binary executable, and OS
scripts (so you can get rid of cron jobs).
The object that is being run by The Scheduler is known as the program.
The
program is more than just the name; it includes related metadata about
the
program, such as the arguments to be passed to it and the type of
program that
is being run.
Different
users can use a program at
different times, eliminating the need to have to redefine the program
every
time you wish to schedule a job. Programs can be stored in program
libraries, which
allows for easy reuse of program code by other users. Each program,
when
scheduled, is assigned to a job. A job can also just contain an
anonymous
PL/SQL block instead of a program. The job is a combination of the
program (or
anonymous PL/SQL block) and the schedule associated with the program,
which
defines when the job is to run. Also associated with the job is other
metadata
related to the job, such as the job class and the window or window
group. The
job class is a category of jobs that share various characteristics,
such as
resource consumer group assignments and assignments to a common,
specific,
service name. The job class is related to the job window. The job
window, or
window group, essentially allows the job to take advantage of specific
resource
plans. For example, if the schedule for a job is for it to run every
hour, the
job window will allow it to run under one resource group in the morning
and a
different resource group in the evening. That way, you can control the
resources the job can consume at different times throughout the day.
Oracle
provides two different interfaces into The Scheduler. The first is the dbms_scheduler
package
and the
second is through the Oracle Enterprise Manager (OEM).
More information HERE
Practical
Use of the
Scheduler
There
are a few steps to follow when
you want to assign a job to The Scheduler:
■
Create
the
program (optional).
■
Create
the
job.
Creating a Program in the
Scheduler
Creating
a program is the optional
first step when creating a scheduled operation. This operation may
actually
take four steps:
1.
Create
the program itself.
2.
Define
the program arguments.
3.
Create
the job.
4.
Define
job arguments.
The
following sections explain each
of these steps in turn.
1.Creating
the Program To
create a program, so that you can schedule it, you use the
PL/SQL-supplied procedure dbms_scheduler.create_program.
To use this package in your own schema, you must have the create
job privilege.
To use it to
create jobs in other schemas, you need the create
any job privilege.
By default, a program is created in a disabled
state (which can be overridden by setting the enabled
parameter
of the create_program
procedure
to TRUE). First, let’s look at the definition
of the
dbms_scheduler.create_program
procedure:
DBMS_SCHEDULER.CREATE_PROGRAM
(
program_name
IN VARCHAR2,
program_type
IN VARCHAR2,
program_action
IN VARCHAR2,
number_of_arguments
IN PLS_INTEGER
DEFAULT 0,
enabled
IN BOOLEAN DEFAULT FALSE,
comments
IN VARCHAR2 DEFAULT NULL);
It
always helps to know what the
various parameters are for, of course. So let’s look at a description
of the parameters
for the create_program
procedure:
Parameter
Name Description
program_name
Identifies
the name of the program. This is an internally
assigned name, which represents the program_action
that
will be executed.
program_type
Identifies
the type of executable being scheduled. Currently, the following are
valid
values: PLSQL_BLOCK, STORED_PROCEDURE, and EXECUTABLE.
program_action
Indicates
the procedure, executable name, or PL/SQL anonymous block associated
with the
program.
number_of_arguments
Identifies
the number of arguments required for the program
(ignored if program_type
is
PLSQL_BLOCK).
Enabled
Indicates
whether
the program should be enabled when created.
Comments
Allows
freeform comments describing the program or what it does.
Here
are some examples of the
creation of programs:
BEGIN
dbms_scheduler.create_program(
program_name
=>
’delete_records’,
program_action
=>
’/opt/oracle/maint/bin/nightly_delete_records.sh’,
program_type
=> ’EXECUTABLE’,
number_of_arguments=>2);
END;
You can enable this program as follows:
execute
DBMS_SCHEDULER.ENABLE (`delete_records`);
You can disable this program as follows:
execute
DBMS_SCHEDULER.DISABLE (‘delete_records’);
Note
that Oracle does not check for the existence of the
program when the create_program
procedure
is executed. Thus, you can create your program even if
the underlying executable doesn’t exist. You can create a program for
an
anonymous PL/SQL block as well, as demonstrated in this example:
BEGIN
dbms_scheduler.create_program(
program_name =>
’sp_delete_records’,
program_action =>
’DECLARE rec_count
number;
BEGIN
DELETE FROM
old_records
WHERE record_date
< sysdate – 5;
rec_count:=sqlcommand%ROWCOUNT;
insert into
records_removed
(date, table,
how_many, job_ran) VALUES
(sysdate,
’OLD_RECORDS’, rec_count, scheduler$_job_start);
COMMIT;
END;’,
program_type =>
’EXECUTABLE’);
END;
In
the case of this anonymous block,
I used one of several supplied special variable names in my code (in
this case,
scheduler$_job_start). These variables are described briefly in the
following
table:
| Variable
Name |
Description |
| scheduler$_job_name |
Provides
the name of the job
being executed |
| scheduler$_job_owner |
Provides
the name of the owner of
the job |
| scheduler$_job_start |
Provides
the start time of the
job |
| scheduler$_window_start |
Indicates
the start time of the
window associated with the job |
| scheduler$_window_end |
Indicates
the end time of the window associated with the job |
OEM
also provides an interface to
create programs that you can use if you prefer that method.
You
can drop a program with the dbms_scheduler.drop_program
procedure,
as shown in this example:
Exec
dbms_scheduler.drop_program(’delete_records’);
2.Defining
the Program
Arguments Many
programs have arguments (parameters) that need to be included when that
program is called. You can
associate arguments with a program by using the dbms_scheduler.define_program_
argument procedure.
Using the previous program example, delete_records,
I can add some arguments to
the program as follows:
BEGIN
dbms_scheduler.define_program_argument(
program_name
=>
’delete_records’,
argument_name
=> ’delete_date’,
argument_position=>1,
argument_type=>’date’,
default_value=>
’to_char(sysdate
- 5, ’’mm/dd/yyyy’’)’ );
end;
/
To
be able to call this program, you
need the alter
any job or
create
any job privilege.
Additionally, calling this problem does not change
the state of the associated job (enabled or disabled). You can replace
an
argument by simply calling the define_
program_argument procedure
and replacing an existing
argument position.
3.Creating
the Job
To
actually get The Scheduler to do
something, which is kind of the idea, you need to create a job. The job
can
either run a program that you have created (refer to the previous
section) or
run its own job, which is defined when the job is defined. The job
consists of
these principle definitions:
■
The
schedule This
is when the job is supposed to do whatever it’s supposed to
do. The schedule consists of a start time, an end time, and an
expression that
indicates the frequency of job repetition.
■
The
associated job argument (or the what) This
is what the job is supposed to do. This can be a
pre-created PL/SQL or Java program, anonymous PL/SQL, or even an
external
executable (for example, a shell script or C program call).
■
Other
metadata associated with the job This
includes such things as the job’s class and priority,
job-related comments, and the job’s restartability.
Jobs are created with the dbms_scheduler.create_job
package,
as
shown in this example:
Exec
dbms_scheduler.create_job(
job_name=>’CLEAR_DAILY’,
job_type=>’STORED_PROCEDURE’,
job_action=>’JOBS.SP_CLEAR_DAILY’,
start_date=>NULL,
repeat_interval=>’TRUNC(SYSDATE) + 1/24’,
comments=>’Hourly Clearout Job’);
This
example creates a scheduled job
that executes immediately and then will run every hour thereafter. This
job is
assigned a name called CLEAR_DAILY. When The Scheduler runs the job, a
PL/SQL
stored procedure called sp_clear_daily
is
executed. Perhaps another example is in order. In this case,
I will create a scheduled job that fires off an external shell script:
Exec
dbms_scheduler.create_job(
job_name=>’RUN_BACKUP’,
job_type=>’EXECUTABLE’,
job_action=>’/opt/oracle/admin/jobs/run_job.sh’,
start_date=>’to_date(’04-30-2003
20:00:00’,’mm-dd-yyyy
hh24:mi_ss’),
repeat_interval=>’TRUNC(SYSDATE) + 23/24’,
comments=>’Daily Backup’);
The
repeat_interval
attribute
defines
how often and when the job will repeat. If the repeat_interval
is
NULL (the
default), the job executes only one time and then is removed. When
determining
the interval, you have two options. First, you can use the older PL/SQL
time
expressions for defining the program execution intervals.
Oracle
Database 10g now offers a new
feature, Calendar Expressions, which you can use in lieu of the old
PL/SQL time
expressions. There are three different types of components: the
frequency
(which is mandatory), the specifier, and the interval. Frequencies
indicate how
often the job should run. The following frequencies are available:
Yearly
Monthly Weekly Daily Hourly
Minutely Secondly
Additional
parameters, the specifier
and interval, define in more detail how frequently the job should run.
4.Defining
the Job Arguments If
you are scheduling a job that is not associated with a
program, then that job may be a program that accepts arguments. If this
is the
case, you need to use the dbms_scheduler.set_job_argument_value
procedure.
Executing this procedure will not enable or
disable any given job. Here is an example of setting some parameters
for a job.
In this case, I am indicating to the RUN_BACKUP job that it should
include an
argument of ‘TABLESPACE USERS’, which might indicate that the backup
job should
back up the USERS tablespace.
exec
dbms_scheduler.set_job_argument_value
( job_name =>’RUN_BACKUP’,
argument_name=>’BACKUP_JOB_ARG1’,
argument_value=>’TABLESPACE USERS’);
Create and
Drop a Schedule
You can use the create_schedule procedure to create a schedule for your
job by using the following syntax:
DBMS_SCHEDULER.CREATE_SCHEDULE
( schedule_name
in varchar2,
start_date
in timestamp with
timezone default null,
repeat_interval in
varchar2,
end_date
in timestamp with
timezone default null,
comments
in varchar2 default
null);
In this procedure, start_date specifies the date on which the schedule
becomes active, and end_date specifies that the schedule becomes
inactive after the specified date. repeat_interval is an expression
using either the calendar syntax or PL/SQL syntax, which tells how
often a job should be repeated.
The repeat_interval calendaring expression has three parts:
* The Frequency clause is made of the following elements: YEARLY,
MONTHLY, WEEKLY, DAILY, HOURLY, MINUTELY, SECONDLY,
* The repeat interval range is from 1 to 99
* The other Frequency clause is made of the following elements:
BYMONTH, BYWEEKNO, BYYEARDAY, BYMONTHDAY, BYDAY, BYHOUR, BYMINUTE,
BYSECOND
Here are some examples of the use of calendaring expressions:
* Every March and June of the year:
REPEAT_INTERVAL=> `FREQ=YEARLY; BYMONTH=3,6`
* Every 20th day of the month:
REPEAT_INTERVAL=> `FREQ=MONTHLY; BYMONTHDAY=20`
* Every Sunday of the week:
REPEAT_INTERVAL=> `FREQ=WEEKLY; BYDAY=SUN`
* Every 60 days:
REPEAT_INTERVAL=> `FREQ=DAILY; INTERVAL=60`
* Every 6 hours:
REPEAT_INTERVAL=> `FREQ=HOURLY; INTERVAL=6`
* Every 10 minutes:
REPEAT_INTERVAL=> `FREQ=MINUTELY;INTERVAL=10`
* Every 30 seconds:
REPEAT_INTERVAL=> `FREQ=SECONDLY;INTERVAL=30`
Here are some examples of using PL/SQL expressions:
REPEAT_INTERVAL=> `SYSDATE –1`
REPERT_INTERVAL=> `SYSDATE + 36/24`
The following steps are used to create a schedule:
BEGIN
DBMS_SCHEDULER.CREATE_SCHEDULE (
schedule_name =>
`HOURLY_SCHEDULE`,
start_date
=> `TRUNC(SYSDATE)+23/24`
repeat_interval
=> `FREQ=HOURLY; INTERVAL=1`);
END;
/
You can drop a schedule by performing the following steps:
BEGIN
DBMS_SCHEDULER.DROP_SCHEDULE (
schedule_name => `HOURLY_SCHEDULE`,
force => FALSE);
END;
/
Create,
Run, Stop, Copy, and Drop a Job
Like Program, when a Job is created, it is disabled by default.
You need to explicitly enable a Job so it will become active and
scheduled. A Job can be created with the following four formats:
- With Program, With Schedule
- With Program, Without Schedule
- Without Program, With Schedule
- Without Program, Without Schedule
Example 1:
Use the following to create a Job using a predefined Program and
Schedule:
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name
=> `BACKUP_JOB_01`,
program_name
=> `BACKUP_PROGRAM`,
schedule_name
=> `BACKUP_SCHEDULE`);
END;
/
Example 2:
Use the following to create a Job using a predefined Program without a
predefined Schedule:
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name
=> `BACKUP_JOB_02`,
program_name
=> `BACKUP_PROGRAM`,
start_date
=> `TRUNC(SYSDATE)+23/24`,
repeat_interval
=> `FREQ=WEEKLY; BYDAY=SUN`);
END;
/
Example 3:
Use the following to create a Job using a predefined Schedule without a
predefined Program:
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name
=> `BACKUP_JOB_03`,
schedule_name
=> `BACKUP_SCHEDULE`,
job_type
=> `EXECUTABLE`,
job_action
=> `/dba/scripts/weekly_backup.sh`);
END;
/
Example 4:
Use the following to create a Job without a predefined Program and
Schedule:
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name
=> `BACKUP_JOB_04`,
job_type
=> `EXECUTABLE`,
job_action
=> `/dba/scripts/weekly_backup.sh`,
start_date
=> `TRUNC(SYSDATE)+23/24`
repeat_interval
=> `FREQ=WEEKLY; BYDAY=SUN`);
END;
/
Here is the syntax to run, stop, copy, and drop a Job:
DBMS_SCHEDULER.RUN_JOB( job_name
in varchar2);
DBMS_SCHEDULER.STOP_JOB (
job_name in varchar2,
force in Boolean default false);
The copy_job procedures copies all attributes of an existing job to a
new job.
DBMS_SCHEDULER.COPY_JOB(
old_job
in varchar2,
new_job
in varchar2);
DBMS_SCHEDULER.DROP_JOB(
job_name
in varchar2,
force
in Boolean default false);
Other
Job Scheduler
Functionality
The
new job scheduler also allows
you to define job classes, which allow you to define a category of jobs
that
share common resource usage requirements and other characteristics. One
job can
belong to only one job class, though you can change the job class that
a given
job is assigned to. Any defined job class can belong to a single
resource
consumer group, and to a single service at any given time. Job classes,
then,
allow you to assign jobs of different priorities. For example,
administrative
jobs (such as backups) might be assigned to an administrative class
that is
assigned to a resource group that allows for unconstrained activity.
Other
jobs, with a lesser priority, may be assigned to job classes that are
assigned
to resource groups that constrain the overall operational overhead of
the job,
so that those jobs do not inordinately interfere with other,
higher-priority
jobs. Thus, job classes help you to manage the amount of resources that
a given
job can consume.
To
create a job class, you use the dbms_scheduler.create_job_class
procedure.
All classes belong to the SYS schema, and to create
one requires the manage
scheduler privilege.
Here is an example of defining a job class:
exec
dbms_scheduler.create_job_class(
job_class_name=>’CLASS_ADMIN’,
resource_consumer_group=>’ADMIN_JOBS’,
service=>’SERVCE_B’);
This
job class will be called
CLASS_ADMIN. It is assigned to a resource consumer group (that will
have
already been created) called ADMIN_JOBS, which will no doubt give
administrative jobs pretty unfettered access to resources. This job
class is
also assigned to a specific service, SERVICE_B, so the administrator
can define
which service the job class is associated with.
Once
the job class is defined, you
can define which jobs are members of that class when you create the
jobs.
Alternatively, you can use the dbms_scheduler.set_
attribute procedure
to assign an existing job
to that class.
User-Configurable Default
Tablespaces
Oracle
offers default tablespaces in Oracle Database 10g. Once you configure a
default user
tablespace, all new users will be assigned to that tablespace rather
than the
SYSTEM tablespace. Syntax:
ALTER
DATABASE DEFAULT TABLESPACE <tsname>;
Temporary Tablespace Groups
Oracle
10g now allows you
to define temporary tablespace groups, which are logical groupings of
tablespaces. This
allows you to assign temporary tablespaces to those groups, and
then
assign this tablespace group as the default temporary tablespace for
the
database. In essence, tablespace groups allow you to combine temporary
tablespaces
into one tablespace pool that is available for use to the database.
Assigning
Temporary
Tablespaces to Tablespace Groups
You
can assign a temporary
tablespace to a tablespace group in one of two ways. First, you can
assign it
to a tablespace group when you create the tablespace via the create
tablespace command.
Second,
you can add a tablespace to a tablespace group via the alter
tablespace command.
An
example of each of these operations is listed next (note that OMF is
configured
in this example):
Create
temporary tablespace
temp_tbs_01 tempfile '.../oradata/temp01.dbf' tablespace group
tbs_group_01;
alter
tablespace temp_tbs_01
tablespace group tbs_group_02;
There
is no limit to the number of
tablespaces that can be assigned to a tablespace group. The tablespace
group
shares the same namespace as normal tablespaces, so tablespace names
and
tablespace group names are mutually exclusive. You can also remove a
tablespace
from a group by using the alter
tablespace command
and using empty quotes as an argument to the tablespace
group parameter,
as
shown in this example:
Alter
tablespace temp3 tablespace
group ’’;
Defining
a Tablespace Group
as the Default Temporary Tablespace
After
you have created the
tablespace group and assigned a set of tablespaces to that group, you
can
assign that group of temporary tablespaces (or that tablespace group)
as the
default temporary tablespace for the system, or as a temporary
tablespace group
for specific users.
You
can do this in the create
database statement
when
you create the database, or you can use the alter
database statement
to modify the temporary tablespace settings.
Using either statement, you simply define the tablespace group as the
default
tablespace, as shown in this example:
Alter
database default temporary
tablespace tbs_group_01;
This
has the effect of assigning
multiple tablespaces as the default temporary tablespace. Once you have
assigned a tablespace group as the default temporary tablespace group,
you
cannot drop any tablespace in that group. So, now you can define more
than a
single tablespace as the database default temporary tablespace; as a
result,
larger SQL operations can use more than one tablespace for sort
operations,
thereby reducing the risk of running out of space. This also provides
more
tablespace space, and potentially better I/O distribution for sort
operations
and parallel slave operations that use temporary tablespaces. If a
tablespace
group is defined as the default temporary tablespace, then no
tablespaces in
that group can be dropped until that assignment has been changed. You
can
assign a user to a tablespace group that might not be the default
tablespace
group either in the create
user or
alter
user statements,
as shown in these examples that assign the
TBS_GROUP_01 tablespace to the user NO_PS:
Create
user no_ps identified by
gonesville default tablespace dflt_ts temporary tablespace tbs_group_01;
alter
user no_ps temporary
tablespace tbs_group_02;
Tablespace
Group Data
Dictionary View
A
new view, DBA_TABLESPACE_GROUPS,
is available to associate specific temporary tablespaces with
tablespace
groups. The TEMPORARY_TABLESPACE column of the *_users views will
report either
the temporary tablespace name or the temporary tablespace group name
that is
assigned to the user. Here is an example of a query that joins the
DBA_USERS
and DBA_TABLESPACE_GROUPS views together and gives you a list of users
who are
assigned a tablespace group as their temporary tablespace name, and all
of the
tablespaces that are associated with that group:
Select
a.username,
a.temporary_tablespace, b.tablespace_name
from dba_users a, dba_tablespace_groups b
Where a.temporary_tablespace in (select distinct group_name
from
dba_tablespace_groups);
Renaming
Tablespaces
Oracle
10g includes the ability
to rename tablespaces. You use the alter
tablespace command
with the rename
to parameter,
as shown in this
example:
Alter
tablespace production_tbs
rename to prod_tbs;
You
cannot rename the
SYSTEM or the SYSAUX tablespace. Renaming that tablespace
name DOES NOT CHANGE its datafile. Another nice feature is
that if the tablespace is an UNDO tablespace,
and you are using a server parameter file (SPFILE), Oracle will change
the
UNDO_TABLESPACE parameter in the SPFILE to reflect the new UNDO
tablespace
name. The ability to rename tablespaces has some great practical
applications
with operations such as transportable tablespaces. Now, rather than
having to
drop the existing tablespace before you can transport it in, you only
need
rename that tablespace.
CAUTION
You
should back up the control file
as soon as possible after renaming tablespaces within the database. If
you do
not, depending on when the backup of the control file took place, a
divergence
may exist between the tablespace names in the control file and the
actual
tablespace names in the database.
Dropping Databases
The
drop
database command
can be
used to drop your database. Oracle will drop the database, deleting all
control
files and all datafiles listed in the control file. If you are using a
SPFILE,
then Oracle will remove it as well. Only a user with SYSDBA privileges
can
issue the statement and the database must be mounted (not open) in
exclusive
and restricted mode. Here is an example of the use of the drop
database command:
Drop
database;
Larger LOBs
If
you use LOBs in your database
(NCLOB, BLOB, or CLOB), then you will be happy to know that the limits
on LOBs
have been increased in Oracle 10g. The new maximum limits are
calculated at (4GB – 1 byte) * (the database block size). Thus, if the
database
block size is 8KB, there is essentially a 32GB limitation on LOBs in
that
database. Note that Bfiles are limited to 4GB in size.
The
SYSAUX Tablespace
The
SYSAUX tablespace is a new
feature and required component in Oracle 10g. The
SYSAUX tablespace is a secondary
tablespace for storage a number of database components that were
previously
stored in the SYSTEM tablespace. It is created as a locally managed
tablespace
using automatic segment space management. Previously, many Oracle
features
required their own separate tablespaces (such as the RMAN recovery
catalog,
Ultra Search, Data Mining, XDP, and OLAP). This increases the
management
responsibility of the DBA. The SYSAUX tablespace consolidates these
tablespaces
into one location, which becomes the default tablespace for these
Oracle
features.
When
you create an Oracle database,
Oracle creates the SYSAUX tablespace for you by default. If you are
using OMF,
then the tablespace is created in the appropriate OMF directory. If you
use the
sysaux
datafile clause
in
the create
database statement,
then the SYSAUX tablespace datafile(s) will be created in the location
you
define. Finally, if no sysaux
datafile clause
is included and OMF is not configured, Oracle creates the
SYSAUX tablespace in a default location that is OS-specific. Here is an
example
of a create
database statement
with the sysaux
datafile clause
in it:
CREATE
DATABASE my_db
DATAFILE
’c:\oracle\oradata\my_db\my_db_system_01.dbf’ SIZE 300m
SYSAUX
DATAFILE
‘c:\oracle\my_db\my_db_sysaux_01.dbf’ SIZE 100m
DEFAULT
TEMPORARY TABLESPACE
dtemp_tbs tempfile
’c:\oracle\my_db\my_db_temp_01.dbf’
SIZE 100m
UNDO
TABLESPACE undo_tbs_one
DATAFILE
’c:\oracle\my_db\my_db_undo_tbs_one_01.dbf’
SIZE 100m;
As
stated earlier, when you migrate to Oracle Database 10 g, you need to
create the SYSAUX
tablespace as a part of that migration. You do this after mounting the
database
under the new Oracle 10g database software. Once you have
mounted it,
you should open the database in migrate mode with the startup
migrate command.
Once the
database is open, you can create the SYSAUX tablespace.
■
When
migrating to Oracle Database 10g, you can create the SYSAUX tablespace
only
when the database is open in migrate mode.
■
Also,
when
migrating to Oracle Database 10g, if a tablespace is already named
SYSAUX, you
will need to remove it or rename it while you are in migrate mode.
■
Once
you
have opened your Oracle Database 10g database, you cannot drop the
SYSAUX
tablespace. If you try, an error will be returned.
■
You
cannot
rename the SYSAUX tablespace during normal database operations.
■
The
SYSAUX
tablespace cannot be transported to other databases via Oracle’s
transportable
tablespace feature.
Managing
Occupants of the
SYSAUX Tablespace
Each
set of application tables
within the SYSAUX tablespace is known as an occupant. Oracle provides
some new
views to help you monitor space usage of occupants within the SYSAUX
tablespace
and some new procedures you can use to move the occupant objects in and
out of
the SYSAUX tablespace. First, Oracle provides a new view,
V$SYSAUX_OCCUPANTS,
to manage occupants in the SYSAUX tablespace. This view allows you to
monitor
the space usage of occupant application objects in the SYSAUX
tablespace, as
shown in this example:
SELECT
substr(occupant_name,1,20) occupant_name,
substr(SCHEMA_NAME,1,20) schema_name, space_usage_kbytes FROM
v$sysaux_occupants;
In
this case, Oracle will display
the space usage for the occupants, such as the RMAN recovery catalog.
If you
determine that you need to move the occupants out of the SYSAUX
tablespace,
then the MOVE_PROCEDURE column of the V$SYSAUX_OCCUPANTS view will
indicate the
procedure that you should use to move the related occupant from the
SYSAUX
tablespace to another tablespace. This can also be a method of
“reorganizing”
your component object tables, should that be required.
Row Timestamp ( ora_rowscn and scn_to_timestamp)
Oracle 10g provides a new pseudo-column, consisting of the
committed timestamp or SCN that provides applications and users the
ability to efficiently implement optimistic locking. In previous
releases, when posting updates to the database, applications had to
read in all column values or user-specified indicator columns, compare
them with those previously fetched, and update those with identical
values. With this feature, only the row SCN needs to be retrieved and
compared to verify that the row has not changed from the time of the
select to the update. The pseudo-column for the committed SCN is called
ora_rowscn and is one of the
version query pseudo-columns. The ora_rowscn pseudo-column returns, for
each version of each row, the
system change number (SCN) of the row. You cannot use this
pseudo-column in a query to a view. However, you can use it to refer to
the underlying table when creating
a view. You can also use this pseudo-column in the WHERE clause of an
UPDATE or DELETE statement. For example:
SELECT ora_rowscn FROM used_boats:
ORA_ROWSCN
----------
791744
791744
791744
791744
791744
The above query shows us that all of the records in used_boats were
committed in the same transaction. Let's update some of the rows and
see what happens.
UPDATE used_boats SET
price=price*1.1 WHERE seller_id=1;
commit;
SELECT ora_rowscn FROM used_boats:
ORA_ROWSCN
----------
816673
816673
816673
791744
791744
Another convenient function allows you to retrieve the actual time that
the row was last altered through a conversion function called
scn_to_timestamp. Let's look at an example usage of this function.
select
scn_to_timestamp(ora_rowscn) from used_boats;
SCN_TO_TIMESTAMP(ORA_ROWSCN)
-------------------------------
30-AUG-03 11.06.08.000000000 PM
30-AUG-03 11.06.08.000000000 PM
30-AUG-03 11.06.08.000000000 PM
30-AUG-03 04.33.19.000000000 PM
30-AUG-03 04.33.19.000000000 PM
The ora_rowscn has the following restrictions: This pseudo-column is
not supported for external tables or when directly querying views.
The data from the SCN and timestamp pseudo-columns could prove
invaluable in a flashback situation.
Automated Storage Management
(ASM)
Oracle
10g introduces Automated Storage Management (ASM), a service
that provides management of disk drives. Oracle10G provides its own
disk storage management system. Database administrators are no longer
required to use hardware vendor or third-party disk volume managers to
provide striping and mirroring functionality. ASM manages the raw disks
within the Oracle database architecture. Administrators are able to
assign disks to disk groups, which can then be striped and/or mirrored
to provide high performance and high availability. During tablespace
creation, the administrator assigns the tablespace datafile to a disk
group. This differs from previous Oracle releases which required that
datafiles to be assigned to the individual disks themselves.
Interestingly
enough, Oracle’s default stripe size is one megabyte. This differs from
most disk storage management systems, which often utilize 32K or 64K
stripe sizes. Oracle found that one-megabyte stripes on disks provided
a very high level of data transfer and best met the needs of disk
intensive applications. One can only assume that advancements in disk
storage technology have allowed Oracle to access the data in
one-megabyte chunks and not drive disk utilization to unacceptable
levels.
Administrators provide disk mirroring by creating failure groups. The
DBA creates the appropriate number of failure groups to accommodate the
data requiring disk fault tolerance. ASM’s mirroring capability ranges
from the mirroring of individual datafiles to entire disk arrays,
providing administrators with a high level of flexibility when creating
fault-tolerant disk subsystems. The data is duplicated on separate
disks in one-megabyte mirror "chunks"
Administrators can choose from the following mirroring options in ASM:
- External
- no mirroring
- Normal
- data is mirrored on two separate disks. This is the default setting.
- High
Redundancy - data is mirrored on there separate disks providing
three-way mirroring capabilities.
ASM
requires its own instance, which identifies the various disk groups and
files during instance startup. The ASM instance then mounts the disks
under its control and creates an extent map, which is passed to the
database instances. ASM does not perform the I/O for the database
instances; it is only used to manage the various disk groups under its
control. ASM is only activated when individual datafiles are created or
dropped or disks are added and removed from the disk groups. When new
disks are added or removed from the disk group, ASM automatically
rebalances the files contained in the disk group while the database is
open and functioning.
ASM is able to balance the I/O for multiple databases across all
managed devices providing load balancing for multiple applications. In
Oracle10G Grid implementations, ASM is able to reassign disks from one
node to another providing additional load balancing capabilities.
Oracle Enterprise Manager (OEM) for Oracle10G and the Database
Configuration Assistant (DBCA) have been updated to allow
administrators to configure and manage databases using ASM. ASM can be
used on a variety of configurations, including Oracle9i RAC
installations. ASM is an alternative to the use of raw or cooked file
systems. ASM offers a number of features, including:
- Simplified
daily administration
- The
performance of raw disk I/O for all ASM files
- Compatibility
with any type of disk configuration, be it JBOD or complex SAN
- Use
of a specific file-naming convention to name files, enforcing an
enterprise-wide file-naming convention
- Prevention
of the accidental deletion of files, since there is no file system
interface and ASM is solely responsible for file management
- Load
balancing of data across all ASM managed disk drives, which helps
improve performance by removing disk hot spots
- Dynamic
load balancing of disks as usage patterns change and when additional
disks are added or removed
- Ability
to mirror data on different disks to provide fault tolerance
- Support
of vendor-supplied storage offerings and features
- Enhanced
scalability over other disk-management techniques
ASM
can work in concert with existing databases that use raw or cooked file
systems. You can choose to leave existing file systems in place or move
the database datafiles to ASM disks. Additionally, new database
datafiles can be placed in either ASM disks or on the preexisting file
systems. Databases can conceivably contain a mixture of file types,
including raw, cooked, OMF, and ASM (though the management of such a
system would be more complex). The details of implementing and managing
ASM are significant and would consume more than a few chapters. Review
the Oracle Database 10g documentation for more details on this new
Oracle feature.
Not only does ASM deliver near optimal performance, it is
also very simple to use. There are really only two decisions that you
have to make.
- When creating disk groups and allocating storage, most
customers will be best served by using just two disk groups – one for a
recovery area and one for their work area. However, customers with
intensive OLTP applications but no disk cache may also need a separate
disk group for online log files.
- When creating disk groups, you will need to tell ASM
whether the storage is already mirrored by the hardware, or whether ASM
should mirror the data
Because ASM is highly automated and delivers excellent
performance, better than most customers have been able to achieve
previously using established best practices, using ASM is the new best
practice for all databases under Oracle 10g
More Information about Setup
Details
SQL Model Clause or SpreadSheet
Functionality
Now, Oracle Database 10g queries and subqueries can include new syntax
that provides highly expressive spreadsheet-like array computations
with enterprise-level scalability. The computations treat
relational tables as n-dimensional arrays, allowing complex
computations while avoiding the performance problems of multiple joins
and unions. This will enhance SQL for calculations. SQL result sets can
be treated
like multidimensional arrays. Here's the Model clause syntax:
select ....
from ....
model [main]
[ reference models ]
[ partition by (<cols>)]
dimension by (<cols>)
measures (<cols>)
[ ignore nav ] | [ keep nav ]
[ rules
[ upsert | update]
[ automatic order | sequential order ]
[ iterate (n) [ until <condition>]
]
( <cell_assignment> = <expression> ...)
Examples:
To keep our examples concise, we will create a view using the Sales
History (SH) schema of the sample schema set provided with
Oracle10g. The view sales_view provides annual sums for product
sales, in dollars and units, by country, aggregated across all
channels. The view is built from a 1 million row fact table and
defined as follows:
CREATE VIEW sales_view AS
SELECT country_name country,
prod_name prod,
calendar_year year,
SUM(amount_sold) sale,
COUNT(amount_sold) cnt
FROM sales, times, customers,
countries, products
WHERE sales.time_id =
times.time_id AND
sales.prod_id =
products.prod_id AND
sales.cust_id =
customers.cust_id AND
customers.country_id =
countries.country_id
GROUP BY country_name, prod_name,
calendar_year;
As an initial example of Model, consider the following statement.
It calculates the sales values for two products and defines sales for a
new product based on the other two products.
SELECT SUBSTR(country,1,20)
country, SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country IN
('Italy','Japan')
MODEL RETURN UPDATED
ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales['Bounce', 2002] = sales['Bounce', 2001] +
sales['Bounce', 2000],
sales['Y Box',
2002] = sales['Y Box', 2001],
sales['2_Products', 2002] = sales['Bounce', 2002] + sales['Y Box',
2002])
ORDER BY country, prod, year;
The results are:
COUNTRY
PROD
YEAR SALES
--------------------
--------------- ---------- ----------
Italy
2_Products
2002 92613.16
Italy
Bounce
2002 9299.08
Italy
Y
Box
2002 83314.08
Japan
2_Products
2002 103816.6
Japan
Bounce
2002 11631.13
Japan
Y
Box
2002 92185.47
This statement partitions data by country, so the formulas are applied
to data of one country at a time. Our sales fact data ends
with 2001, so any rules defining values for 2002 or later will
insert new cells. The first rule defines the sales of a video
games called "Bounce" in 2002 as the sum of its sales in 2000 and 2001.
The second rule defines the sales for Y Box in 2002 to be the same
value they were for 2001. The third rule defines a product
called "2_Products," which is simply the sum of the Bounce and Y Box
values for 2002. Since the values for 2_Products are
derived from the results of the two prior formulas, the rules for
Bounce and Y Box must be executed before the 2_Products
rule.
Note the following characteristics of the example above:
- The "RETURN UPDATED ROWS" clause following the keyword MODEL
limits the results returned to just those rows that were created
or updated in this query. Using this clause is a convenient way
to limit result sets to just the newly calculated values. We will
use the RETURN UPDATED ROWS clause throughout our examples.
- The keyword "RULES," shown in all our examples at the start
of the formulas, is optional, but we include it for easier
reading.
- Likewise, many of our examples do not require ORDER BY on the
Country column, but we include the specification for convenience in
case readers want to modify the examples and use multiple countries.
This section examines the techniques for referencing cells and values
in a SQL Model. The material on cell references is essential to
understanding the power of the SQL Model clause.
What if we want to update the existing sales value for the product
Bounce in the year 2000, in Italy, and set it to 10? We could do
it with a query like this, which updates the existing cell for the
value:
SELECT SUBSTR(country,1,20)
country, SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED
ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES ( sales['Bounce', 2000] = 10 )
ORDER BY country, prod, year;
COUNTRY
PROD
YEAR SALES
--------------------
--------------- ---------- ----------
Italy
Bounce
2000 10
The formula in the query above uses "positional cell reference."
The value for the cell reference is matched to the appropriate
dimension based on its position in the expression. The
DIMENSION BY clause of the model determines the position assigned to
each dimension: in this case, the first position is product
("prod") and the second position is year.
What if we want to create a forecast value of the sales for the
product Bounce in the year 2005, in Italy, and set it to 20? We
could do it with a query like this:
SELECT SUBSTR(country,1,20)
country, SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED
ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales['Bounce', 2005] = 20 )
ORDER BY country, prod, year;
COUNTRY
PROD
YEAR SALES
--------------------
--------------- ---------- ----------
Italy
Bounce
2005 20
The formula in the query above sets the year value to 2005 and thus
creates a new cell in the array.
NOTE: If we want to create new cells, such as sales projections
for future years, we must use positional references or FOR loops
(discussed later in this paper). That is, positional reference
permits both updates and inserts into the array. This is called
the "upsert" process.
What if we want to update the sales for the product Bounce in all years
after 1999 where we already have values recorded? Again, we
will change values for Italy and set them to 10. We could do it
with a query like this:
SELECT SUBSTR(country,1,20)
country, SUBSTR(prod,1,15) prod, year, sales
FROM sales_view
WHERE country='Italy'
MODEL RETURN UPDATED
ROWS
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale sales)
RULES (
sales[prod='Bounce', year>1999] = 10 )
ORDER BY country, prod, year;
COUNTRY
PROD
YEAR SALES
--------------------
--------------- ---------- ----------
Italy
Bounce
2000 10
Italy
Bounce
2001 10
The formula in the query above uses "symbolic cell
reference." With symbolic cell references, the standard SQL
conditions are used to determine the cells which are part of a
formula. You can use conditions such as <,>, IN, and
BETWEEN. In this example the formula applies to any cell which
has product value equal to Bounce and a year value greater than
1999. The example shows how a single formula can access multiple
cells.
NOTE: Symbolic references are very powerful, but they are solely
for updating existing cells: they cannot create new cells such as
sales projections in future years. If a cell reference uses
symbolic notation in any of its dimensions, then its formula will
perform only updates. Later we will discuss FOR loops in the
Model clause, which provide a concise technique for creating multiple
cells from a single formula.
Transportable Tablespaces
In previous releases, the transportable tablespace feature could only
be used to transfer data to databases running on the same operating
system. In 10G, Oracle allows the tablespaces to be transferred to
databases running
on different operating systems as long as the OS byte orders are
identical. In addition, both databases
must have their COMPATIBLE initialization parameter set to 10.0.0 or
higher before they can use the cross-platform transportable tablespace
feature.
How do you know which operating systems follow which byte order?
Instead of guessing or having to search the internet, simply issue the
query:
select * from v$transportable_platform order by platform_id;
PLATFORM_ID
PLATFORM_NAME
ENDIAN_FORMAT
-----------
----------------------------------- --------------
1 Solaris[tm] OE
(32-bit)
Big
2 Solaris[tm] OE
(64-bit)
Big
3 HP-UX
(64-bit)
Big
4 HP-UX IA
(64-bit)
Big
5 HP Tru64
UNIX
Little
6 AIX-Based Systems
(64-bit) Big
7 Microsoft Windows IA (32-bit)
Little
8 Microsoft Windows IA (64-bit)
Little
9 IBM zSeries Based
Linux
Big
10 Linux IA
(32-bit)
Little
11 Linux IA
(64-bit)
Little
12 Microsoft Windows 64-bit for AMD Little
13 Linux 64-bit for
AMD
Little
15 HP Open
VMS
Little
16 Apple Mac
OS
Big
Suppose you want to transport a tablespace USERS from a host machine
SRC1, running Linux on Intel Architecture to machine TGT1, running
Microsoft Windows. Both the source and target platforms are of little
endian type. The datafile for the tablespace USERS is users_01.dbf. You
would follow an approach similar to the following.
1. Make the tablespace READ ONLY:
alter
tablespace users read only;
2. Export the tablespace. From the OS prompt, issue:
exp
tablespaces=users transport_tablespace=y file=exp_ts_users.dmp
The file exp_ts_users.dmp contains only
metadata—not the contents of the tablespace USERS—so it will be very
small.
3. Copy the files exp_ts_users.dmp and users_01.dbf to the
host TGT1. If you were using FTP, you would specify the binary option.
4. Plug the tablespace into the database. From the OS
command prompt, you would issue:
imp
tablespaces=users transport_tablespace=y file=exp_ts_users.dmp
datafiles='users_01.dbf'
After Step 4, the target database will have a tablespace named USERS
and the contents of the tablespace will be available.
If the platforms are of different endianness, how will you achieve
transferability? As I explained earlier, the byte order of the target
machine, if different than the source, will read the data file
incorrectly, making the mere copying of the data files impossible. But
don't lose heart; help is available from the Oracle 10g RMAN utility,
which supports the conversion of datafiles from one byte order to
another.
In the above example, if the host SRC1 runs on Linux (little endian)
and the target host TGT1 runs on HP-UX (big endian), you need to
introduce another step between Steps 3 and 4 for conversion. Using
RMAN, you would convert the datafile from Linux to HP-UX format on the
source machine SRC1 (assuming you have made the tablespace read only):
RMAN> convert tablespace users to platform 'HP-UX (64-bit)'
format='/home/oracle/rman_bkups/%N_%f';
The steps for cross platform transportable tablespaces are:
* Make tablepace read only
* Use the data pump export to pull out the metadata for the set of
tablespace.
* expdp <connection string> dumpfile=<file name>
directory=<folder> transportable_tablespaces= <tbs list>
* Use RMAN to convert the tablespace data files to a format suitable
for the new platform. Multiple pairs of strings can be placed in the
db_file_name_convert clause. The new file names will have the strings
replaced to prevent the same file name being generated.
* Connect to the target using rman, at the prompt type
* convert tablespace <tbs name> to platform '<platform
name>' db_file_name_convert='<str1>','<str2>'
[,'<str1>','<str2>'...]
* Copy the files to the new system. If using ftp, make sure it is in
binary mode!
* Import the meta data from the dump file into the target database, and
put the files in the appropriate locations. Rename the files if
necessary in the database.
* impdp <connection string> dumpfile=<file name>
directory=<folder> transport_datafiles='<file>'
[,<file>...]
* The tablespace will be in read only mode as that was it's mode when
the data was exported. Put the tablespace in read write if required.
Regular
expressions
To harness the power of regular expressions, you can exploit the newly
introduced Oracle SQL REGEXP_LIKE operator and the REGEXP_INSTR,
REGEXP_SUBSTR, and REGEXP_REPLACE functions. You will see how this new
functionality supplements the existing LIKE operator and the INSTR,
SUBSTR, and REPLACE functions. In fact, they are similar to the
existing operator and functions but now offer powerful pattern-matching
capabilities. The searched data can be simple strings or large volumes
of text stored in the database character columns.
|
Table 1: Anchoring Metacharacters
| Metacharacter |
Description |
| ^ |
Anchor the expression to
the start of a line |
| $ |
Anchor the expression to
the end of a line |
Table 2: Quantifiers, or Repetition
Operators
| Quantifier |
Description |
| * |
Match 0 or more times |
| ? |
Match 0 or 1 time |
| + |
Match 1 or more times |
| {m} |
Match exactly m
times |
| {m,} |
Match at least m
times |
| {m, n} |
Match at least m
times but no more than n times |
Table 3: Predefined POSIX Character Classes
| Character Class |
Description |
| [:alpha:] |
Alphabetic characters |
| [:lower:] |
Lowercase alphabetic
characters |
| [:upper:] |
Uppercase alphabetic
characters |
| [:digit:] |
Numeric digits |
| [:alnum:] |
Alphanumeric characters |
| [:space:] |
Space characters
(nonprinting), such as carriage return, newline, vertical tab, and form
feed |
| [:punct:] |
Punctuation characters |
| [:cntrl:] |
Control characters
(nonprinting) |
| [:print:] |
Printable characters |
Table 4: Alternate Matching and Grouping of
Expressions
| Metacharacter |
Description |
| | |
Alternation |
Separates alternates,
often used with grouping operator () |
| ( ) |
Group |
Groups subexpression into
a unit for alternations, for quantifiers, or for backreferencing |
| [char] |
Character list |
Indicates
a character list; most metacharacters inside a character list are
understood as literals, with the exception of character classes, and
the ^ and - metacharacters |
Table 5: The REGEXP_LIKE Operator
| Syntax |
Description |
REGEXP_LIKE(source_string, pattern
[, match_parameter]) |
source_string
supports character datatypes (CHAR, VARCHAR2, CLOB, NCHAR,
NVARCHAR2, and NCLOB but not LONG).
The pattern parameter is
another name for the regular expression. match_parameter
allows optional parameters such as handling the newline character,
retaining multiline formatting, and providing control over
case-sensitivity. Example:
SELECT ename
FROM emp WHERE REGEXP_LIKE (ename, '^J.(N|M),S$');
ENAME
-----
JONES
JAMES
In this example, we tell Oracle to retrieve any values that start with
J, followed by any letter, then N or M, then any letter, then S
Another one, the following regular expression would match fly, flying,
flew, flown, and flies:
SELECT c1 FROM t1 WHERE REGEXP_LIKE(c1, ‘fl(y(ing)?|(ew)|(own)|(ies))’);
|
Table 6: The REGEXP_INSTR Function
| Syntax |
Description |
REGEXP_INSTR(source_string, pattern
[, start_position
[, occurrence
[, return_option
[, match_parameter]]]]) |
This function looks for a pattern and returns the first position of the pattern.
Optionally, you can indicate the start_position you want to begin the search. The occurrence parameter defaults to 1 unless you indicate that you
are looking for a subsequent occurrence. The default value of the return_option
is 0, which returns the starting position of the pattern; a value of 1
returns the starting position of the next character following the
match. Example:
SELECT
REGEXP_INSTR('5035 Forest Run Trace, Alpharetta, GA', '[^ ]+', 1, 6]
"Test" FROM dual;
TEST
36
In this example, we are telling Oracle to examine the string, looking
for occurrences of one or more non-blank characters and to return the
sixth occurrence of one or more non-blank character.
|
Table 7: Explanation of 5-digit + 4
Zip-Code Expression
| Syntax |
Description |
| |
Empty space that must be
matched |
| [:digit:] |
POSIX numeric digit class
|
| ] |
End of character list |
| {5} |
Repeat exactly five
occurrences of the character list |
| ( |
Start of subexpression |
| - |
A literal hyphen, because
it is not a range metacharacter inside a character list |
| [ |
Start of character list |
| [:digit:] |
POSIX [:digit:] class |
| [ |
Start of character list |
| ] |
End of character list |
| {4} |
Repeat exactly four
occurrences of the character list |
| ) |
Closing parenthesis, to
end the subexpression |
| ? |
The ? quantifier matches the grouped subexpression 0 or 1
time thus making the 4-digit code optional |
| $ |
Anchoring metacharacter,
to indicate the end of the line |
Table 8: The REGEXP_SUBSTR Function
| Syntax |
Description |
REGEXP_SUBSTR(source_string, pattern
[, position [, occurrence
[, match_parameter]]]) |
The REGEXP_SUBSTR function returns the substring that matches the
pattern. Example:
SELECT
REGEXP_SUPSTR('5035 Forest Run Trace, Alpharetta, GA',',[^,]+,') "Test"
FROM dual;
Test
------------------
, Alpharetta,
In this example we search for a comma, followed by one or more
characters immediately followed by a comma.
|
Table 9: The REGEXP_REPLACE
Function
| Syntax |
Description |
REGEXP_REPLACE(source_string, pattern
[, replace_string [, position
[,occurrence, [match_parameter]]]]) |
This function replaces the
matching pattern with a specified replace_string, allowing complex search-and-replace operations.
Example:
SELECT
REGEXP_REPLACE(emp_phone,
'([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})',
'(\1) \2-\3') "Test"
FROM emp;
Test
----------------
(404) 444-4321
(404) 555-5432
(404) 666-6543
In this eample we search for a pattern of numbers that looks like a
European phone number listing such as 111.222.3333 and convert it to a
normal USA format listing of (111) 222-3333.
|
Table 10: Backreference Metacharacter
| Metacharacter |
Description |
| \digit |
Backslash |
Followed by a digit
between 1 and 9, the backslash matches the preceding digit-th
parenthesized subexpression.
(Note: The backslash has
another meaning in regular expressions; depending on the context it can
also mean the Escape character |
Table 11: Explanation of Pattern-Swap
Regular Expression
| Regular-Expression Item |
Description |
| ( |
Start of first
subexpression |
| . |
Match any single
character except a newline |
| * |
Repetition operator,
matches previous .
metacharacter 0 to n times |
| ) |
End of first
subexpression; result of the match is captured in \1
(In this example, it's Ellen.) |
| |
Empty space that needs to
be present |
| ( |
Start of the second
subexpression |
| . |
Match any single
character except a newline |
| * |
Repetition operator
matches the previous .
metacharacter 0 to n times |
| ) |
End of second
subexpression; result of this match is captured in \2
(In this example, it stores Hildi.) |
| |
Empty space |
| ( |
Start of third
subexpression |
| . |
Match any single
character except a newline |
| * |
Repetition operator
matches . metacharacter 0 to n
times |
| ) |
End of third
subexpression; result of this match is captured in \3
(In this example, it holds Smith.) |
Table 12: Explanation of the Social Security
Number Regular Expression
| Regular-Expression Item |
Description |
| ^ |
Start of line character
(Regular expression cannot have any leading characters before the
match.) |
| ( |
Start subexpression and
list alternates separated by the | metacharacter |
| [ |
Start of character list |
| [:digit:] |
POSIX numeric digit class
|
| ] |
End of character list |
| {3} |
Repeat exactly three
occurrences of character list |
| - |
A hyphen |
| [ |
Start of character list |
| [:digit:] |
POSIX numeric digit class
|
| ] |
End of character list |
| {2} |
Repeat exactly two
occurrences of character list |
| - |
Another hyphen |
| [ |
Start of character list |
| [:digit:] |
POSIX numeric digit class
|
| ] |
End of character list |
| {4} |
Repeat exactly four
occurrences of character list |
| | |
Alternation
metacharacter; ends the first choice and starts the next alternate
expression |
| [ |
Start of character list |
| [:digit:] |
POSIX numeric digit
class. |
| ] |
End of character list |
| {9} |
Repeat exactly nine
occurrences of character list |
| ) |
Ending parenthesis, to
close the subexpression group used for alternation |
| $ |
Anchoring metacharacter,
to indicate the end of the line; no extra characters can follow the
pattern |
|
|
 |
Constraints
You can use Oracle Regular Expressions to filter data that is allowed
to enter a table by using constraints. The following example shows how
a column could be configured to allow only alphabetical characters
within a VARCHAR2 column. This will disallow all punctuation, digits,
spacing elements, and so on, from entering the table.
CREATE TABLE t1 (c1 VARCHAR2(20),
CHECK (REGEXP_LIKE(c1, '^[[:alpha:]]+$')));
INSERT INTO t1 VALUES ('newuser');
1 row created.
INSERT INTO t1 VALUES
('newuser1');
ORA-02290: check constraint violated
INSERT INTO t1 VALUES
('new-user');
ORA-02290: check constraint violated
Performance Considerations
Due to the inherent complexity of the compile and match logic, regular
expression functions can perform slower than their non-regular
expression counter parts.
Data Pump
Data Pump replaces EXP and IMP (exp and imp were not removed from 10G).
It provides high speed, parallel, bulk data and metadata movement of
Oracle database contents across platforms and database versions. Oracle
states that Data Pump’s performance on data retrieval is 60% faster
than Export and 15% to 20% faster on data input than Import. If a data
pump job is
started and fails for any reason before it has finished, it can be
restarted at a later time. The commands to start the data pump are
expdb and impdb, respectively. The data pump
uses files as well as
direct network transfer. Clients can detach and reconnect from/to the
data pump. It can be monitored through several views like
dba_datapump_jobs. The Data
Pump’s public API is the DBMS_DATAPUMP package. More information HERE
Two access methods are supported: Direct Path (DP) and External Tables
(ET). DP is the fastest but does not support intra-partition
parallelism. ET does and therefore may be chosen to load or unload a
very large table or partition. Data Pump export and import are not
compatible with the old exp &
imp. So if you need to import into a pre-10g database it is best to
stick with the original export utility.
To use Data Pump you must have EXP_FULL_DATABASE or IMP_FULL_DATABASE
depending the operation to perform. These
allow you to expdp & impdp across ownership for items such as
grants, resource plans, schema definitions, and re-map, re-name, or
re-distribute database objects or structures. By definition, Oracle
gives permission to the objects in a DIRECTORY
that a user would not normally have access to.
Data Pump runs
only on the server side. You may initiate the export from a client but
the job(s) and the files will run inside an Oracle server. There will
be no
dump files (expdat.dmp) or log files created on your local
machine.
Oracle creates dump and log files through DIRECTORY objects. So
before you can use Data Pump you must create a DIRECTORY object.
Example:
CREATE DIRECTORY datapump AS
'C:\user\datafile\datapump';
Then, as you use Data Pump you can reference this DIRECTORY as a
parameter for export where you would like the dump or log files to end
up.
Now the Examples
We are all familiar with the FULL database export. Data Pump easily
performs this with the following command line:
expdp ananda/abc123 tables=CASES
directory=DPDATA1 dumpfile=expCASES.dmp job_name=CASES_EXPORT
Notice there are just a
few name changes and instead of specifying the directory path in the
file locations the additional parameter for your DIRECTORY is supplied.
This command line assumes you are on the database server and
environment variables are properly set for a direct connection. Note
the parameter job_name above, a special one not found in the original
export. All Data Pump work is done though jobs. Data Pump jobs, unlike
DBMS jobs, are merely server processes that process the data on behalf
of the main process. The main process, known as a master control
process, coordinates this effort via Advanced Queuing; it does so
through a special table created at runtime known as a master table.
Export monitoring:
While Data Pump Export (DPE) is running, press Control-C; it will stop
the display of the messages on the screen, but not the export process
itself. Instead, it will display the DPE prompt as shown below. The
process is now said to be in "interactive" mode:
Export>
This approach allows several commands to be entered on that DPE job. To
find a summary, use the STATUS command at the prompt:
Export> status
Job: CASES_EXPORT
Operation:
EXPORT
Mode:
TABLE
State:
EXECUTING
Degree: 1
Job Error Count: 0
Dump file: /u02/dpdata1/expCASES.dmp
bytes written = 2048
Worker 1 Status:
State:
EXECUTING
Object Schema: DWOWNER
Object Name: CASES
Object Type: TABLE_EXPORT/TBL_TABLE_DATA/TABLE/TABLE_DATA
Completed Objects: 1
Total Objects: 1
Completed Rows: 4687818
Remember, this is merely the status display. The export is working in
the background. To continue to see the messages on the screen, use the
command CONTINUE_CLIENT from the Export> prompt.
While Data Pump jobs are running, you can pause them by issuing
STOP_JOB on the DPE or DPI prompts and then restart them with
START_JOB. This functionality comes in handy when you run out of space
and want to make corrections before continuing.
FINE-GRAINED OBJECT SELECTION
One could only choose to include or ignore indexes, triggers, grants
and constraints with original exp and imp. With various client
parameters, a Data Pump job can include or exclude virtually any type
of object and any subset of objects within a type.
EXCLUDE
The exclude parameter allows any database object type to be excluded
from an export or import operation. The optional name qualifier allows
you finer selectivity within each object type specified. For example,
the following three lines in a parameter file:
Exclude=function
Exclude=procedure
Exclude=package:”like ‘PAYROLL%’ “
Would exclude all functions, procedures and packages with names
starting with ‘PAYROLL’ from the job.
INCLUDE
The include parameter includes only the specified object types and
objects in an operation. For example, if the above three specifications
were INCLUDE parameters in a full database export, only functions,
procedures and packages with names starting with ‘PAYROLL’ would be
written to the dumpfile set..
CONTENT
The content parameter allows one to request for the current operation
just metadata, just data or both. Original exp’s ‘ROWS=N’ parameter was
equivalent to content=metadata_only, but there is no equivalent for
content=data_only.
QUERY
The query parameter operates much as it did in original export, but
with two significant enhancements:
1. It can be qualified with a table name such that it
only applies to that table
2. It can be used during import as well as export.
table_exists_action
* skip
* append
* truncate
* replace
Examples:
To export only a few specific objects--say, function FUNC1 and
procedure PROC1--you could use
expdp ananda/iclaim
directory=DPDATA1 dumpfile=expprocs.dmp
include=PROCEDURE:\"=\'PROC1\'\",FUNCTION:\"=\'FUNC1\'\"
This dumpfile serves as a backup of the sources. You can even use it to
create DDL scripts to be used later. A special parameter called SQLFILE
allows the creation of the DDL script file.
impdp ananda/iclaim
directory=DPDATA1 dumpfile=expprocs.dmp sqlfile=procs.sql
This instruction creates a file named procs.sql in the directory
specified by DPDATA1, containing the scripts of the objects inside the
export dumpfile. This approach helps you create the sources quickly in
another schema.
Using the parameter INCLUDE allows you to define objects to be included
or excluded from the dumpfile. You can use the clause
INCLUDE=TABLE:"LIKE 'TAB%'" to export only those tables whose name
start with TAB. Similarly, you could use the construct
INCLUDE=TABLE:"NOT LIKE 'TAB%'" to exclude all tables starting with
TAB. Alternatively you can use the EXCLUDE parameter to exclude
specific objects.
I/O BANDWIDTH IS MOST IMPORTANT FACTOR
It is important to make sure there is sufficient I/O bandwidth to
handle the number of parallel threads specified; otherwise performance
can actually degrade with additional parallel threads. Care should be
taken to make sure the dumpfile set is located on spindles other than
those holding the instance’s data files. Wildcard file support makes it
easy to spread the I/O load over multiple spindles. For example, a
specification such as:
Dumpfile=dmpdir1:full1%u.dmp,dmpdir2:full2%u.dmp
Dumpfile=dmpdir3:full3%u.dmp,dmpdir4:full4%u.dmp
will create files named full101.dmp, full201.dmp, full301.dmp,
full401.dmp, full102.dmp, full202.dmp, full302.dmp, etc. in a
round-robin fashion across the four directories pointed to by the four
directory objects.
In parallel mode, the status screen will show four worker processes.
(In default mode, only one process will be visible.) All worker
processes extract data simultaneously and show their progress on the
status screen
INITIALIZATION PARAMETERS
Essentially no tuning is required to achieve maximum Data Pump
performance. Initialization parameters should be sufficient out of the
box.
- Make sure disk_asynch_io
remains TRUE: It has no effect on those platforms whose file systems
already support asynchronous I/O, but those that don’t are
significantly impacted by a value of FALSE.
- db_block_checksum’s
default value is FALSE, but if an integrity issue is being investigated
requiring this to be set to TRUE, its impact on data loading and
unloading is minimal; less than 5%.
Some
Examples
expdp scott/tiger tables=EMP,DEPT directory=TEST_DIR
dumpfile=EMP_DEPT.dmp logfile=expdpEMP_DEPT.log
impdp scott/tiger tables=EMP,DEPT directory=TEST_DIR
dumpfile=EMP_DEPT.dmp logfile=impdpEMP_DEPT.log
The TABLE_EXISTS_ACTION=APPEND parameter allows data to be imported
into existing tables.
The OWNER parameter of exp has been replaced by the SCHEMAS parameter
which is used to specify the schemas to be exported. The following is
an example of the schema export and import syntax:
expdp scott/tiger schemas=SCOTT directory=TEST_DIR dumpfile=SCOTT.dmp
logfile=expdpSCOTT.log
impdp scott/tiger schemas=SCOTT directory=TEST_DIR dumpfile=SCOTT.dmp
logfile=impdpSCOTT.log
The FULL parameter indicates that a complete database export is
required. The following is an example of the full database export and
import syntax:
expdp system/password full=Y directory=TEST_DIR dumpfile=DB10G.dmp
logfile=expdpDB10G.log
impdp system/password full=Y directory=TEST_DIR dumpfile=DB10G.dmp
logfile=impdpDB10G.log
Data pump performance can be improved by using the PARALLEL parameter.
This should be used in conjunction with the "%U" wildcard in the
DUMPFILE parameter to allow multiple dumpfiles to be created or read:
expdp scott/tiger schemas=SCOTT directory=TEST_DIR parallel=4
dumpfile=SCOTT_%U.dmp logfile=expdpSCOTT.log
The INCLUDE and EXCLUDE parameters can be used to limit the
export/import to specific objects. When the INCLUDE parameter is used,
only those objects specified by it will be included in the export. When
the EXCLUDE parameter is used all objects except those specified by it
will be included in the export:
expdp scott/tiger schemas=SCOTT include=TABLE:\"IN (\'EMP\',
\'DEPT\')\" directory=TEST_DIR dumpfile=SCOTT.dmp logfile=expdpSCOTT.log
expdp scott/tiger schemas=SCOTT exclude=TABLE:\"= \'BONUS\'\"
directory=TEST_DIR dumpfile=SCOTT.dmp logfile=expdpSCOTT.log
Introduction to Monitoring Data Pump
A simple way to gain insight into the status of a Data Pump job is
to look into a few views maintained within the Oracle instance the Data
Pump job is running. These views are DBA_DATAPUMP_JOBS,
DBA_DATAPUMP_SESSIONS, and V$SESSION_LOGOPS. These views are critical
in the monitoring of your export jobs so, as we will see in a later
article, you can attach to a Data Pump job and modify the execution of
the that job.
DBA_DATAPUMP_JOBS
This view will show the active Data Pump jobs, their state, degree of
parallelism, and the number of sessions attached.
select * from dba_datapump_jobs
OWNER_NAME JOB_NAME OPERATION JOB_MODE STATE DEGREE ATTACHED_SESSIONS
---------- ---------------------- ---------- ---------- ------------- --------- -----------------
JKOOP SYS_EXPORT_FULL_01 EXPORT FULL EXECUTING 1 1
JKOOP SYS_EXPORT_SCHEMA_01 EXPORT SCHEMA EXECUTING 1 1
DBA_DATAPUMP_SESSIONS
This view give gives the SADDR that assist in determining why a Data
Pump session may be having problems. Join to the V$SESSION view for
further information.
SELECT * FROM DBA_DATAPUMP_SESSIONS
OWNER_NAME JOB_NAME SADDR
---------- ------------------------------ --------
JKOOPMANN SYS_EXPORT_FULL_01 225BDEDC
JKOOPMANN SYS_EXPORT_SCHEMA_01 225B2B7C
V$SESSION_LONGOPS
This view helps determine how well a Data Pump export is doing. It also
shows you any operation that is taking long time to execute.
Basically gives you a progress indicator through the MESSAGE column.
select username, opname, target_desc,
sofar, totalwork, message
from V$SESSION_LONGOPS
USERNAME OPNAME TARGET_DES SOFAR TOTALWORK MESSAGE
-------- -------------------- ---------- ----- ---------- ------------------------------------------------
JKOOP SYS_EXPORT_FULL_01 EXPORT 132 132 SYS_EXPORT_FULL_01:EXPORT:132 out of 132 MB done
JKOOP SYS_EXPORT_FULL_01 EXPORT 90 132 SYS_EXPORT_FULL_01:EXPORT:90 out of 132 MB done
JKOOP SYS_EXPORT_SCHEMA_01 EXPORT 17 17 SYS_EXPORT_SCHEMA_01:EXPORT:17 out of 17 MB done
JKOOP SYS_EXPORT_SCHEMA_01 EXPORT 19 19 SYS_EXPORT_SCHEMA_01:EXPORT:19 out of 19 MB done
The original export utility (exp) may or may not be going away soon.
The documentation clearly states that Data Pump will handle data types
that exp will not and we should begin our migration to this new
utility. Except for those instances where you must export between 10g
and pre-10g databases. This article stepped through the process of
performing FULL exports as these are typical in Oracle environment. If
you are doing schema or table exports the change is simple and we will
visit those in subsequent parts to this series.
Another example:
We want to check how much a specific session (sid=9) needs to perform
in order to finish. So using the PRINT_TABLE function described in AskTom.com
you we can do the following:
set serveroutput on size 999999
exec print_table('select * from v$session_longops where sid = 9');
SID : 9
SERIAL# : 68
OPNAME : Transaction Rollback
TARGET :
TARGET_DESC : xid:0x000e.01c.00000067
SOFAR : 10234
TOTALWORK : 20554
UNITS : Blocks
START_TIME : 07-dec-2003 21:20:07
LAST_UPDATE_TIME : 07-dec-2003 21:21:24
TIME_REMAINING : 77
ELAPSED_SECONDS : 77
CONTEXT : 0
MESSAGE : Transaction Rollback: xid:0x000e.01c.00000067 :
10234 out of 20554 Blocks done
USERNAME : SYS
SQL_ADDRESS : 00000003B719ED08
SQL_HASH_VALUE : 1430203031
SQL_ID : 306w9c5amyanr
QCSID : 0
Let's examine each of these columns carefully.
There may be more than one long running operation in the
session—especially because the view contains the history of all long
running operations in previous sessions. The column OPNAME shows that
this record is for "Transaction Rollback," which points us in the right
direction. The column TIME_REMAINING shows the estimated remaining time
in seconds, described earlier and the column ELAPSED_SECONDS shows the
time consumed so far. So how does this
table offer an estimate of the remaining time? Clues can be found in
the columns TOTALWORK, which shows the total amount of "work" to do,
and SOFAR, which shows how much has been done so far. The unit of work
is shown in column UNITS. In this case, it's in blocks; therefore, a
total of 10,234 blocks have been rolled back so far, out of 20,554. The
operation so far has taken 77 seconds. Hence the remaining blocks will
take: 77 * ( 10234 / (20554-10234) ) ≈
77 seconds But you don't have to take
that route to get the number; it's shown clearly for you. Finally, the
column LAST_UPDATE_TIME shows the time as of which the view contents
are current, which will serve to reinforce your interpretation of the
results.
Automatic Workload Repository (AWR)
AWR periodically gathers and
stores system activity and workload data which is then analyzed by
ADDM. Every layer of Oracle is equipped with instrumentation that
gathers information on workload which will then be used to make
self-managing decisions. AWR is the place where this data is stored.
AWR looks periodically at the system performance (by default every 60
minutes) and stores the information found (by default up to 7 days).
This allows to retrieve information about workload changes and database
usage patterns. AWR runs by default and Oracle states that it does not
add a noticeable level of overhead. A new
background server process (MMON) takes snapshots of the in-memory
database statistics (much like STATSPACK) and stores this information
in the repository. MMON also provides Oracle10G with a server initiated
alert feature, which notifies database administrators of potential
problems (out of space, max extents reached, performance thresholds,
etc.). The information is stored in the sysaux tablespace. This
information is the basis for all self-management decisions. For
example, it is thus possible to identify the SQL statements that have
the
* largest CPU consumption
* most buffer gets
* disk reads
* most parse calls
* shared memory
To access from OEM, click on Administration, then "Automatic Workload
Repository" where you can perform all the tasks described here.
Both the snapshot frequency and retention time can be modified by the
user. To see the present settings, you could use:
select snap_interval, retention
from dba_hist_wr_control;
SNAP_INTERVAL RETENTION
------------------- -------------------
+00000 01:00:00.0 +00007 00:00:00.0
This SQL shows that the snapshots are taken every hour and the
collections are retained 7 seven days
The default collection for AWR data is 7 days, so many Oracle
DBAs will increase the storage of detail information over longer time
periods using the new package
DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS. Remember that if you
increase it, is recommended to extend the SYSAUX tablespace. This will
change the
retention period and collection frequency to provide you with longer
timer periods of data:
execute
dbms_workload_repository.modify_snapshot_settings(
interval => 60,
retention => 43200);
In this example the retention period is specified as 30 days (43200
min) and the interval between each snapshot is 60 min. It seems that
STATSPACK is not needed
any more!!!
10G R2's Enterprise Manager allows administrators to transfer Automatic
Workload Repository snapshots to other 10G R2 workload repositories for
offline analysis. This is accomplished by the administrator specifying
a snapshot range and extracting the AWR data to a flat file. The flat
file is then loaded into a user-specified staging schema in the target
repository. To complete the transfer, the data is copied from the
staging schema into the target repository's SYS schema. The data in the
SYS schema is then used as the source for the ADDM analysis.
If the snapshot range already exists in the SYS or staging schemas, the
data being imported is ignored. All data in snapshot ranges that does
not conflict with existing data is loaded. 10G R2 contains a new
package DBMS_SWRF_INTERNAL to provide AWR snapshot export and import
functionality.
The example below exports a snapshot range starting with 100 and ending
at 105 to the output dump file 'awr_wmprod1_101_105' in the directory
'/opt/oracle/admin/awrdump/wmprod1':
BEGIN
DBMS_SWR_INTERNAL.AWR_EXTRACT(
DMPFILE
=>'awr_export_wmprod1_101_105',
DMPDIR =>
'/opt/oracle/admin/awrdump/wmprod1',
BID => 101,
EID => 105)
We then use the AWR_LOAD procedure to load the data into our target
repository staging schema:
BEGIN
DBMS_SWR_INTERNAL.AWR_LOAD(
SCHNAME => 'foot',
DMPFILE
=>'awr_export_wmprod1_101_105',
DMPDIR =>
'/opt/oracle/admin/awrdump/wmprod1')
The last step is to transfer the data from our staging schema (FOOT) to
the SYS schema for analysis:
BEGIN
DBMS_SWR_INTERNAL.MOVE_TO_AWR(
SCHNAME => 'foot',)
AWR capability is best explained quickly by the report it produces from
collected statistics and metrics, by running the script awrrpt.sql in
the $ORACLE_HOME/rdbms/admin directory. This script looks like
Statspack; it shows all the AWR snapshots available and
asks for two specific ones as interval boundaries. It produces two
types of output: text format, similar to that of the Statspack report
but from the AWR repository, and the default HTML format, complete with
hyperlinks to sections and subsections, providing quite a user-friendly
report. Run the script and take a look at the report now to get an idea
about capabilities of the AWR.
If you want to explore the AWR repository, feel free to do so. The AWR
consists of a number of tables owned by the SYS schema and stored in
the SYSAUX tablespace. All AWR table names starts with
the identifier “WR.” Following WR is a mnemonic that identifies the
type designation of the table followed by a dollar sign ($). AWR tables
come with three different type designations:
- Metadata (WRM$)
- Historical data (WRH$)
- AWR tables related to advisor functions (WRI$)
Most of the AWR table names are pretty self-explanatory, such as
WRM$_SNAPSHOT or WRH$_ACTIVE_SESSION_HISTORY.
Also Oracle Database 10g offers several DBA tables that allow you to
query the AWR repository. The tables all start with DBA_HIST, followed
by a name that describes the table. These include tables such as
DBA_HIST_FILESTATS, DBA_HIST_DATAFILE, or DBA_HIST_SNAPSHOT.
You can create a manula snapshot using:
EXEC dbms_workload_repository.create_snapshot;
You can see what snapshots are currently in the AWR by using the
DBA_HIST_SNAPSHOT view as seen in this example:
SELECT snap_id,
to_char(begin_interval_time,'dd/MON/yy hh24:mi') Begin_Interval,
to_char(end_interval_time,'dd/MON/yy hh24:mi') End_Interval
FROM dba_hist_snapshot
ORDER BY 1;
SNAP_ID
BEGIN_INTERVAL END_INTERVAL
---------- --------------- ---------------
954 30/NOV/05 03:01 30/NOV/05 04:00
955 30/NOV/05 04:00 30/NOV/05 05:00
956 30/NOV/05 05:00 30/NOV/05 06:00
957 30/NOV/05 06:00 30/NOV/05 07:00
958 30/NOV/05 07:00 30/NOV/05 08:00
959 30/NOV/05 08:00 30/NOV/05 09:00
Each snapshot is assigned a unique snapshot ID that is reflected in the
SNAP_ID column. The
END_INTERVAL_TIME column displays the time that the actual snapshot was
taken. Sometimes you might want to drop snapshots manually. The
dbms_workload_repository.drop_snapshot_range procedure can be used to
remove a range of snapshots from the AWR. This procedure takes two
parameters, low_snap_id and high_snap_id, as seen in this example:
EXEC
dbms_workload_repository.drop_snapshot_range(low_snap_id=>1107,
high_snap_id=>1108);
AWR
Baselines
It is frequently a good idea to create a baseline in the AWR. A
baseline is defined as a range of snapshots that can be used to compare
to other pairs of snapshots. The Oracle database server will exempt the
snapshots assigned to a specific baseline from the automated purge
routine. Thus, the main purpose of a baseline is to preserve typical
runtime statistics in the AWR repository, allowing you to run the AWR
snapshot reports on the preserved baseline snapshots at any time and
compare them to recent snapshots contained in the AWR. This allows you
to compare current performance (and configuration) to established
baseline performance, which can assist in determining database
performance problems.
Creating baselines
You can use the create_baseline procedure contained in the
dbms_workload_repository stored PL/SQL package to create a baseline as
seen in this example:
EXEC
dbms_workload_repository.create_baseline (start_snap_id=>1109,
end_snap_id=>1111, baseline_name=>’EOM Baseline’);
Baselines can be seen using the DBA_HIST_BASELINE view as seen in the
following example:
SELECT baseline_id,
baseline_name, start_snap_id, end_snap_id
FROM dba_hist_baseline;
BASELINE_ID
BASELINE_NAME START_SNAP_ID END_SNAP_ID
----------- ---------------
------------- -----------
1 EOM
Baseline
1109 1111
In this case, the column BASELINE_ID identifies each individual
baseline that has been defined. The name assigned to the baseline is
listed, as are the beginning and ending snapshot IDs.
Removing baselines
You can remove a baseline using the
dbms_workload_repository.drop_baseline procedure as seen in this
example that drops the “EOM Baseline” that we just created.
EXEC
dbms_workload_repository.drop_baseline (baseline_name=>’EOM
Baseline’, Cascade=>FALSE);
Note that the cascade parameter will cause all associated snapshots to
be removed if it is set to TRUE; otherwise, the snapshots will be
cleaned up automatically by the AWR automated processes.
Automatic Database Diagnostic Monitor (ADDM)
The ADDM analyzes the information
contained in the Automatic Workload Repository (AWR) every 30 minutes
to
pinpoint problems and provide automated recommendations to DBAs. If
ADDM requires additional information to make a decision, it will
activate other advisories to gather more information. ADDM’s output
includes a plethora of reports, charts, graphs, heartbeats and related
visual aids. For example, ADDM identifies the most resource intensive
SQL statements and passes that statement to the SQL tuning advisor. It
promises that you can forget all of your scripts that link the many
v$views. ADDM can be run from Enterprise Manager or through a PL/SQL
interface. If a recommendation is made it reports the benefits that can
be expected, again in terms of time. The ADDM then triggers automatic
reconfiguration using the Automatic Storage Management (ASM) and
Automatic Memory Management (AMM) components. ADDM automatically
detects and diagnoses common performance problems, including:
* Hardware issues related to excessive I/O
* CPU bottlenecks
* Connection management issues
* Excessive parsing
* Concurrency issues, such as contention for locks
* PGA, buffer-cache, and log-buffer-sizing issues
* Issues specific to Oracle Real Application
Clusters (RAC) deployments, such as global cache hot blocks and objects
and interconnect latency issues
Because ADDM runs automatically after each new AWR snapshot is taken,
no manual steps are required to generate its findings. But you can run
ADDM on demand by creating a new snapshot manually, by using either
Oracle Enterprise Manager (OEM) or the command-line interface. The
following shows creation of a snapshot from the command line:
exec
dbms_workload_repository.create_snapshot();
or
exec
dbms_workload_repository.create_snapshot('TYPICAL');
You can also generate an ADDM report that summarizes performance data
and provides a list of all findings and recommendations
You can access ADDM reports through the Web-based OEM console or from a
SQL*Plus command line by using the new DBMS_ADVISOR built-in package.
For example, here's how to use the command line to create an ADDM
report quickly (based on the most recent snapshot):
spool ADDMsuggestions.txt
set long 1000000
set pagesize 50000
column get_clob format a80
select
dbms_advisor.get_task_report(task_name, 'TEXT', 'ALL') as
ADDM_report
from
dba_advisor_tasks
where task_id =
(select max(t.task_id)
from dba_advisor_tasks t, dba_advisor_log l
where t.task_id =
l.task_id
and
t.advisor_name='ADDM'
and
l.status= 'COMPLETED');
spool off
The ALL parameter generates additional information about the meaning of
some of the elements in the report.
The easiest way to get the ADDM report is by executing:
@?/rdbms/admin/addmrpt
Running this script will show which snapshots have been
generated, asks for the snapshot IDs to be used for generating the
report, and will generate the report containing the ADDM findings.
When you do not want to use the script, you need to submit and
execute the ADDM task manually. First, query DBA_HIST_SNAPSHOT to see
which snapshots have been created. These snapshots will be used by ADDM
to generate recommendations:
SELECT * FROM
dba_hist_snapshot ORDER BY snap_id;
Mark the 2 snapshot IDs (such as the lowest and highest ones) for use
in generating recommendations.
Next, you need to submit and execute the ADDM task manually, using a
script similar to:
DECLARE
task_name VARCHAR2(30) :=
'SCOTT_ADDM';
task_desc VARCHAR2(30) := 'ADDM
Feature Test';
task_id NUMBER;
BEGIN
dbms_advisor.create_task('ADDM', task_id, task_name,
task_desc,null); -- (1)
dbms_advisor.set_task_parameter('SCOTT_ADDM', 'START_SNAPSHOT',
1); -- (2)
dbms_advisor.set_task_parameter('SCOTT_ADDM', 'END_SNAPSHOT', 3);
dbms_advisor.set_task_parameter('SCOTT_ADDM', 'INSTANCE', 1);
dbms_advisor.set_task_parameter('SCOTT_ADDM', 'DB_ID', 494687018);
dbms_advisor.execute_task('SCOTT_ADDM');
-- (3)
END;
/
Here is an explanation of the steps you need to take to successfully
execute an ADDM job:
1) The first step is to create the task. For this, you need to specify
the name under which the task will be known in the ADDM task system.
Along with the name you can provide a more readable description on what
the job should do. The task type must be 'ADDM' in order to have it
executed in the ADDM environment.
2) After having defined the ADDM task, you must define the boundaries
within which the task needs to be executed. For this you need to set
the starting and ending snapshot IDs, instance ID (especially necessary
when running in a RAC environment), and database ID for the newly
created job.
3) Finally, the task must be executed.
When querying DBA_ADVISOR_TASKS you will see the just created job:
SELECT * FROM
dba_advisor_tasks;
When the job has successfully completed, examine the recommendations
made by ADDM by calling the DBMS_ADVISOR.GET_TASK_REPORT() routine,
like in:
SET LONG 1000000
PAGESIZE 0 LONGCHUNKSIZE 1000
COLUMN
get_clob FORMAT a80
SELECT
dbms_advisor.get_task_report('SCOTT_ADDM', 'TEXT', 'TYPICAL')
FROM sys.dual;
The recommendations supplied should be sufficient to investigate the
performance issue
To see the ADDM recommendations and the AWR repository data, use the
new Enterprise Manager 10g console on the page named DB Home. To see
the AWR reports, you can navigate to them from Administration, then
Workload Repository, and then Snapshots. We'll examine ADDM in greater
detail in a future installment.
Script to display the most recent ADDM report
set long 1000000
set pagesize 50000
column get_clob format a80
select
dbms_advisor.get_task_report(task_name) as ADDM_report
from dba_advisor_tasks
where task_id = (
select max(t.task_id)
from
dba_advisor_tasks t, dba_advisor_log l
where
t.task_id = l.task_id
and t.advisor_name = 'ADDM'
and l.status = 'COMPLETED');
SQL
Tuning Advisor (STA) and SQL Access Advisor
Oracle’s
latest advisor will help Oracle DBAs with the “fine art” of
SQL tuning. In the past DBA's required extensive tuning experience
before they could be described as “expert SQL tuners.” Oracle claims to
have embedded hundreds of year’s worth of tuning experience into the
SQL Tuning Advisor.
The SQL
Tuning Advisor uses the AWR to capture and
identify high resource consuming SQL statements. An intelligent
analyzer is then used to assist administrators in tuning the offending
SQL statements.
The
tuning advisor sends the SQL statement being analyzed to the Automatic
Tuning Optimizer to perform the following in-depth analysis:
-
Statistics
Analysis – the
utility checks for stale or missing statistics, which may have a
detrimental effect on the query’s optimization.
-
SQL Profiling –
reviews
past executions of the SQL statement to provide further information for
recommendations.
-
Access Path
Analysis –
determines if additional objects (indexes, materialized views) can be
created to improve the statement’s performance.
-
SQL Structure
Analysis –
reviews the SQL statement’s coding structure to determine if it can be
altered to increase performance.
The
Automatic Tuning Advisor uses the Oracle optimizer to make its
recommendations. Unlike run-time optimization, which focuses on quick
optimization, Automatic Tuning Advisor calls to the optimizer are not
limited by time constraints. As a result, queries tuned by the advisor
have a much better chance of having a finely tuned optimization plan
created.
The SQL
Tuning Advisor will be very beneficial to administrators who support
third-party applications. The SQL
Tuning Advisor uses the CBO to rewrite the
poorly performing SQL and create a SQL profile, which is stored in the
data dictionary. Each time the poorly performing SQL statement
executes, the rewritten statement stored in the data dictionary is used
in its place. No vendor assistance required!
The input workload for the SQL Access Advisor can consist of SQL
statements currently in the SQL Cache, a user defined set of SQL
statements contained in a workload table or an OEM generated SQL Tuning
Set. The SQL Access Advisor is also able to generate a hypothetical
workload for a specified schema. The utility can be invoked from the
Advisor Central home page or from the DBMS_ADVISOR package.
As you might expect, this "thinking" consumes resources such as CPU;
hence the SQL Tuning Advisor works on SQL statements during a Tuning
Mode, which can be run during off-peak times. This mode is indicated by
setting the SCOPE and TIME parameters in the
function while creating the tuning task. It's a good practice to run
Tuning Mode during a low-activity period in the database so that
regular users are relatively unaffected, leaving analysis for later.
1-Basic-Level
Tuning
The concept is best explained through an example. Take the case of the
query that the developer brought to your attention, shown below.
select account_no from accounts where old_account_no = 11
This statement is not difficult to tune but for
the sake of easier illustration, assume it is. There are two ways to
fire up the advisor: using Enterprise Manager or plain command line.
First, let's see how to use it in command line.
We invoke the advisor by calling the supplied package dbms_sqltune.
declare
l_task_id varchar2(20);
l_sql varchar2(2000);
begin
l_sql := 'select account_no from accounts where old_account_no = 11';
dbms_sqltune.drop_tuning_task ('FOLIO_COUNT');
l_task_id := dbms_sqltune.create_tuning_task (
sql_text => l_sql,
user_name => 'ARUP',
scope => 'COMPREHENSIVE',
time_limit => 120,
task_name => 'FOLIO_COUNT'
);
dbms_sqltune.execute_tuning_task ('FOLIO_COUNT');
end;
/
This package creates and executes a tuning task
named FOLIO_COUNT. Next, you will need to see the results of
the execution of the task (that is, see the recommendations).
set serveroutput on size 999999
set long 999999
spool recommendations.txt
select dbms_sqltune.report_tuning_task ('FOLIO_COUNT') from dual;
spool off;
Look at the output recommendations carefully;
the advisor says you can improve performance by creating an index on
the column OLD_ACCOUNT_NO. Even better, the advisor calculated the cost
of the query if the index were created, making the potential savings
more definable and concrete.
Of course, considering the simplicity of this
example, you would have reached the conclusion via manual examination
as well. However, imagine how useful this tool would be for more
complex queries where a manual examination may not be possible or is
impractical.
2-Intermediate-Level
Tuning: Query Restructuring
Suppose the query is a little bit more complex:
select account_no from accounts a
where account_name = 'HARRY'
and sub_account_name not in
( select account_name from accounts
where account_no = a.old_account_no and status is not null);
The advisor recommends the following:
1- Restructure SQL finding (see plan 1 in explain plans section)
----------------------------------------------------------------
The optimizer could not unnest the subquery at line ID 1 of the execution
plan.
Recommendation
--------------
Consider replacing "NOT IN" with "NOT EXISTS" or ensure that columns used
on both sides of the "NOT IN" operator are declared "NOT NULL" by adding
either "NOT NULL" constraints or "IS NOT NULL" predicates.
Rationale
---------
A "FILTER" operation can be very expensive because it evaluates the
subquery for each row in the parent query. The subquery, when unnested can
drastically improve the execution time because the "FILTER" operation is
converted into a join. Be aware that "NOT IN" and "NOT EXISTS" might
produce different results for "NULL" values.
This time the advisor did not recommend any
structural changes such as indexes, but rather intelligently guessed
the right way to tune a query by replacing NOT IN with NOT
EXISTS. ecause the two constructs are similar but not identical,
the advisor gives the rationale for the change and leaves the decision
to the DBA or application developer to decide whether this
recommendation is valid for the environment.
3-Advanced Tuning: SQL Profiles
As you may know, the optimizer decides on a
query execution plan by examining the statistics present on the objects
referenced in the query and then calculating the least-cost method. If
a query involves more than one table, which is typical, the optimizer
calculates the least-cost option by examining the statistics of all the
referenced objects—but it does not know the relationship among them.
For example, assume that an account with
status DELINQUENT will have less than $1,000 as balance. A
query that joins the tables ACCOUNTS and BALANCES will report fewer
rows if the predicate has a clause filtering for DELINQUENT
only. The optimizer does not know this complex relationship—but the
advisor does; it "assembles" this relationship from the data and stores
it in the form of a SQL Profile. With access to the SQL Profile, the
optimizer not only knows the data distribution of tables, but also the
data correlations among them. This additional information allows the
optimizer to generate a superior execution plan, thereby resulting in a
well-tuned query.
SQL Profiles obviate the need for tuning SQL
statements by manually adding query hints to the code. Consequently,
the SQL Tuning Advisor makes it possible to tune packaged applications
without modifying code—a tremendous benefit. The main point here is that unlike objects
statistics, a SQL Profile is mapped to a query, not an object or
objects. Another query involving the same two tables—ACCOUNTS and
BALANCES—may have a different profile. Using this metadata information
on the query, Oracle can improve performance. If a profile can be created, it is done during the
SQL Tuning Advisor session, where the advisor generates the profile and
recommends that you "Accept" it. Unless a profile is accepted, it's not
tied to a statement. You can accept the profile at any time by issuing
a statement such as the following:
begin
dbms_sqltune.accept_sql_profile (
task_name => 'FOLIO_COUNT',
name => 'FOLIO_COUNT_PROFILE'
description => 'Folio Count Profile',
category => 'FOLIO_COUNT');
end;
This command ties the profile named FOLIO_COUNT_PROFILE
generated earlier by the advisor to the statement associated with the
tuning task named FOLIO_COUNT described in the earlier
example. (Note that although only the advisor, not the DBA, can create
a SQL Profile, only you can decide when to use it.)
You can see created SQL Profiles in the
dictionary view DBA_SQL_PROFILES. The column SQL_TEXT shows
the SQL statement the profile was assigned to; the column STATUS
indicates if the profile is enabled. (Even if it is already tied to a
statement, the profile must be enabled in order to affect the execution
plan.)
Now, let's say that you want to know how
much of those recommendations have been done. If you are using the
command-line version of the SQL Access Advisor, not Oracle Enterprise
Manager, can you still see how much is done? Using the new view
V$ADVISOR_PROGRESS.
desc v$advisor_progress
Name
Null? Type
-----------------------------------------
-------- -----------
SID
NUMBER
SERIAL#
NUMBER
USERNAME
VARCHAR2(30)
OPNAME
VARCHAR2(64)
ADVISOR_NAME
VARCHAR2(64)
TASK_ID
NUMBER
TARGET_DESC
VARCHAR2(32)
SOFAR
NUMBER
TOTALWORK
NUMBER
UNITS
VARCHAR2(32)
BENEFIT_SOFAR
NUMBER
BENEFIT_MAX
NUMBER
FINDINGS
NUMBER
RECOMMENDATIONS
NUMBER
TIME_REMAINING
NUMBER
START_TIME
DATE
LAST_UPDATE_TIME
DATE
ELAPSED_SECONDS
NUMBER
ADVISOR_METRIC1
NUMBER
METRIC1_DESC
VARCHAR2(64)
Here the columns TOTALWORK and SOFAR show how much work has been done
as well as the total work, similar to what you can see from
V$SESSION_LONGOPS view.
Automatic
Shared Memory Management (AMM)
The system global area (SGA) consists of memory components. A component
represents a pool of memory used to satisfy a particular class of
memory allocation requests. The most commonly configured memory
components include the database buffer cache, shared pool, large pool,
and java pool. Since we fix the values for these components at instance
start time, we are constrained to use them as they are during the
instance runtime (with some exceptions).
Often it happens that a certain component’s memory pool is never used
but the pool is not available for another component, which is in need
of extra memory. Under-sizing can lead to poor performance and
out-of-memory errors (ORA-4031), while over-sizing can waste memory.
With Oracle 10g, we can employ the Automatic Shared Memory
Management feature. This feature enables the Oracle database to
automatically determine the size of each of these memory components
within the limits of the total SGA size. This solves the allocation
issues that we normally face in a manual method.
This feature enables us to specify a total memory amount to be used for
all SGA components. The Oracle Database periodically redistributes
memory between the components above according to workload requirements.
Using the sga_target
initialization parameter configures Automatic
Shared Memory Management (AMM). If you specify a non-zero value for
sga_target, the following four
memory pools are automatically sized:
- Database Buffer cache (The Default pool) (db_cache_size)
- Shared pool (shared_pool_size)
- Large pool (large_pool_size)
- Java pool (java_pool_size)
If you set sga_target to 0, the Automatic Shared Memory Management is
disabled, that is the default value of sga_target, so the auto-tuned
SGA parameters behave as in previous
releases of the Oracle database.
If sga_target is 0, configuration of the following buffers still
remains manual and they
are now referred to as manually sized components:
- Log Buffer
- Other Buffer Caches (KEEP/RECYCLE,
other block sizes)
- Streams Pool (new in Oracle Database 10g)
- Fixed SGA and other internal allocations
When sga_target is
set, the total size of manual SGA parameters are subtracted from the
sga_target value, and the balance is given to the auto-tuned SGA
components. You must set statistic_level
to TYPICAL (default) or ALL to use
Automatic Shared Memory Management
sga_target is also a dynamic
parameter and can be changed through
Enterprise Manager or with the ALTER SYSTEM command. However, the
sga_target can be increased only up to the value of sga_max_size.
Figure 2.3 shows an example of SGA components.
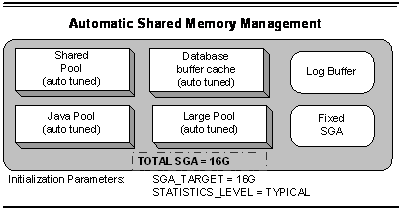
A new
background process named Memory Manager (MMAN) manages the automatic
shared memory. MMAN serves as the SGA Memory Broker and coordinates the
sizing of the memory components. The SGA Memory Broker keeps track of
the sizes of the components and pending resize operations.
Some pools in SGA are not subject to dynamic resizing, and must be
specified explicitly. Notable among them are the buffer pools for
nonstandard block sizes and the non-default ones for KEEP or RECYCLE.
If your database has a block size of 8K, and you want to configure 2K,
4K, 16K, and 32K block-size pools, you must set them manually. Their
sizes will remain constant; they will not shrink or expand based on
load. You should consider this factor when using multiple-size buffer,
KEEP, and RECYCLE pools. In addition, log buffer is not subject to the
memory adjustment—the value set in the parameter log_buffer is
constant, regardless of the workload.
If statistic_level
is set to TYPICAL (default) or ALL, statistics are collected
automatically. Oracle Database 10g has a predefined Scheduler job named
GATHER_STATS_JOB, which is activated with the appropriate value of the
STATISTIC_LEVEL parameter. The collection of statistics is fairly
resource-intensive, so you may want to ensure it doesn't affect regular
operation of the database. In 10g, you can do so automatically: a
special resource consumer group named AUTO_TASK_CONSUMER_GROUP is
available predefined for automatically executed tasks such as gathering
of statistics. This consumer group makes sure that the priority of
these stats collection jobs is below that of the default consumer
group, and hence that the risk of automatic tasks taking over the
machine is reduced or eliminated.
What if you want to set the parameter STATISTIC_LEVEL to TYPICAL but
don't want to make the statistics collection automatic? Simple. Just
disable the Scheduler job by issuing the following:
BEGIN
DBMS_SCHEDULER.DISABLE('GATHER_STATS_JOB');
END;
Go back to
Previous Statistics
One of the complications that can occur during
optimizer statistics collection is changed execution plans—that is, the
old optimization works fine until the statistics are collected, but
thereafter, the queries suddenly go awry due to bad plans generated by
the newly collected statistics. This is a not infrequent problem.
To protect against such mishaps, the statistics
collection saves the present statistics before gathering the new ones.
In the event of a problem, you can always go back to the old
statistics, or at least examine the differences between them to get a
handle on the problem. For example,
let's imagine that at 10:00PM on May 31 the statistics collection job
on the table REVENUE is run, and that subsequently the queries perform
badly. The old statistics are saved by Oracle, which you can retrieve
by issuing:
begin
dbms_stats.restore_table_stats (
'ARUP',
'REVENUE',
'31-MAY-04 10.00.00.000000000 PM -04:00');
end;
This command restores the statistics as of
10:00PM of May 31, given in the TIMESTAMP datatype. You just
immediately undid the changes made by the new statistics gathering
program. The length of the period that
you can restore is determined by the retention parameter. To check the
current retention, use the query:
SQL> select DBMS_STATS.GET_STATS_HISTORY_RETENTION from dual;
GET_STATS_HISTORY_RETENTION
---------------------------
31
which in this case shows that 31 days worth of
statistics can be saved but not guaranteed. To discover the exact time
and date to which the statistics extend, simply use the query:
SQL> select DBMS_STATS.GET_STATS_HISTORY_AVAILABILITY from dual;
GET_STATS_HISTORY_AVAILABILITY
---------------------------------------------------------------------
17-MAY-04 03.21.33.594053000 PM -04:00
which reveals that the oldest available statistics date to 3:21AM on
May 17. You can set the retention period to a
different value by executing a built-in function. For example, to set
it to 45 days, issue:
execute DBMS_STATS.ALTER_STATS_HISTORY_RETENTION (45)
trcsess utility (trace utility)
When solving tuning problems, session traces are very useful and offer
vital information. Traces are simple and straightforward for dedicated
server sessions, but for shared server sessions, many processes are
involved. The trace pertaining to the user session is scattered across
different trace files belonging to different processes. This makes it
difficult to get a complete picture of the life cycle of a session.
Now there is a new tool or command line utility to help read the trace
files. The trcsess command-line utility consolidates trace information
from selected trace files, based on specified criteria. The criteria
include session id, client id, service name, action name and module
name.
Also note that beginning with Oracle10g, Oracle Trace functionality is
no longer available. For tracing database activity, use SQLTrace or
TKPROF instead.
The syntax for the trcsess utility is:
trcsess [output=output_file_name]
[session=session_Id]
[clientid=client_Id]
[service=service_name]
[action=action_name]
[module=module_name]
[trace_files]
where:
- output specifies the file where the output is generated. When
this option is not specified, the standard output is used for the
output.
- session consolidates the trace information for the session
specified. The session Id is a combination of session index and session
serial number.
- clientid consolidates the trace information given client Id.
- service consolidates the trace information for the given service
name.
- action consolidates the trace information for the given action
name.
- module consolidates the trace information for the given module
name.
- trace_files is a list of all trace file names, separated by
spaces, in which trcsess will look for trace information. The wild card
character * can be used to specify the trace file names. If trace files
are not specified, all the files in the current directory are checked
by trcsess.
End-to-End
Tracing
End-to-End Tracing is a new feature in Oracle Database 10g that
facilitates the following tasks:
- Helps the debugging of performance problems in multi-tier
environments. In multi-tier environments, a request from an end client
is routed to different database sessions by the middle tier.
- Proper accounting of workload for applications using services.
Service Name, Module, and Action name provide a means to set apart
important transactions in an application.
End-to-End tracing becomes possible with the attribute client_identifier in v$session, which uniquely
identifies a given end client and is carried through all tiers to the
database server. Enabling tracing based on the client_identifier solves the
problem of debugging performance problems in multi-tier environments.
You can use the newly introduced dbms_monitor package to
control additional tracing and statistics gathering. This package
contains the following procedures used to enable and disable additional
statistics aggregation:
- client_id_stat_enable: Used to enable statistics accumulation for
a given client identifier
- client_id_stat_disable: Used to disable statistics accumulation
for a given client identifier
- serv_mod_act_stat_enable: Used to enable statistics accumulation
for a given hierarchy of service name, module name, and action name
- serv_mod_act_stat_disable: Used to disable statistics
accumulation for a given hierarchy of service name, module name, and
action name
Here is an example to enable and disable the tracing based on a
client_id:
EXECUTE
DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE ('client id');
EXECUTE
DBMS_MONITOR.CLIENT_ID_TRACE_DISABLE('client id');
Now, imagine that you have been using end-to-end tracing on several
sessions for some time but now you have no idea which sessions have
tracing turned on. How do you find out? All you have to do is to check
a view you check anyway, V$SESSION.
Three new columns now show the status of tracing:
- sql_trace—Shows (TRUE/FALSE) if SQL tracing has been enabled in
the session
- sql_trace_waits—If session tracing is enabled, you can have the
trace write wait information to the trace file; very useful in
diagnosing performance issues.
- sql_trace_binds—If the session uses bind variables, you can have
the trace write the bind variable values to the trace file. This column
shows TRUE/FALSE.
When tracing in the session is turned on, if you select these columns:
select sid, serial#, sql_trace,
sql_trace_waits, sql_trace_binds
from v$session
where username = 'HR'
The output is:
SID SERIAL# SQL_TRAC SQL_T SQL_T
---------- ---------- --------
----- -----
196 60946 ENABLED TRUE FALSE
Note that the view V$SESSION is populated only
if the procedure session_trace_enable in the package dbms_monitor is
used to enable tracing, not by alter session set sql_trace = true
or setting the event 10046. At some point later in time, if you want to
find out which sessions have been enabled for tracing, you can do so
using the above query
Wait Event Model improvements
Overview
of Wait Event Model
In a nutshell, the wait event interface provides insight into where
time is consumed. Wait events are collected by the server process or
thread to indicate the ‘wait’ before a process is completed. As we
know, at any given moment an Oracle process is either busy servicing a
request or waiting for something to happen. Oracle has defined a list
of every possible event that an Oracle process could wait for.
The Wait Event Interface now provides a powerful tool to monitor the
process delays. With its snapshot of the events and its detailed
analysis, it becomes possible for database administrators to pinpoint
areas that need tuning. Wait events show various symptoms of problems
that impact performance.
Wait Event
Enhancements
Oracle Database 10g introduces many new dynamic performance views and
updates other views. General improvements include:
- New columns in the v$session and v$session_wait views that track
the resources sessions are waiting for.
- A history of waits per session, enabling diagnosis of performance
problems for a desired time frame and period.
- Maintaining wait statistics of each SQL statement in the library
cache
- Histograms of wait durations, rather than a simple accumulated
average
The following list shows the existing views that are modified.
Changes to v$event_name
CLASS# and CLASS columns are added. These columns help to group related
events while analyzing the wait issues. For example, to list the events
related to IO, use the statement,
SELECT
name, class#, class FROM v$event_name
WHERE class# IN (10, 11);
In another example, to group all the events by class to get a quick
idea of the performance issues, use the statement,
SELECT
e.class#, sum(s.total_waits), sum(s.time_waited)
FROM v$event_name e, v$system_event s
WHERE e.name = s.event GROUP BY e.class#;
Changes to v$session
In the past, sessions experiencing waits were generally located by
joining the v$session_wait view with the v$session view. To simplify
the query, all the wait event columns from v$session_wait have been
added to v$session.
Use the statement below to determine the wait events that involve the
most sessions.
SELECT wait_class,
count(username)
FROM v$session GROUP BY wait_class;
New columns have been added to v$sessions as follows:
SQL_CHILD_NUMBER, PREV_CHILD_NUMBER, BLOCKING_SESSION_STATUS,
BLOCKING_SESSION, SEQ#, EVENT#, EVENT, WAIT_CLASS#, WAIT_CLASS,
WAIT_TIME, SECONDS_IN_WAIT, STATE and SERVICE_NAME
Changes to v$session_wait
The new columns include wait_class# and wait_class.
The following list shows the views that are new.
v$system_wait_class – This
view provides the instance-wide time totals for the number of waits and
the time spent in each class of wait events. This view also shows the
object number for which the session is waiting.
v$session_wait_class - This
view provides the number of waits and the time spent in each class of
wait event on a per session basis. This view also shows the object
number for which the session is waiting.
v$event_histogram – This view
displays a histogram of the number of waits, the maximum wait, and
total wait time on a per-child cursor basis. Using this view, you can
create a histogram showing the frequency of wait events for a range of
durations. This information assists you in determining whether a wait
event is a frequent problem that needs addressing or a unique event.
v$file_histogram – This view
displays a histogram of all single block reads on a per-file basis. To
provide more in-depth data, the v$file_histogram view shows the number
of I/O wait events over a range of values. You use the histogram to
determine if the bottleneck is a regular or a unique problem.
v$temp_histogram – This view
displays a histogram of all single block reads on a per-tempfile basis.
v$session_wait_history – This
view displays the last 10 wait events for each active session.
The new views above are quite helpful in understanding the overall
health of the database. For example, use the v$system_wait_class view
to display wait events occurring across the database.
SELECT wait_class#, wait_class, time_waited,
total_waits
FROM
v$system_wait_class
ORDER BY
time_waited;
WAIT_CLASS#
WAIT_CLASS TIME_WAITED TOTAL_WAITS
----------- ----------------
----------- -----------
5
Commit
10580 29404
2 Configuration
25140 1479
7
Network
28060 35111917
4
Concurrency
34707 16754
8 User
I/O
308052 178647
9 System
I/O
794444 2516453
1 Application
3781085 68100532
0
Other
38342194 22317
6
Idle
845197701 37411971
Automated Checkpoint Tuning
Check-pointing is an important Oracle activity which records the
highest system change number (SCN,) so that all data blocks less than
or equal to the SCN are known to be written out to the data files. If
there is a failure and then subsequent cache recovery, only the redo
records containing changes at SCN(s) higher than the checkpoint need to
be applied during recovery.
As we are aware, instance and crash recovery occur in two steps - cache
recovery followed by transaction recovery. During the cache recovery
phase, also known as the rolling forward stage, Oracle applies all
committed and uncommitted changes in the redo log files to the affected
data blocks. The work required for cache recovery processing is
proportional to the rate of change to the database and the time between
checkpoints.
Fast-start recovery can greatly reduce the mean time to recover (MTTR),
with minimal effects on online application performance. Oracle
continuously estimates the recovery time and automatically adjusts the
check-pointing rate to meet the target recovery time.
Oracle recommends using the FAST_START_MTTR_TARGET
initialization
parameter to control the duration of startup after instance failure.
With 10g, the database can now self-tune check-pointing to
achieve good recovery times with low impact on normal throughput. You
no longer have to set any checkpoint-related parameters. This method
reduces the time required for cache recovery and makes the
recovery bounded and predictable by limiting the number of dirty
buffers and the number of redo records generated between the most
recent redo record and the last checkpoint. Administrators specify a
target (bounded) time to complete the cache recovery phase of recovery
with the FAST_START_MTTR_TARGET
initialization parameter, and Oracle
automatically varies the incremental checkpoint writes to meet that
target.
The target_mttr field of v$instance_recovery contains the MTTR target
in effect. The estimated_mttr field of v$instance_recovery contains the
estimated MTTR should a crash happen right away.
For example,
SELECT
TARGET_MTTR, ESTIMATED_MTTR, CKPT_BLOCK_WRITES FROM V$INSTANCE_RECOVERY;
TARGET_MTTR ESTIMATED_MTTR
CKPT_BLOCK_WRITES
----------- --------------
-----------------
37
22
209187
Whenever you set FAST_START_MTTR_TARGET to a nonzero value, and while
MTTR advisory is ON, Oracle Corporation recommends that you disable
(set to 0) the following parameters:
LOG_CHECKPOINT_TIMEOUT
LOG_CHECKPOINT_INTERVAL
FAST_START_IO_TARGET
Because these initialization parameters either override
fast_start_mttr_target or potentially drive checkpoints more
aggressively than fast_start_mttr_target does, they can interfere with
the simulation.
WEB Admin for Database
Now start the Oracle EM dbconsole Build Script ($ORACLE_HOME/bin/emca
for Linux and $ORACLE_HOME\Bin\emca.bat for Windows).
emca
STARTED EMCA at Fri May 14
10:43:22 MEST 2004
Enter the following information
about the database to be configured.
Listener port number: 1521
Database SID: AKI1
Service name: AKI1.WORLD
Email address for notification:
martin.zahn@akadia.com
Email gateway for notification:
mailhost
Password for dbsnmp: xxxxxxx
Password for sysman: xxxxxxx
Password for sys: xxxxxxx
---------------------------------------------------------
You have specified the following
settings
Database ORACLE_HOME:
/opt/oracle/product/10.1.0
Enterprise Manager ORACLE_HOME:
/opt/oracle/product/10.1.0
Database host name ..........:
akira
Listener port number .........:
1521
Database SID .................:
AKI1
Service name .................:
AKI1
Email address for notification:
martin.zahn@akadia.com
Email gateway for notification:
mailhost
---------------------------------------------------------
Do you wish to continue?
[yes/no]: yes
AM oracle.sysman.emcp.EMConfig
updateReposVars
INFO: Updating file
../config/repository.variables ...
Now wait about 10 Minutes to complete!
Try to connect to the database Control:
http://server_name:5500/em
For Oracle
Enterprise Manager
http://server_name:5560/isqlplus
For iSQL*Plus
http://server_name:5620/ultrasearch For
Ultrasearch
If you have problems to connect, check the local configuration file
located on:
$ORACLE_HOME/<hostname>_<service_name>/sysman/config/emoms.properties
Automatically start and stop the DB-Console
$ emctl start dbconsole
$ emctl stop dbconsole
$ emctl status dbconsole
Using Jave Console from an
Oracle Client Machine
On 10g you still have the OEM as a console. Go to the Oracle binary
directory and type the following:
oemapp console
This will NOT use the Repository.
Shrink Tables (Segment Advisor)
Online segment shrink is available for tables in ASSM (Automatic
Segment Space Management) tablespaces. Conceptually, what happens is
that Oracle reads the table from the bottom up, and upon finding rows
at the bottom of the table, it deletes them and reinserts them at the
top of the table. When it runs out of space at the top, it stops,
leaving all the free space at the end—or bottom—of the table. Then
Oracle redraws the high-water mark for that table and releases that
allocated space. Here is a quick example:
create table ttt ENABLE ROW
MOVEMENT
as select * from
all_objects;
Here I created a table with ENABLE ROW MOVEMENT. Oracle will be
physically moving the rows, and this clause gives Oracle permission to
change the rowids. Here's what a full scan of this big table does:
set autotrace on statistics
select count(*) from t;
COUNT(*)
-----------
47266
Statistics
-------------------------------
0 db block gets
724 consistent gets
651 physical reads
set autotrace off
It took 724 logical IOs (consistent gets) to read that table and count
the rows. A peek at USER_EXTENTS shows the table consuming 768 blocks
in 20 extents. Over time, I perform some deletes on this table, leaving
behind lots of white space. I'll simulate that by deleting every other
row in the table:
delete from t
where mod(object_id,2) = 0;
23624 rows deleted.
You can also run the following to check how many blocks this table is
using:
select blocks from user_segments
where segment_name = 'T';
BLOCKS
----------
8
Now I want to reclaim this white space, getting it back from the
table
and perhaps using it for other objects, or maybe I full-scan this table
frequently and would just like it to be smaller. Before Oracle Database
10g, the only option was to rebuild it, with EMP/IMP, ALTER TABLE MOVE,
or an online redefinition. With10g, I can compact and
shrink it:
alter table t shrink space
compact;
alter table t shrink space;
In addition the CASCADE option can be used to propagete the shrink
operation to all dependan objects.
Another peek at USER_EXTENTS shows that the table now consumes 320
blocks in 17 extents. The table has actually shrunk while still online
and without a rebuild. REMEMBER
that this option will modify the ROWID's. It is now half its
original size in blocks,
because it released extents back to the system—something that was never
possible before. Further, look what this shrinking does for a full
scan:
select count(*) from t;
COUNT(*)
-----------
23642
Statistics
-------------------------------
0 db block gets
409 consistent gets
62 physical reads
The number of IOs required to perform that operation is now in line
with the actual size of the data.
To check the number of blocks we use again:
select blocks from user_segments where segment_name = 'T';
BLOCKS
----------
2
Finding Candidates for
Shrinking
Before performing an online shrink, you may want to find out the
biggest bang-for-the-buck by identifying the segments that can be most
fully compressed. Simply use the built-in function
verify_shrink_candidate in the package dbms_space. Execute this PL/SQL
code to test if the segment can be shrunk to 1,300,000 bytes:
begin
if
(dbms_space.verify_shrink_candidate ('ARUP','BOOKINGS','TABLE',1300000)
) then
:x := 'T';
else
:x := 'F';
end if;
end;
/
print x
X
--------------------------------
T
If you use a low number for the target shrinkage, say 3,000:
begin
if
(dbms_space.verify_shrink_candidate ('ARUP','BOOKINGS','TABLE',3000) )
then
:x := 'T';
else
:x := 'F';
end if;
end;
/
print x
The value of the variable x is set to 'F', meaning the table
cannot be shrunk to 3,000 bytes.
Oracle10G's Segment Advisor
Administrators are able to use Oracle10G's
Segment Advisor to identify candidates for shrink
operations. The advisor estimates the amount of unused space that
will be released when the shrink operation is run on the particular
object. A wizard is available that allows users to evaluate all
objects in the database, all objects in a specific tablespace or all
objects owned by a particular schema.
The 10G R2 Segment Advisor has been enhanced to identify tables that
suffer from excessive row chaining and row migrations.
Why should we care about row chaining and row migrations? When a row is
updated and becomes too large to fit into its original block (due to
insufficient free space), the row is moved to a new block and a pointer
is placed in the original block that identifies the row's new home.
This is called a row migration. So when you access the row through an
index, Oracle navigates first to the row's original block and then
follows the pointer to the block where the row is actually stored. This
means you are generating unnecessary I/O to access a migrated row. You
correct this by identifying the tables affected and reorganizing them.
A row chain occurs when a row is simply too long to fit into a single
block. Oracle will chain the row together on multiple blocks using
pointers to connect the chain's pieces. You solve this problem by
increasing the block size or decreasing the row's length. Most often
you just have to live with row chaining.
In the past, we identified row chaining and row migrations by reviewing
the "table fetch by continued row" output line in our STATSPACK reports
and ran SQL ANALYZE statements on the data objects on a regular basis.
Remember DBMS_STATS does not populate the CHAIN_CNT column in
DBA_TABLES. If you want to populate that column, you'll need to run the
ANALYZE statement.
In 10G R2, the Segment Advisor is automatically scheduled by Enterprise
Manager to run during a predefined maintenance window. The maintenance
window is initially defined as follows:
* Monday through Friday - 10PM to 6AM
* Saturday 12:00 a.m. to Monday morning at 12:00 a.m
The maintenance window's default times can be changed to tailor it to
an individual application's availability requirements. The Automatic
Segment Advisor doesn't analyze all of the data objects in the
database. It intelligently selects them by identifying segments that
are the most active, have the highest growth rate or exceed a critical
or warning space threshold.
In Oracle Database 10g Release 2, the supplied package DBMS_SPACE
provides the capability to tell you which segments have plenty of free
space under the high-water mark and would benefit from a
reorganization. The built-in function ASA_RECOMMENDATIONS shows the
segments; as this is a pipelined function, you will have to use it as
follows:
select * from
table (dbms_space.asa_recommendations());
TABLESPACE_NAME
: USERS
SEGMENT_OWNER
: ARUP
SEGMENT_NAME
: ACCOUNTS
SEGMENT_TYPE
: TABLE PARTITION
PARTITION_NAME
: P7
ALLOCATED_SPACE
: 0
USED_SPACE
: 0
RECLAIMABLE_SPACE
: 0
CHAIN_ROWEXCESS
: 17
RECOMMENDATIONS
: The object has chained rows that can be removed by re-org.
C1
:
C2
:
C3
:
TASK_ID
: 261
MESG_ID
: 0
Here you'll see that partition P7 of the table ACCOUNTS of the schema
ARUP has chained rows. Doing a reorganization will help speed up full
table scans in this partition. This information is collected by an
automatically scheduled job that runs in the predefined maintenance
window (between 10PM and 6AM on weekdays and between 12 a.m. Saturday
and 12 a.m. Monday); you can change those windows using Oracle
Enterprise Manager. During this time, the job scans the segments for
candidates. If the scan cannot be completed in time, the job is
suspended and resumed in the next day's window.
The job stores the information about the segments and tablespaces
inspected in a table named wri$_segadv_objlist. You can see the
information on the segments inspected in the view DBA_AUTO_SEGADV_CTL.
MERGE Statement Enhancements
The following examples use the table defined below.
CREATE TABLE test1 AS
SELECT *
FROM all_objects
WHERE 1=2;
Optional Clauses
The MATCHED and NOT MATCHED clauses are now
optional making all of the following examples valid.
-- Both clauses present.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET a.status = b.status
WHEN NOT MATCHED THEN
INSERT (object_id, status)
VALUES (b.object_id, b.status);
-- No matched clause, insert only.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN NOT MATCHED THEN
INSERT (object_id, status)
VALUES (b.object_id, b.status);
-- No not-matched clause, update only.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET a.status = b.status;
Conditional
Operations
Conditional inserts and updates are now possible by using a WHERE
clause on these statements.
-- Both clauses present.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET a.status = b.status
WHERE b.status != 'VALID'
WHEN NOT MATCHED THEN
INSERT (object_id, status)
VALUES (b.object_id, b.status)
WHERE b.status != 'VALID';
-- No matched clause, insert only.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN NOT MATCHED THEN
INSERT (object_id, status)
VALUES (b.object_id, b.status)
WHERE b.status != 'VALID';
-- No not-matched clause, update only.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET a.status = b.status
WHERE b.status != 'VALID';
DELETE
Clause
An optional DELETE WHERE clause can be used to clean up
after a merge operation. Only those rows which match both the ON
clause and the DELETE WHERE clause are deleted.
MERGE INTO test1 a
USING all_objects b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET a.status = b.status
WHERE b.status != 'VALID'
DELETE WHERE (b.status = 'VALID');
Quick Additions
- The SQL*PLUS copy command will be deprecated.
-- Bigfile tablespaces
This is a feature of Oracle 10g.
create bigfile tablespace beeeg_ts data file '/o1/dat/beeeg.dbf' size 2T
Bigfile tablespaces are supported only for locally managed tablespaces
with automatic segment-space management (which is the default setting
since Oracle 9i).
--spool in SQL*PLUS
Oracle 10g improves the spool command with
* spool create
* spool replace
* spool append
--Whitespace Support in Windows Path and File Names
Support for whitespaces in file names has been added to the START, @,
@@, RUN, SPOOL, SAVE and EDIT commands. Names containing whitespaces
must be quoted
for them to be recognised correctly:
SPOOL "My Report.txt"
@"My Report.sql"
--Glogin, Login and Predefined Variables
The user profile files, glogin.sql and login.sql are now run after each
successful connection in addition to SQL*Plus startup. This is
particularly useful
when the login.sql file is used to set the SQLPROMPT to the current
connection details:
- _DATE - Contains the current date (dynamic) by default or else a
fixed string
- _PRIVILEGE - Contains privilege level such as AS SYSDBA, AS
SYSOPER or blank.
- _USER - Contains the current username (like SHOW USER).
- _CONNECT_IDENTIFER contains the connection identifer used to
connect
so if my login.sql which reads :
SET FEED OFF
ALTER SESSION SET NLS_DATE_FORMAT='DD-MON-YYYY HH24:MI:SS';
SET FEED ON
SET SQLPROMPT "_USER'@'_CONNECT_IDENTIFIER _DATE> "
Gives me a sqlprompt of the form
<username> 08-APR-2004@<dbname> 13:55>
-- SHOW RECYCLEBIN
The SHOW RECYCLEBIN [original_table_name] option has been
added to display all the contents of the recycle bin, or just those for
a specified
table:
show recyclebin
ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME
---------------- ------------------------------ ------------ -------------------
BONUS BIN$F5d+By1uRvieQy5o0TVxJA==$0 TABLE 2004-03-23:11:03:38
DEPT BIN$Ie1ifZzHTV6bDhFraYImTA==$0 TABLE 2004-03-23:11:03:38
EMP BIN$Vu5i5jelR5yPGTP2M99vgQ==$0 TABLE 2004-03-23:11:03:38
SALGRADE BIN$L/27VyBRRP+ZGWnZylVbZg==$0 TABLE 2004-03-23:11:03:38
TEST1 BIN$0lObShnuS0+6VS1cvLny0A==$0 TABLE 2004-03-24:15:38:42
show recyclebin test1
ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME
---------------- ------------------------------ ------------ -------------------
TEST1 BIN$0lObShnuS0+6VS1cvLny0A==$0 TABLE 2004-03-24:15:38:42
This allows users to inspect the contents of the recycle bin before a PURGE
or FLASHBACK operation.
SELECT * FROM RECYCLEBIN;
Remove A Recycle Bin Object By Name: PURGE TABLE RB$$49684$TABLE$0;
Remove Recycle Bin Objects By Tablespace: PURGE TABLESPACE data_sml;
Remove Recycle Bin Objects By Tablespace And User: PURGE TABLESPACE
<tablespace_name> USER <schema_name>;
Empty The Recycle Bin: PURGE recyclebin;
Empty Everything In All Recycle Bins: PURGE dba_recyclebin;
-- OEM
Startup Process
apachectl start
apachectl stop
emctl start dbconsole
emctl stop dbconsole
emctl status dbconsole
Tried to access isqlplus using URL:
http://server:5560/isqlplus
Can successfully access:
http://server:5500
http://server:5500/em
Started the isqlplus process using command:
isqlplusctl start
isqlplusctl stop
Automatically Start / Stop the Database and Listener
su - root
cp dbora lsnrora /etc/init.d
rc-update add dbora default
rc-update add lsnrora default
PL/SQL
Enhancements in Oracle Database 10g
Performance
Tuning Enhancements in Oracle Database 10g
-- Server Generated Alerts
Server Generated Alerts (SGA) interfaces with the US to send e-mail
messages when an external problem is impeding Oracle performance.
External problems might include a UNIX mount point that is full,
causing a failure of ASM files to extend or a RAM shortage with the
System Global Area.
-- PL/SQL
DEVELOPMENTS
Oracle Database 10g PL/SQL has received considerable performance
enhancement work. This work applies to both interpreted and
natively
compiled PL/SQL. Oracle Database 10g also allows a degree of
optimization to the PL/SQL code also. This is set by the init.ora
or
session parameter plsql_optimizer_level=2.
--Easier and more Secure Encryption
Remember the package DBMS_OBFUSCATION_TOOLKIT (DOTK)? It was the only
available method to achieve encryption inside the database in Oracle9i
and below. While the package was sufficient for most databases, like
most security products, it was quickly rendered ineffective against
sophisticated hacker attacks involving highly sensitive information.
Notable among the missing functionality was support for Advanced
Encryption Standard (AES), a more powerful successor to the older
Digital Encryption Standard (DES) and Triple DES (DES3).
In 10g, a more sophisticated encryption apparatus, DBMS_CRYPTO, comes
to the rescue. This built-in package offers all the functionalities
lacking in DOTK, in addition to enhancing existing functions and
procedures. For example, DBMS_CRYPTO can encrypt in the new 256-bit AES
algorithm. The function ENCRYPT (which is also overloaded as a
procedure) accepts a few parameters:
| Parameter |
Description |
| SRC |
The input to be encrypted. It must be in RAW data type; any
other data type must be converted. For instance, the character variable
l_inp is converted by:
utl_i18n.string_to_raw (p_in_val, 'AL32UTF8');
Because the string must be converted to RAW and the character set
AL32UTF8, a new package called UTL_IL8N is used. Unlike DOTK,
DBMS_CRYPTO does not accept character variables as
parameters. Another point to note is that you do not have to pad the
character to make the length a multiple of 16, as it was in DOTK
package. The function (or procedure) pads it automatically.
|
| KEY |
The encryption key is specified here. The key must be of
appropriate length based on the algorithm used.
|
| TYP |
The type of encryption and padding used is specified in this
parameter. For example, if you want to use AES 256-bit algorithm,
Cipher Block Chaining, and PKCS#5 padding, you would use the built-in
constants here as:
typ => dbms_cryptio.encrypt_aes256 +
dbms_cryptio.chain_cbc +
dbms_cryptio.pad_pkcs5
|
The ENCRYPT function returns the
encrypted value in RAW, which can be converted into strings using
utl_i18n.raw_to_char (l_enc_val, 'AL32UTF8')
which is the reverse of the casting to RAW.
The opposite of encryption is decryption,
provided by the function (and overloaded as a procedure) DECRYPT,
which accepts analogous parameters. Using this new package, you can
build sophisticated security models inside your database applications.
Oracle File Copies
Oracle10G's DBMS_FILE_TRANSFER PL/SQL package provides
administrators with a mechanism to copy binary files between Oracle
databases without using OS commands or FTP. The transfer
package can be executed locally to transfer files to another database
server or can be executed remotely to transfer files between two remote
databases. Currently, the only files that can be copied using
this mechanism are Data Pump dump sets and tablespace data files.
In addition, the file size must be a multiple of 512 bytes and less
than 2 terabytes. Using the file transfer package in conjunction
with Oracle's transportable tablespace feature allows administrators to
totally automate tablespace data transfers from one database to
another. The process to unplug tablespace data files from
the source database, copy the files to the destination server and plug
the tablespace data files into the target database can now be executed
on a recurring basis by batch jobs initiated by DBMS_JOBS, OEM, KRON,
AT and third-party schedulers. The transferred files created on the
target platforms are owned by the Oracle account and can be accessed by
all database processes. For long copy operations, progress is displayed
in the V$SESSION_LONGOPS view
Redo Log File Size Advisor
Describing the process of determining the size of a database's redo
logfile as "somewhat error-prone" is like stating that the Titanic
sprung a small leak. Administrators must balance the performance
implications of redo logfiles that are too small with the recovery
implications of having redo logfiles that are too large.
Oracle10G comes to the rescue with another new advisor, the Redo
Logfile Size Advisor. The advisor suggests the smallest on-line
redo logfile based on the current FAST_START_MTTR_TARGET parameter and
workload statistics. Like database managed undo segments, Oracle
must have thought we were doing such a "bang up" job sizing redo
logfiles that they felt we needed help.
Initialization Parameters
In
previous release of Oracle, all parameters were considerd equally
important. This made the administration and tuning of the database very
difficult because database administrators need to become familiar with
over 200 parameters. Oracle 10g introduces two classes of
parameter: basic and advanced. In most cases, you need only set up the
basic parameters for an Oracle 10g instance.
These
basic parameters include:
- cluster_database
- compatible
- control_files
- db_block_size
- db_create_file_dest
- db_create_online_log_dest_n
- db_domain
- db_name
- db_recovery_file_dest
- db_recovery_file_dest_size
- instance_number
- job_queue_processes
- log_archive_dest_n
- log_archive_dest_state_n
- nls_language
- nls_territory
- open_cursors
- pga_aggregate_target
- processes
- remote_listener
- remote_login_passwordfile
- rollback_segments
- sessions
- sga_target
- shared_servers
- star_transformation_enabled
- undo_management
- undo_tablespace
The
following is an example of the parameter file generated by DBCR utility
(The basic parameters are in bold):
###########################################
# Archive
###########################################
log_archive_dest_1='LOCATION=/u03/arch/grid'
log_archive_format=%t_%s_%r.dbf
###########################################
# Cache and I/O
###########################################
db_block_size=8192
db_cache_size=25165824
db_file_multiblock_read_count=16
###########################################
# Cursors and Library Cache
###########################################
open_cursors=300
###########################################
# Database Identification
###########################################
db_domain=world
db_name=grid
###########################################
# Diagnostics and Statistics
###########################################
background_dump_dest=/u01/app/oracle/admin/grid/bdump
core_dump_dest=/u01/app/oracle/admin/grid/cdump
user_dump_dest==/u01/app/oracle/admin/grid/udump
timed_statistics=TRUE
###########################################
# File Configuration
###########################################
control_files=("/u02/ctl/grid/control01.ctl",
"/u02/ctl/grid/control02.ctl")
###########################################
# Job Queues
###########################################
job_queue_processes=10
###########################################
# Compatibility
###########################################
compatible=10.1.0.0.0
###########################################
# Optimizer
###########################################
query_rewrite_enabled=FALSE
star_transformation_enabled=FALSE
###########################################
# Pools
###########################################
java_pool_size=104857600
large_pool_size=8388608
shared_pool_size=104857600
###########################################
# Processes and Sessions
###########################################
processes=150
###########################################
# Redo Log and Recovery
###########################################
fast_start_mttr_target=300
###########################################
# Security and Auditing
###########################################
remote_login_passwordfile=EXCLUSIVE
###########################################
# Sort, Hash Joins, Bitmap Indexes
###########################################
pga_aggregate_target=25165824
sort_area_size=524288
###########################################
# System Managed Undo and Rollback Segments
###########################################
undo_management=AUTO
undo_retention=10800
undo_tablespace=UNDOTBS1
In
Oracle9i (9.2.0.3), there are 258 parameters in the v$parameter view.
In Oracle 10g (10.1.0.0), there are more than 250 parameters in
the v$parameter view. There are 233 parameters in both Oracle9i Release
2 and Oracle 10g Release 1.
Old
Parameters
Twenty-five
of the 258 parameters no longer exist in Oracle 10g’s
v$parameter view; these are:

New
Parameters
There
are twenty more new parameters in Oracle 10g Release 1:

V$SQLSTATS Performance View
Before we discuss the new V$SQLSTATS view, let's review some tuning
information. V$SQLAREA is one of the best SQL tuning views. I use the
two queries below to identify poorly performing SQL. I take the
traditional "top down" tuning approach and start tuning the highest
resource consuming SQL idenfified by the scripts below.
The following
query dentifies the SQL responsible for the most disk reads:
SELECT disk_reads, executions,
disk_reads/executions, hash_value, sql_text
FROM v$sqlarea
WHERE disk_reads > 5000
ORDER BY disk_reads;
The following
query dentifies the SQL responsible for the most buffer hits:
SELECT buffer_gets, executions,
buffer_gets/executions, hash_value, sql_text
FROM v$sqlarea
WHERE buffer_gets > 100000
ORDER BY buffer_gets;
You can create a
more readable report in SQLPLUS by inserting report breaks between the
output lines. To generate the report breaks in SQLPLUS, issue the
following statement before running the query:
BREAK ON
disk_reads SKIP 2 --- for the disk read report and
BREAK ON buffer_gets SKIP 2 --- for the buffer get report
It's common
knowledge that poorly performing SQL is responsible for the majority of
database performance problems. The first query returns SQL statements
responsible for generating disk reads greater than 5,000 while the
second query returns SQL statements responsible for generating buffer
reads greater than 100,000. These are good numbers to start with and
you can adjust them according to the size of the system you are tuning.
You'll notice that I divide the number of disk and buffer reads by the
number of statement executions. If a statement is generating 1,000,000
disk reads but is executed 500,000 times, it probably doesn't need
tuning. Heavy disk reads per statement execution usually means a lack
of proper indexing. Heavy buffer reads usually means the exact opposite
- indexes are being used when they shouldn't be.
But the SQLTEXT
column in V$SQLAREA does not provide the entire text of the SQL
statement. That's why I include the HASH_VALUE column in the report. I
can use that value to dump the entire SQL statement from V$SQLTEXT
using the statement below (where xxxxxxxx is the value in the
HASH_VALUE column from the V$SQLAREA reports above):
SELECT sql_text
FROM v$sqltext WHERE hash_value = 'xxxxxxxxx' ORDER BY piece;
Oracle 10G R2
provides a new view called V$SQLSTATS that contains a combination of
columns that appear in V$SQL and V$SQLAREA. The benefits that
V$SQLSTATS provides are as follows:
- Since
V$SQLSTATS contains the entire text of the SQL statement AND its
associated performance statistics, we are no longer required to access
both the V$SQLTEXT and V$SQLAREA to obtain the information we need.
- Oracle states
that V$SQLSTATS is faster and more scalable.
- The data in
V$SQLAREA has a tendency to get its contents flushed out just when you
need to get additional information from it. The V$SQLSTATS view
provides users with a longer access window.
FlashBack
Command
This feature has been greatly enhanced in Oracle Database 10g – going
from a simple flash back query facility – to a “whoops, I made a
mistake” recovery toolkit. In Oracle Database 10g, we can not
only query the database at a past point in time (which would allow us
to recovery accidentally deleted or modified information) – we can tell
the database to put the information back the way it was. Suppose
you “accidentally” deleted/modified the configuration information for
your application. Instead of performing a
recovery operation on this database (and having the end users screaming
while the application is offline), you can just ask the database to
“put the table back the way it was 5 minutes ago”. The FLASHBACK TABLE command uses the
underlying flashback query technology to put the table back the way it
was – providing no database integrity constraints would be violated. In
addition to being able to simply put a table back the way it was in
the past – the FLASHBACK TABLE command also allows you to undrop a
database table. Example:
drop table recycletest;
Let's check the status of the
table now.
SQL> select * from tab;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
BIN$04LhcpndanfgMAAAAAANPw==$0 TABLE
The table RECYCLETEST is gone but note the
presence of the new table BIN$04LhcpndanfgMAAAAAANPw==$0.
Here's what happened: The dropped table RECYCLETEST, instead of
completely disappearing, was renamed to a system-defined name. It stays
in the same tablespace, with the same structure as that of the original
table. If there are indexes or triggers defined on the table, they are
renamed too, using the same naming convention used by the table. Any
dependent sources such as procedures are invalidated; the triggers and
indexes of the original table are instead placed on the renamed table BIN$04LhcpndanfgMAAAAAANPw==$0,
preserving the complete object structure of the dropped table.
The table and its associated objects are
placed in a logical container known as the "recycle bin," which is
similar to the one in your PC. However, the objects are not moved from
the tablespace they were in earlier; they still occupy the space there.
The recycle bin is merely a logical structure that catalogs the dropped
objects. Use the following command from the SQL*Plus prompt to see its
content (you'll need SQL*Plus 10.1 to do this):
SQL> show recyclebin
ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME
---------------- ------------------------------ ------------ ------------------
RECYCLETEST BIN$04LhcpndanfgMAAAAAANPw==$0 TABLE 2004-02-16:21:13:31
This shows the original name of the table,
RECYCLETEST, as well as the new name in the recycle bin, which has the
same name as the new table we saw created after the drop. (Note: the
exact name may differ by platform.) To reinstate the table, all you
have to do is use the FLASHBACK TABLE command:
SQL> FLASHBACK TABLE RECYCLETEST TO BEFORE DROP;
FLASHBACK COMPLETE.
SQL> SELECT * FROM TAB;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
RECYCLETEST TABLE
Voila! The table is reinstated
effortlessly. If you check the recycle bin now, it will be empty.
Remember, placing tables in the recycle bin
does not free up space in the original tablespace. To free the space,
you need to purge the bin using:
PURGE RECYCLEBIN;
But what if you want to drop the table
completely, without needing a flashback feature? In that case, you can
drop it permanently using:
DROP TABLE RECYCLETEST PURGE;
This command will not rename the table to the
recycle bin name; rather, it will be deleted permanently, as it would
have been pre-10g.
Managing the Recycle Bin
If the tables are not really dropped in
this process--therefore not releasing the tablespace--what
happens when the dropped objects take up all of that space?
The answer is simple: that situation does not
even arise. When a tablespace is completely filled up with recycle bin
data such that the datafiles have to extend to make room for more data,
the tablespace is said to be under "space pressure." In that scenario,
objects are automatically purged from the recycle bin in a
first-in-first-out manner. The dependent objects (such as indexes) are
removed before a table is removed.
Similarly, space pressure can occur with user
quotas as defined for a particular tablespace. The tablespace may have
enough free space, but the user may be running out of his or her
allotted portion of it. In such situations, Oracle automatically purges
objects belonging to that user in that tablespace.
In addition, there are several ways you can
manually control the recycle bin. If you want to purge the specific
table named TEST from the recycle bin after its drop, you could issue
PURGE TABLE TEST;
or using its recycle bin name:
PURGE TABLE "BIN$04LhcpndanfgMAAAAAANPw==$0";
This command will remove table TEST and all
dependent objects such as indexes, constraints, and so on from the
recycle bin, saving some space. If, however, you want to permanently
drop an index from the recycle bin, you can do so using:
purge index in_test1_01;
which will remove the index only, leaving the
copy of the table in the recycle bin.
Sometimes it might be useful to purge at a
higher level. For instance, you may want to purge all the objects in
recycle bin in a tablespace USERS. You would issue:
PURGE TABLESPACE USERS;
You may want to purge only the recycle bin for a
particular user in that tablespace. This approach could come handy in
data warehouse-type environments where users create and drop many
transient tables. You could modify the command above to limit the purge
to a specific user only:
PURGE TABLESPACE USERS USER SCOTT;
A user such as SCOTT would clear his own recycle
bin with
PURGE RECYCLEBIN;
You as a DBA can purge all the objects in any
tablespace using
PURGE DBA_RECYCLEBIN;
As you can see, the recycle bin can be managed
in a variety of different ways to meet your specific needs.
There is also a new FLASHBACK DATABASE
command – this puts the entire database back the way it was in the
past. If you have ever been in the position of having to restore
an entire database and perform a point in time recovery to a point in
time right before some awful mistake was made (like dropping the right
user account – wrong database, or running the application that closes
out the books at the end of the year; for the second time!) you’ll
appreciate the FLASHBACK DATABASE capability. Instead of
restoring the entire last backup and replaying each and every
transaction that happened since (well, except for the one that got your
into this situation in the first place!) you can now tell the database
to go back 5 minutes in time (or more, or less).
More Information:
http://download-west.oracle.com/docs/cd/B14117_01/server.101/b10734/toc.htm
http://www.oracle.com/technology/obe/obe10gdb/ha/flashback/flashback.htm
-- Oracle By Example (OBE).
Case
Insensitive Searching
In Oracle Database 10g, Oracle provides case-insensitive and
accent-insensitive options for linguistic sorts.
The following example shows a GENERIC_BASELETTER query. First create a
table called test5:
CREATE TABLE test5(product
VARCHAR2(20));
INSERT INTO test5
VALUES('DATABASE');
INSERT INTO test5
VALUES('dätäbase');
INSERT INTO test5
VALUES('database');
INSERT INTO test5
VALUES('Database');
Set NLS_COMP to ANSI to perform a linguistic sort based on the value of
NLS_SORT:
ALTER SESSION SET NLS_COMP=ANSI;
Set NLS_SORT to GENERIC_BASELETTER:
ALTER SESSION SET
NLS_SORT=GENERIC_BASELETTER;
Again select database from test5:
SELECT * FROM test5 WHERE
product='database';
PRODUCT
--------------------
DATABASE
dätäbase
database
Database
Note that all of the rows of test5 are selected.
Query Changes to a Table
Thanks to the Flashback Versions Query feature, Oracle 10g can run a representation of changed data between two time
points task easily and efficiently.
Querying
Changes to a Table
In this example, I have used a bank's foreign currency management
application. The database has a table called RATES to record exchange
rate on specific times.
SQL> desc rates
Name Null? Type
----------------- -------- ------------
CURRENCY VARCHAR2(4)
RATE NUMBER(15,10)
This table shows the exchange rate of US$
against various other currencies as shown in the CURRENCY column. In
the financial services industry, exchange rates are not merely updated
when changed; rather, they are recorded in a history.
Up until now, the only option was to create a rate history table to
store the rate changes, and then query that table to see if a history
is available. Another option was to record the start and end times of
the applicability of the particular exchange rate in the RATES table
itself. When the change occurred, the END_TIME column in the existing
row was updated to SYSDATE and a new row was inserted with the new rate
with the END_TIME as NULL.
In Oracle Database 10g, however, the Flashback Versions Query feature
obviates the need to maintain a history table or store start and end
times. Rather, using this feature, you can get the value of a row as of
a specific time in the past with no additional setup.
For example, say that the DBA, in the course of normal business,
updates the rate several times—or even deletes a row and reinserts it:
insert into rates values
('EURO',1.1012);
commit;
update rates set rate = 1.1014;
commit;
update rates set rate = 1.1013;
commit;
delete rates;
commit;
insert into rates values
('EURO',1.1016);
commit;
update rates set rate = 1.1011;
commit;
After this set of activities, the DBA would get the current committed
value of RATE column by
SQL> select * from rates;
CURR
RATE
---- ----------
EURO
1.1011
This output shows the current value of the RATE, not all the changes
that have occurred since the first time the row was created. Thus using
Flashback Query, you can find out the value at a given point in time;
but we are more interested in building an audit trail of the
changes—somewhat like recording changes through a camcorder, not just
as a series of snapshots taken at a certain point.
The following query shows the changes made to the table:
select versions_starttime,
versions_endtime, versions_xid,
versions_operation, rate
from rates versions between
timestamp minvalue and maxvalue
order by VERSIONS_STARTTIME;
VERSIONS_STARTTIME
VERSIONS_ENDTIME
VERSIONS_XID
V RATE
----------------------
---------------------- ---------------- - ----------
01-DEC-03 03.57.12 PM
01-DEC-03 03.57.30 PM 0002002800000C61 I
1.1012
01-DEC-03 03.57.30 PM
01-DEC-03 03.57.39 PM 000A000A00000029 U
1.1014
01-DEC-03 03.57.39 PM
01-DEC-03 03.57.55 PM 000A000B00000029 U
1.1013
01-DEC-03 03.57.55
PM
000A000C00000029 D 1.1013
01-DEC-03 03.58.07 PM
01-DEC-03 03.58.17 PM 000A000D00000029 I
1.1016
01-DEC-03 03.58.17
PM
000A000E00000029 U 1.1011
Note that all the changes to the row are shown here, even when the row
was deleted and reinserted. The VERSION_OPERATION column shows what
operation (Insert/Update/Delete) was performed on the row. This was
done without any need of a history table or additional columns.
The column versions_xid shows the identifier of the transaction that
changed the row. More details about the transaction can be found from
the view FLASHBACK_TRANSACTION_QUERY, where the column XID shows the
transaction id. For instance, using the VERSIONS_XID value
000A000D00000029 from above, the UNDO_SQL value shows the actual
statement.
SELECT UNDO_SQL
FROM FLASHBACK_TRANSACTION_QUERY
WHERE XID = '000A000D00000029';
UNDO_SQL
----------------------------------------------------------------------------
insert into
"ANANDA"."RATES"("CURRENCY","RATE") values ('EURO','1.1013');
In addition to the actual statement, this view also shows the timestamp
and SCN of commit and the SCN and timestamp at the start of the query,
among other information.
Finding Out Changes During a
Period
Now, let's see how we can use the information effectively. Suppose we
want to find out the value of the RATE column at 3:57:54 PM. We can
issue:
select rate, versions_starttime, versions_endtime
from rates versions between timestamp
to_date('12/1/2003
15:57:54','mm/dd/yyyy hh24:mi:ss')
and to_date('12/1/2003
16:57:55','mm/dd/yyyy hh24:mi:ss');
RATE VERSIONS_STARTTIME VERSIONS_ENDTIME
---------- ----------------------
----------------------
1.1011
This query is similar to the flashback queries. In the above example,
the start and end times are null, indicating that the rate did not
change during the time period; rather, it includes a time period. You
could also use the SCN to find the value of a version in the past. The
SCN numbers can be obtained from the pseudo-columns VERSIONS_STARTSCN
and VERSIONS_ENDSCN. Here is an example:
select rate, versions_starttime, versions_endtime
from rates versions
between scn 1000 and 1001;
Using the keywords MINVALUE and MAXVALUE, all the changes that are
available from the undo segments is displayed. You can even give a
specific date or SCN value as one of the end points of the ranges and
the other as the literal MAXVALUE or MINVALUE. For instance, here is a
query that tells us the changes from 3:57:52 PM only; not the complete
range:
select versions_starttime, versions_endtime, versions_xid,
versions_operation, rate
from rates versions between
timestamp to_date('12/11/2003 15:57:52', 'mm/dd/yyyy hh24:mi:ss')
and maxvalue
order by VERSIONS_STARTTIME;
VERSIONS_STARTTIME
VERSIONS_ENDTIME
VERSIONS_XID
V RATE
----------------------
---------------------- ---------------- - ----------
01-DEC-03 03.57.55
PM
000A000C00000029 D 1.1013
01-DEC-03 03.58.07 PM
01-DEC-03 03.58.17 PM 000A000D00000029 I
1.1016
01-DEC-03 03.58.17
PM
000A000E00000029 U 1.1011
Estimate Table and Index Size
We are asked to create an index on the columns
booking_id and cust_name of the table BOOKINGS. How much space does the
proposed index need? All you do is execute the following PL/SQL script.
declare
l_used_bytes number;
l_alloc_bytes number;
begin
dbms_space.create_index_cost (
ddl => 'create index in_bookings_hist_01 on bookings_hist '||
'(booking_id, cust_name) tablespace users',
used_bytes => l_used_bytes,
alloc_bytes => l_alloc_bytes
);
dbms_output.put_line ('Used Bytes = '||l_used_bytes);
dbms_output.put_line ('Allocated Bytes = '||l_alloc_bytes);
end;
/
The output is:
Used Bytes = 7501128
Allocated Bytes = 12582912
You should be aware of two important caveats, however. First,
this process applies only to tablespaces with SEGMENT SPACE MANAGEMENT
AUTO turned on. Second, the package calculates the estimated size of
the index from the statistics on the table. Hence it's very important
to have relatively fresh statistics on the tables. But beware: the
absence of statistics on the table will not result in an error in the
use of the package, but will yield a wrong result.
Suppose there is a table named BOOKINGS_HIST, which has the average row
length of 30,000 rows and the PCTFREE parameter of 20. What if you
wanted to increase the parameter PCT_FREE to 3—by what amount will the
table increase in size? Because 30 is a 10% increase over 20, will the
size go up by 10%? Instead of asking your psychic, ask the procedure
CREATE_TABLE_COST inside the package DBMS_SPACE. Here is how you can
estimate the size:
declare
l_used_bytes number;
l_alloc_bytes number;
begin
dbms_space.create_table_cost (
tablespace_name => 'USERS',
avg_row_size => 30,
row_count => 30000,
pct_free => 20,
used_bytes => l_used_bytes,
alloc_bytes => l_alloc_bytes
);
dbms_output.put_line('Used: '||l_used_bytes);
dbms_output.put_line('Allocated: '||l_alloc_bytes);
end;
/
The output is:
Used: 1261568
Allocated: 2097152
Changing the table's PCT_FREE parameter to 30 from 20, by specifying
pct_free => 30
we get the output:
Used: 1441792
Allocated: 2097152
Note how the used space has increased from 1,261,568 to 1,441,792
because the PCT_FREE parameter conserves less room in the data block
for user data. The increase is about 14%, not 10%, as expected. Using
this package you can easily calculate the impact of parameters such as
PCT_FREE on the size of the table, or of moving the table to a
different tablespace.
Improvements to Bulk Binds and Collections
You can use collections to improve the performance of SQL operations
executed iteratively by using bulk binds. Bulk binds reduce the number
of context switches between the PL/SQL engine and the SQL engine. Two
PL/SQL language constructs implement bulk binds: FORALL and BULK
COLLECT INTO.
The syntax for the FORALL statement is:
FORALL bulk_index IN [lower_bound..upper_bound
| INDICES OF
collection_variable[BETWEEN lower_bound
AND upper_bound]
| VALUES OF
collection_variable ]
[SAVE EXCEPTIONS]
sql_statement;
Bulk_index can be used only in the sql_statement and only as a
collection index (subscript). When PL/SQL processes this statement, the
whole collection, instead of each individual collection element, is
sent to the database server for processing. To delete all the accounts
in the collection inactives from the table ledger, do this:
FORALL i IN
inactives.FIRST..inactives.LAST
DELETE FROM ledger
WHERE acct_no = inactives(i);
With Oracle10g, if there are non-consecutive index values due to
deletions, you will need to use the INDICES OF syntax to skip over the
deleted elements:
FORALL i IN INDICES OF inactives
DELETE FROM ledger
WHERE acct_no = inactives(i);
With Oracle10g, if you are interested in the values of a sparse
collection of integers instead of the indices, you will need to use the
VALUES OF syntax:
FORALL i IN VALUES OF
inactives_list
-- inactives_list is
a collection of index values from
-- the inactives
table which are earmarked for deletion
DELETE FROM ledger
WHERE acct_no = inactives(i);
These new INDICES OF and VALUES OF keywords allow you to specify a
subset of rows in a driving collection that will be used in the FORALL
statement. To match the row numbers in the data collection with the row
numbers in the driving collection, use the INDICES OF clause. To
match the row numbers in the data collection with the values found in
the defined rows of the driving collection, use the VALUES OF clause.
There are several functions that can be used to manipulate collections.
Most of these are new to Oracle10g; only
CAST and MULTISET are available in earlier releases. The COLLECT,
POWERMULTISET, and POWERMULTISET_BY_CARDINALITY are only valid in a SQL
statement; they cannot be used, for example, in a PLSQL assignment.
The CAST function works together with the COLLECT and MULTISET
functions. MULTISET was available prior to Oracle10g and operates on a
subquery.
COLLECT is new to Oracle10g and operates on a column in a SQL statement:
CREATE TYPE email_list_t AS TABLE
OF VARCHAR2(64);
-- COLLECT operates on a column
SELECT CAST(COLLECT(cust_email)AS
email_list_t)
FROM oe.customers;
-- which is equivalent to
SELECT CAST(MULTISET(SELECT
cust_email
FROM oe.customers)
AS email_list_t)
FROM dual;
Examples of the other nested table functions, operators, and
expressions are demonstrated as follows:
DECLARE
TYPE nested_type IS
TABLE OF NUMBER;
nt1 nested_type
:= nested_type(1,2,3);
nt2 nested_type
:= nested_type(3,2,1);
nt3 nested_type
:= nested_type(2,3,1,3);
nt4 nested_type
:= nested_type(1,2,4);
answer
nested_type;
BEGIN
answer := nt1
MULTISET UNION nt4; -- (1,2,3,1,2,4)
answer := nt1
MULTISET UNION nt3; -- (1,2,3,2,3,1,3)
answer := nt1
MULTISET UNION DISTINCT nt3; -- (1,2,3)
answer := nt2 MULTISET INTERSECT nt3;
-- (3,2,1)
answer := nt2 MULTISET INTERSECT
DISTINCT nt3;
-- (3,2,1)
answer := nt3 MULTISET EXCEPT nt2; --
(3)
answer := nt3 MULTISET EXCEPT DISTINCT
nt2; -- ()
answer := SET(nt3); -- (2,3,1)
IF (nt1 IS A SET) AND (nt3 IS NOT A
SET) THEN
dbms_output.put_line('nt1 has unique
elements');
dbms_output.put_line('but nt3 does
not');
END IF;
IF (nt3 MULTISET EXCEPT DISTINCT nt2)
IS EMPTY THEN
dbms_output.put_line('empty set');
END IF;
IF 3 MEMBER OF (nt3 MULTISET EXCEPT
nt2) THEN
dbms_output.put_line('3 is in the
answer set');
END IF;
IF nt1 SUBMULTISET nt3 THEN
dbms_output.put_line('nt1 is a subset
of nt3');
END IF;
IF SET(nt3) IN (nt1,nt2,nt3) THEN
dbms_output.put_line('expression is IN the list of nested
tables');
END IF;
END;
New
collection functions.
Function
|
Return
value
|
Description
|
=
|
BOOLEAN
|
Compares two nested tables and
return TRUE if they have the same named type, cardinality, and the
elements are equal.
|
<>
|
BOOLEAN |
Compares two nested tables and
return FALSE if they differ in named type, cardinality, or equality of
elements.
|
[NOT] IN ( )
|
BOOLEAN |
Returns TRUE [FALSE] if the
nested table to the left of IN exists in the list of nested tables in
the parentheses.
|
CARDINALITY(x)
|
NUMBER
|
Returns the number of elements
in varray or nested table x. Returns NULL if the collection is
atomically NULL (not initialized).
|
COLLECT (Oracle10g)
|
NESTED TABLE
|
Used in conjunction with CAST to
map a column to a collection.
|
MULTISET
|
NESTED TABLE |
Used in conjunction with CAST to
map a subquery to a collection.
|
x MULTISET EXCEPT [DISTINCT] y
|
NESTED TABLE |
Performs a MINUS set operation
on nested tables x and y, returning a nested table whose elements are
in x, but not in y. x, y, and the returned nested table must all be of
the same type. The DISTINCT keyword forces the elimination of
duplicates from the returned nested table.
|
x MULTISET INTERSECT [DISTINCT] y
|
NESTED TABLE |
Performs an INTERSECT set
operation on nested tables x and y, returning a nested table whose
elements are in both x and y. x, y, and the returned nested table must
all be of the same type. The DISTINCT keyword forces the elimination of
duplicates from the returned nested table.
|
x MULTISET UNION [DISTINCT] y
|
NESTED TABLE |
Performs a UNION set operation
on nested tables x and y, returning a nested table whose elements
include all those in x as well as those in y. x, y, and the returned
nested table must all be of the same type. The DISTINCT keyword forces
the elimination of duplicates from the returned nested table.
|
SET(x)
|
NESTED TABLE
|
Returns nested table x without
duplicate elements.
|
Compile Time Warnings
Optimizing Compiler available with Oracle10g
PL/SQL’s optimizing compiler can improve runtime performance
dramatically, imposing a relatively slight overhead at compile time.
Fortunately, the benefits of optimization apply both to interpreted and
natively compiled PL/SQL,
because optimizations are applied by analyzing patterns in source code.
The optimizing compiler is enabled by default. However, you may wish to
alter its behavior, either by lowering its aggressiveness or by
disabling it entirely.
For example, if, in the course of normal operations, your system must
perform recompilation of many lines of code, or if an application
generates many lines of dynamically executed PL/SQL, the overhead of
optimization may be unacceptable. Keep in mind, though, Oracle’s tests
show that the optimizer doubles the runtime performance of
computationally intensive PL/SQL.
This new feature examines code and makes internal adjustments to it,
depending on the level used and the type of code it sees.
Level 0 is to compile without optimization.
Level 1 is to compile with some optimization but tries to maximize
compile time.
Level 2 is the default and tries to improve code for the best runtime
performance.
Use the session level statements to control this new optimizing
compiler:
ALTER SESSION
SET PLSQL_OPTIMIZE_LEVEL = 1;
or simply compile with the setting using
ALTER
PROCEDURE myproc COMPILE PLSQL_OPTIMIZE_LEVEL = 1;
Oracle can now produce compile-time warnings when code is ambiguous or
inefficient be setting the PLSQL_WARNINGS parameter at either instance
or session level. The categories ALL, SEVERE, INFORMATIONAL and
PERFORMANCE can be used to alter the type of warnings that are
produced.
Severe: Messages for conditions
that might cause unexpected behavior or wrong results, such as aliasing
problems with parameters.
Performance: Messages for
conditions that might cause performance problems, such as passing a
VARCHAR2 value to a NUMBER column in an INSERT statement.
Informational: Messages for
conditions that do not have an effect on performance or correctness,
but that you might want to change to make the code more maintainable,
such as dead code that can never be executed.
The keyword All is a
shorthand way to refer to all warning messages.
Examples of their usage include:
-- Instance and session level.
ALTER SYSTEM SET PLSQL_WARNINGS='ENABLE:ALL';
ALTER SESSION SET PLSQL_WARNINGS='DISABLE:PERFORMANCE';
-- Recompile with extra checking.
ALTER PROCEDURE hello COMPILE PLSQL_WARNINGS='ENABLE:PERFORMANCE';
-- Set mutiple values.
ALTER SESSION SET
PLSQL_WARNINGS='ENABLE:SEVERE','DISABLE:PERFORMANCE','DISABLE:INFORMATIONAL';
-- Use the DBMS_WARNING package instead.
EXEC DBMS_WARNING.SET_WARNING_SETTING_STRING('ENABLE:ALL' ,'SESSION');
The current settings associated with each object can be displayed using
the [USER|DBA|ALL]_PLSQL_OBJECT_SETTINGS views.
ALTER SYSTEM SET PLSQL_WARNINGS='ENABLE:ALL'; --
For debugging during development.
ALTER SESSION SET PLSQL_WARNINGS='ENABLE:PERFORMANCE'; -- To focus on
one aspect.
ALTER PROCEDURE hello COMPILE PLSQL_WARNINGS='ENABLE:PERFORMANCE'; --
Recompile with extra checking.
ALTER SESSION SET PLSQL_WARNINGS='DISABLE:ALL'; -- To turn off all
warnings.
-- We want to hear about 'severe' warnings, don't want to hear about
'performance'
-- warnings, and want PLW-06002 warnings to produce errors that halt
compilation.
ALTER SESSION SET
PLSQL_WARNINGS='ENABLE:SEVERE','DISABLE:PERFORMANCE','ERROR:06002';
To see a typical example of the warning output try:
ALTER SESSION SET
PLSQL_WARNINGS='ENABLE:ALL';
CREATE OR REPLACE PROCEDURE
test_warnings AS
l_dummy VARCHAR2(10)
:= '1';
BEGIN
IF 1=1 THEN
SELECT '2' INTO l_dummy FROM dual;
ELSE
RAISE_APPLICATION_ERROR(-20000, 'l_dummy != 1!');
END IF;
END;
/
SP2-0804: Procedure created with compilation warnings
SHOW ERRORS
LINE/COL ERROR
-------- ---------------------------
9/5 PLW-06002: Unreachable code
The errors can be queried using the %_ERRORS views.
Another Example:
ALTER SESSION SET
PLSQL_WARNINGS=‘enable:severe', 'enable:performance‘
'enable:informational';
CREATE OR REPLACE PROCEDURE
my_proc(p_date_info IN OUT VARCHAR2) AS
v_return
BOOLEAN;
first_test TY_TEST;
second_test TY_TEST;
BEGIN
first_test :=
TY_TEST(test(1, SYSDATE));
second_test :=
TY_TEST(test(1, SYSDATE));
v_return
:= first_test = second_test;
p_date_info := 'The date
is '||SYSDATE;
IF v_return THEN
dbms_output.put_line('The two are the same.');
ELSE
dbms_output.put_line('The two are not the same.');
END IF;
END;
show err
Errors for PROCEDURE MY_PROC:�LINE/COL ERROR
-------- -----------------------------------------------------
2/2 PLW-07203: parameter 'P_DATE_INFO'
may benefit from use of the NOCOPY compiler hint
Single-Set Aggregates in
DML Returning Clause
This allows the use of single-set aggregation functions (like sum, avg,
etc) in the RETURNING clause of DML statements. This can result in
significant performance gains in transactions that process many rows of
the same table - such as in batch processes. The DML statements that
can use the single-set aggregates in their returning clauses are
INSERT, UPDATE, and DELETE.
The purpose of the RETURNING clause is to return the rows affected by
the INSERT, UPDATE, or DELETE statement. The RETURNING clause can only
be used with single tables and materialized views and regular views
based on a single table.
When the target of the INSERT is a single row, the RETURNING clause can
retrieve column expressions using the affected row, rowid, and REFs to
the affected row. Single-set aggregates can only be used when the
returning clause returns a single row. Single-set aggregates cannot be
combined with simple expressions in the same returning clause.
Single-set aggregates cannot contain the DISTINCT keyword.
An example INSERT using the RETURNING clause and a single-set aggregate
would be:
Set serveroutput on
Variable tot_sal;
begin
INSERT INTO emp select *
from emp
RETURNING sum(sal) INTO :tot_sal;
dbms_output.put_line('
Total Company Payroll now : ' || to_char(:tot_sal,'$999,999.00'));
end;
/
An example UPDATE using the RETURNING clause and a single-set aggregate
is shown below.
Variable tot_sal number;
begin
update emp set sal=sal*1.1
RETURNING
sum(sal) INTO :tot_sal;
dbms_output.put_line('Total Company Payroll now
'||to_char(:tot_sal,'$999,999.00'));
end;
/
An example DELETE using a subquery in the WHERE statement and the
RETURNING clause with a single-set aggregate would be:
variable tot_sal number;
begin
delete emp a where a.rowid
> (select min (x.rowid) from emp x
where x.empno=a.empno)
RETURNING sum(a.sal) INTO :tot_sal;
dbms_output.put_line('Total
Company Payroll now '||to_char(:tot_sal,'$999,999.00'));
end;
/
Online Redefinition
In highly available systems, it is occasionally necessary to redefine
large "hot" tables to improve the performance of queries or DML
performed against these tables. The database provide a mechanism to
redefine tables online. This mechanism provides a significant increase
in availability compared to traditional methods of redefining tables
that require tables to be taken offline.
When a table is redefined online, it is accessible to DML during much
of the redefinition process. The table is locked in the exclusive mode
only during a very small window which is independent of the size of the
table and the complexity of the redefinition. Online table redefinition
enables you to:
- Modify the storage parameters of the table
- Move the table to a different tablespace
in the same schema
- Add support for parallel queries
- Add or drop partitioning support
- Re-create the table to reduce fragmentation
- Change the organization of a normal table
(heap organized) to an index-organized table and vice versa
- Add or drop a column
Steps
for Online Redefinition of Tables
This example illustrates online redefinition of the previously created
table hr.admin_emp, which at this point only contains columns: empno,
ename, job, deptno. The table is redefined as follows:
* New columns mgr, hiredate, sal, and
bonus (these existed in the original table but were dropped in previous
examples) are added.
* The new column bonus is initialized to
0
* The column deptno has its value
increased by 10.
* The redefined table is partitioned by
range on empno.
1. Choose one of the following two methods of redefinition:
* The first method of redefinition is to use the
primary keys or pseudo-primary keys to perform the redefinition.
Pseudo-primary keys are unique keys with all component columns having
NOT NULL constraints. For this method, the versions of the tables
before and after redefinition should have the same primary key columns.
This is the preferred and default method of redefinition.
* The second method of redefinition is to use
rowids. For this method, the table to be redefined should not be an
index organized table. Also, in this method of redefinition, a hidden
column named M_ROW$$ is added to the post-redefined version of the
table and it is recommended that this column be marked as unused or
dropped after the redefinition is completed.
2. Verify that the table can be online redefined by invoking the
DBMS_REDEFINITION.CAN_REDEF_TABLE() procedure and use the OPTIONS_FLAG
parameter to specify the method of redefinition to be used. If the
table is not a candidate for online redefinition, then this procedure
raises an error indicating why the table cannot be online redefined.
BEGIN
DBMS_REDEFINITION.CAN_REDEF_TABLE('hr','admin_emp', dbms_redefinition.cons_use_pk);
END;
/
3. Create an empty interim table
(in the same schema as the table to be redefined) with all of the
desired attributes. If columns are to be dropped, do not include them
in the definition of the interim table. If a column is to be added,
then add the column definition to the interim table. It is possible to
perform table redefinition in parallel. If you specify a degree of
parallelism on both of the tables and you ensure that parallel
execution is enabled for the session, the database will use parallel
execution whenever possible to perform the redefinition. You can use
the PARALLEL clause of the ALTER SESSION statement to enable parallel
execution.
CREATE TABLE hr.int_admin_emp
(empno NUMBER(5) PRIMARY KEY,
ename VARCHAR2(15) NOT NULL,
job VARCHAR2(10),
mgr NUMBER(5),
hiredate DATE DEFAULT (sysdate),
sal NUMBER(7,2),
deptno NUMBER(3) NOT NULL,
bonus NUMBER (7,2) DEFAULT(1000))
PARTITION BY RANGE(empno)
(PARTITION emp1000 VALUES LESS THAN (1000) TABLESPACE admin_tbs,
PARTITION emp2000 VALUES LESS THAN (2000) TABLESPACE admin_tbs2);
4. Start the redefinition process by calling
DBMS_REDEFINITION.START_REDEF_TABLE(), providing the following:
* The table to be
redefined
* The interim table
name
* The column mapping
* The method of
redefinition
* Optionally, the
columns to be used in ordering rows
* Optionally, specify
the ORDER BY columns
If the column mapping information is not supplied, then it is assumed
that all the columns (with their names unchanged) are to be included in
the interim table. If the column mapping is supplied, then only those
columns specified explicitly in the column mapping are considered. If
the method of redefinition is not specified, then the default method of
redefinition using primary keys is assumed. You can optionally specify
the ORDERBY_COLS parameter to specify how rows should be ordered during
the initial instantiation of the interim table.
BEGIN
DBMS_REDEFINITION.START_REDEF_TABLE('hr',
'admin_emp','int_admin_emp',
'empno empno, ename ename, job job, deptno+10 deptno, 0 bonus',
dbms_redefinition.cons_use_pk);
END;
/
5. You have two methods for creating (cloning) dependent objects such
as triggers, indexes, grants, and constraints on the interim table.
Method 1 is the most automatic and preferred method, but there may be
times that you would choose to use method 2.
* Method 1: Automatically Creating Dependent Objects
Use the COPY_TABLE_DEPENDENTS procedure
to automatically create dependent objects such as triggers, indexes,
grants, and constraints on the interim table. This procedure also
registers the dependent objects. Registering the dependent objects
enables the identities of these objects and their cloned counterparts
to be automatically swapped later as part of the redefinition
completion process. The result is that when the redefinition is
completed, the names of the dependent objects will be the same as the
names of the original dependent objects.
You can discover if errors occurred
while copying dependent objects by checking the NUM_ERRORS output
variable. If the IGNORE_ERRORS parameter is set to TRUE, the
COPY_TABLE_DEPENDENTS procedure continues cloning dependent objects
even if an error is encounter when creating an object. The errors can
later be viewed by querying the DBA_REDIFINITION_ERRORS view. Reasons
for errors include a lack of system resources or a change in the
logical structure of the table.
If IGNORE_ERRORS is set to FALSE, the
COPY_TABLE_DEPENDENTS procedure stops cloning objects as soon as any
error is encountered.
After you correct any errors you can
attempt again to clone the failing object or objects by reexecuting the
COPY_TABLE_DEPENDENTS procedure. Optionally you can create the objects
manually and then register them as explained in method 2.
The COPY_TABLE_DEPENDENTS procedure can
be used multiple times as necessary. If an object has already been
successfully cloned, it will ignore the operation.
* Method 2: Manually Creating Dependent Objects
You can manually create dependent
objects on the interim table.
Note:
In previous releases you were required
to manually create the triggers, indexes, grants, and constraints on
the interim table, and there may still be situations where to want to
or must do so. In such cases, any referential constraints involving the
interim table (that is, the interim table is either a parent or a child
table of the referential constraint) must be created disabled. Until
the redefinition process is either completed or aborted, any trigger
defined on the interim table will not execute.
Use the REGISTER_DEPENDENT_OBJECT
procedure after you create dependent objects manually. You can also use
the COPY_TABLE_DEPENDENTS procedure to do the registration. Note that
the COPY_TABLE_DEPENDENTS procedure does not clone objects that are
registered manually.
You would also use the
REGISTER_DEPENDENT_OBJECT procedure if the COPY_TABLE_DEPENDENTS
procedure failed to copy a dependent object and manual intervention is
required.
You can query the
DBA_REDEFINITION_OBJECTS view to determine which dependent objects are
registered. This view shows dependent objects that were registered
explicitly with the REGISTER_DEPENDENT_OBJECT procedure or implicitly
with the COPY_TABLE_DEPENDENTS procedure. Only current information is
shown in the view.
The UNREGISTER_DEPENDENT_OBJECT
procedure can be used to unregister a dependent object on the table
being redefined and on the interim table.
BEGIN
DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS('hr',
'admin_emp','int_admin_emp',
TRUE, TRUE, TRUE, FALSE);
END;
/
6.Execute the DBMS_REDEFINITION.FINISH_REDEF_TABLE
procedure to complete the redefinition of the table. During this
procedure, the original table is locked in the exclusive mode for a
very short time, independent of the amount of data in the original
table. However, FINISH_REDEF_TABLE will wait for all
pending DML that was initiated before it was invoked to commit before
completing the redefinition. As a result of this procedure, the
following occur:
-
The original table is redefined such that it has all the
attributes,
indexes, constraints, grants and triggers of the interim table
-
The referential constraints involving the interim table now
involve the post redefined table and are enabled.
-
Dependent objects that were registered, either explicitly using REGISTER_DEPENDENT_OBJECT
or implicitly using COPY_TABLE_DEPENDENTS, are renamed
automatically.
Optionally, synchronize the
interim table hr.int_admin_emp.
BEGIN
DBMS_REDEFINITION.SYNC_INTERIM_TABLE('hr',
'admin_emp', 'int_admin_emp');
END;
/
Complete the redefinition.
BEGIN
DBMS_REDEFINITION.FINISH_REDEF_TABLE('hr',
'admin_emp', 'int_admin_emp');
END;
/
7. If the redefinition was done using rowids, the post-redefined table
will have a hidden column (M_ROW$$) and it is recommended that the user
set this hidden column to unused as follows:
ALTER TABLE table_name SET UNUSED (M_ROW$$)
After the redefinition process has been started by calling
START_REDEF_TABLE() and before FINISH_REDEF_TABLE() has been called, it
is possible that a large number of DML statements have been executed on
the original table. If you know this is the case, it is recommended
that you periodically synchronize the interim table with the original
table. This is done by calling the
DBMS_REDEFINITION.SYNC_INTERIM_TABLE() procedure. Calling this
procedure reduces the time taken by FINISH_REDEF_TABLE() to complete
the redefinition process.
The small amount of time that the original table is locked during
FINISH_REDEF_TABLE() is independent of whether SYNC_INTERIM_TABLE() has
been called.
In the event that an error is raised during the redefinition process,
or if you choose to terminate the redefinition process, call
DBMS_REDEFINITION.ABORT_REDEF_TABLE(). This procedure drops temporary
logs and tables associated with the redefinition process. After this
procedure is called, you can drop the interim table and its associated
objects.
Restrictions for Online
Redefinition of Tables
* If the table is to be redefined using primary key
or pseudo-primary keys (unique keys or constraints with all component
columns having not null constraints), then the table to be redefined
must have the same primary key or pseudo-primary key columns. If the
table is to be redefined using rowids, then the table must not be an
index-organized table.
* Tables that are replicated in an n-way master
configuration can be redefined, but horizontal subsetting (subset of
rows in the table), vertical subsetting (subset of columns in the
table), and column transformations are not allowed.
* The overflow table of an index-organized table
cannot be online redefined.
* Tables with user-defined types (objects, REFs,
collections, typed tables) cannot be online redefined.
* Tables with BFILE columns cannot be online
redefined.
* Tables with LONG columns can be online redefined,
but those columns must be converted to CLOBS. Tables with LONG RAW
columns must be converted to BLOBS. Tables with LOB columns are
acceptable.
* The table to be redefined cannot be part of a
cluster.
* Tables in the SYS and SYSTEM schema cannot be
online redefined.
* Temporary tables cannot be redefined.
* A subset of rows in the table cannot be redefined.
* Only simple deterministic expressions, sequences,
and SYSDATE can be used when mapping the columns in the interim table
to those of the original table. For example, subqueries are not allowed.
* If new columns (which are not instantiated with
existing data for the original table) are being added as part of the
redefinition, then they must not be declared NOT NULL until the
redefinition is complete.
* There cannot be any referential constraints
between the table being redefined and the interim table.
* Table redefinition cannot be done NOLOGGING.
* Tables with materialized view logs defined on them
cannot be online redefined.
Improvements on
10g r2
Enhanced COMMIT (10gr2)
When a session commits, the redo log buffer is
flushed to the online redo logs on disk. This process ensures that
transactions can be replayed from the redo logs if necessary when
recovery is performed on the database. Sometimes,
however, you may want to trade-off
the guaranteed ability to recover for better performance. With Oracle
Database 10g
Release 2, you now have control over how the redo stream is written to
the online log files. You can control this behavior while issuing the
commit statement itself, or simply make change the default behavior of
the database.
Let's see how the commit statement works. After
a transaction, when you issue COMMIT, you can have an
additional clause:
COMMIT WRITE
<option>
where the <option> is what
influences the redo stream. The option WAIT is the default
behavior. For instance, you can issue:
COMMIT WRITE
WAIT;
This command has the same effect as COMMIT
itself. The commit does not get the control back to the user until the
redo stream is written to the online redo log files.
If you don't want
it to wait, you could issue:
COMMIT
WRITE NOWAIT;
In this case, the control immediately returns to
the session, even before the redo streams are written to the online
redo logs.
When a commit is issued, the Log Writer process
writes the redo stream to the online redo logs. If you are making a
series of transactions, such as in a batch processing environment, you
may not want it to commit so frequently. Of course, the best course of
action is to change the application to reduce the number of commits;
but that may be easier said than done. In that case, you could simply
issue the following commit statement:
COMMIT WRITE
BATCH;
This command will make the commit write the redo
streams to the log file in batches, instead of at each commit. You can
use this technique to reduce log-buffer flushing in a frequent-commit
environment.
If you want to write the log buffer immediately, you would
issue:
COMMIT WRITE
IMMEDIATE;
If you want a specific commit behavior to be the
default for a database, you could issue the following statement.
ALTER SYSTEM
SET COMMIT_WRITE = NOWAIT;
This command will make this behavior the default
across the database. You can also make it at session level:
ALTER SESSION
SET COMMIT_WORK = NOWAIT;
As with any parameter, the parameter behaves the
setting at the system level, if set. If there is a setting at the
session level, the session level setting takes precedence and finally
the clause after the COMMIT statement, if given, takes precedence.
This option is not available for distributed
transactions.
The following code examples show the enhanced commit processing in
action. First we define a table for the code to populate.
CREATE TABLE commit_test (
id
NUMBER(10),
description
VARCHAR2(50),
CONSTRAINT commit_test_pk
PRIMARY KEY (id)
);
Next we see the variations of the WRITE clause in action. The code
truncates the table and measures the time taken to populate it with a
commit for each insert. This process is repeated for each variant of
the WRITE clause. All the times are measured in hundredths of a second.
SET SERVEROUTPUT ON
DECLARE
PROCEDURE do_loop
(p_type IN VARCHAR2) AS
l_start
NUMBER;
l_loops
NUMBER := 1000;
BEGIN
EXECUTE
IMMEDIATE 'TRUNCATE TABLE commit_test';
l_start :=
DBMS_UTILITY.get_time;
FOR i IN 1 ..
l_loops LOOP
INSERT INTO commit_test (id, description)
VALUES (i, 'Description for ' || i);
CASE p_type
WHEN 'WAIT' THEN COMMIT WRITE WAIT;
WHEN 'NOWAIT' THEN COMMIT WRITE NOWAIT;
WHEN 'BATCH' THEN COMMIT WRITE BATCH;
WHEN 'IMMEDIATE' THEN COMMIT WRITE IMMEDIATE;
END CASE;
END LOOP;
DBMS_OUTPUT.put_line(RPAD('COMMIT WRITE ' || p_type, 30) || ': ' ||
(DBMS_UTILITY.get_time - l_start));
END;
BEGIN
do_loop('WAIT');
do_loop('NOWAIT');
do_loop('BATCH');
do_loop('IMMEDIATE');
END;
/
COMMIT WRITE
WAIT
: 129
COMMIT WRITE
NOWAIT : 86
COMMIT WRITE
BATCH
: 128
COMMIT WRITE
IMMEDIATE : 128
Next we see the variations of the COMMIT_WRITE parameter in action.
This example follows the format of the previous example, but the
COMMIT_WRITE parameter is altered for each run and a standard commit is
issued.
SET SERVEROUTPUT ON
DECLARE
PROCEDURE do_loop
(p_type IN VARCHAR2) AS
l_start
NUMBER;
l_loops
NUMBER := 1000;
BEGIN
EXECUTE
IMMEDIATE 'ALTER SESSION SET COMMIT_WRITE=''' || p_type || '''';
EXECUTE
IMMEDIATE 'TRUNCATE TABLE commit_test';
l_start :=
DBMS_UTILITY.get_time;
FOR i IN 1 ..
l_loops LOOP
INSERT INTO commit_test (id, description)
VALUES (i, 'Description for ' || i);
COMMIT;
END LOOP;
DBMS_OUTPUT.put_line(RPAD('COMMIT_WRITE=' || p_type, 30) || ': ' ||
(DBMS_UTILITY.get_time - l_start));
END;
BEGIN
do_loop('WAIT');
do_loop('NOWAIT');
do_loop('BATCH');
do_loop('IMMEDIATE');
do_loop('BATCH,WAIT');
do_loop('BATCH,NOWAIT');
do_loop('IMMEDIATE,WAIT');
do_loop('IMMEDIATE,NOWAIT');
END;
/
COMMIT_WRITE=WAIT
: 141
COMMIT_WRITE=NOWAIT
: 90
COMMIT_WRITE=BATCH
: 78
COMMIT_WRITE=IMMEDIATE
: 94
COMMIT_WRITE=BATCH,WAIT
: 139
COMMIT_WRITE=BATCH,NOWAIT
: 78
COMMIT_WRITE=IMMEDIATE,WAIT
: 133
COMMIT_WRITE=IMMEDIATE,NOWAIT : 87
Catch
the Error and Move
On: Error Logging Clause (10gr2)
Suppose you are trying to insert
the records of
the table ACCOUNTS_NY into the table ACCOUNTS. The table ACCOUNTS has a
primary key on ACC_NO column. It's possible that some rows in
ACCOUNTS_NY may violate that primary key. Try using a conventional
insert statement:
insert into accounts
select * from accounts_ny;
insert into accounts
*
ERROR at line 1:
ORA-00001: unique constraint (ARUP.PK_ACCOUNTS) violated
None of the records from the table ACCOUNTS_NY
has been loaded. Now, try the same with error logging turned on. First,
you need to create a table to hold the records rejected by the DML
statement. Call that table ERR_ACCOUNTS.
exec dbms_errlog.CREATE_ERROR_LOG ('ACCOUNTS','ERR_ACCOUNTS');
Next, execute the earlier statement with the
error-logging clause.
insert into accounts
select * from accounts_ny
log errors into err_accounts
reject limit 200;
Note that the table ACCOUNTS_NY contains 10 rows
yet only six rows were inserted; the other four rows were rejected due
to some error. To find out what it was, query the ERR_ACCOUNTS table.
select ORA_ERR_NUMBER$, ORA_ERR_MESG$, ACC_NO
from err_accounts;
ORA_ERR_NUMBER$ ORA_ERR_MESG$ ACC_NO
--------------- -------------------------------------------------------- ------
1 ORA-00001: unique constraint (ARUP.PK_ACCOUNTS) violated 9997
1 ORA-00001: unique constraint (ARUP.PK_ACCOUNTS) violated 9998
1 ORA-00001: unique constraint (ARUP.PK_ACCOUNTS) violated 9999
1 ORA-00001: unique constraint (ARUP.PK_ACCOUNTS) violated 10000
Note the columns ORA_ERR_NUMBER$, which show the
Oracle error number encountered during the DML statement execution, and
the ORA_ERR_MESG$, which shows the error message. In this case you can
see that four records were rejected because they violated the primary
key constraint PK_ACCOUNTS. The table also captures all the column of
table ACCOUNTS, including the column ACC_NO. Looking at the rejected
records, note that these account numbers already exist in the table;
hence the records were rejected with ORA-00001 error. Without the
error-logging clause, the whole statement would have failed, with no
records rejected. Through this clause, only the invalid records were
rejected; all others were successful
The syntax for the error logging clause is the same for INSERT, UPDATE,
MERGE and DELETE statements.
LOG ERRORS
[INTO [schema.]table] [('simple_expression')] [REJECT LIMIT
integer|UNLIMITED]
The optional INTO clause allows you to specify the name of the
error logging table. If you omit this clause, the the first 25
characters of the base table name are used along with the "ERR$_"
prefix.
The simple_expression is used to specify a tag that makes the errors
easier to identify. This might be a string or any function whose result
is converted to a string.
The REJECT LIMIT is used to specify the maximum number of errors before
the statement fails. The default value is 0 and the maximum values is
the keyword UNLIMITED. For parallel DML operations, the reject limit is
applied to each parallel server.
Restrictions
The DML error logging functionality is not invoked when:
- Deferred constraints are violated.
- Direct-path INSERT or MERGE operations
raise unique constraint or index violations.
- UPDATE or MERGE operations raise a unique
constraint or index violation.
In addition, the tracking of errors in LONG, LOB
and object types is not supported, although a table containing these
columns can be the target of error logging.
UNDO_RETENTION
parameter (10gr2)
The UNDO_RETENTION parameter specifies the amount of time in seconds
that Oracle attempts to keep undo data available. Setting this
parameter to the appropriate value could be described as more of an art
than a science.
Set it too low and you are wasting disk space. In addition, you aren't
taking advantage of being able to flashback your data to as far back as
the disk space allocated to the undo tablespace allows. Set it too high
and you are in danger of running out of freespace in the undo
tablespace.
10G R2 comes to the rescue! The database now collects undo usage
statistics, identifies the amount of disk space allocated to the undo
tablespace and uses that information to tune the undo retention time
period to provide maximum undo data retention. Administrators can
determine the current retention time period by querying the
TUNED_UNDORETENTION column of the V$UNDOSTAT view.
You can also use the new Undo Advisor (Undo Management) under the
Advisor Central Option in OEM. It will show you a graphic with all the
possible values, when you click on the graphic, it will change the UNDO_RETENTION
and/ord the UNDO Tablespace size. Is very good for "what-if" analysis.
Unlimited DBMS
Output (10gr2)
In Oracle
Database
10g Release 2,, that
restriction has been lifted: The maximum output can now be as much as
required. You can set it to "unlimited" by simply issuing
set serveroutput on
In Oracle Database
10g Release
2, the command shows the following result:
show serveroutput
serveroutput ON SIZE UNLIMITED FORMAT WORD_WRAPPED
The default value is UNLIMITED.
Another inconvenience was the maximum size of a
line displayed by dbms_output. The following is a typical
error message for lines longer than 255 bytes.
ERROR at line 1:
ORA-20000: ORU-10028: line length overflow, limit of 255 chars per line
ORA-06512: at "SYS.DBMS_OUTPUT", line 35
ORA-06512: at "SYS.DBMS_OUTPUT", line 115
ORA-06512: at line 2
In Oracle Database 10g Release 2, the
lines can be of any length.
TRANSPORT AWR DATA (10g r2)
This new feature provides ability to move and consolidate AWR
(Automatic Workload Repository) data across databases. Rather
than impact the production system by analyzing the performance data on
it, you may now “export” the AWR data for any period of time and import
it into another database for analysis. This is accomplished via three
new routines:
• DBMS_SWRF_INTERNAL.AWR_EXTRACT
• DBMS_SWRF_INTERNAL.AWR_LOAD
• DBMS_SWRF_INTERNAL.MOVE_TO_AWR
The extract routine allows you to specify a begin and end snapshot
period to unload and creates a file in the file system. This file
can then be loaded into the target database via the load routine and
then moved into the actual AWR tables using the MOVE_TO_AWR routine.
Example:
A new package
DBMS_SWRF_INTERNAL has been provided in Oracle Database 10g
Release 2 for this purpose. To download it into a Data Pump dumpfile,
you would use the procedure AWR_EXTRACT:
1 begin
2 DBMS_SWRF_INTERNAL.AWR_EXTRACT (
3 dmpfile => 'awr_data.dmp',
4 dmpdir => 'TMP_DIR',
5 bid => 302,
6 eid => 305
7 );
8* end;
Let's examine the lines in more detail.
| Line |
Description |
| 3 |
The name of the target file for the data is mentioned here.
This is a Data Pump export file. If non filename is given, the default
value awrdat.dmp is used. |
| 4 |
The directory object where the dumpfile is written. In this
case, you may have defined a directory TMP_DIR as /tmp. |
| 5 |
The snapshot ID of the beginning snapshot of the period. |
| 6 |
The end snapshot ID. Here you are exporting the snapshots
between 302 and 305. |
Now you can take the dumpfile awr_data.dmp to
the new location and load it using another procedure in the same
package, AWR_LOAD:
1 begin
2 DBMS_SWRF_INTERNAL.AWR_LOAD (
3 SCHNAME => 'ARUP',
4 dmpfile => 'awr_data',
5 dmpdir => 'TMP_DIR'
6 );
7* end;
In this code, you are loading the contents of
the dumpfile awr_data.dmp into the directory specified by the directory
object TMP_DIR. When loading the AWR data, it is not loaded into the
SYS schema directly; rather, it's staged in a different schema first.
The schema name is given in the parameter SCHNAME, as shown in line 3.
After staging, the data is moved into the SYS schema:
1 begin
2 DBMS_SWRF_INTERNAL.MOVE_TO_AWR (
3 SCHNAME => 'ARUP'
4 );
5* end;
Here you are moving the AWR data from the schema
ARUP to SYS.
Moving AWR to a different database, as I
mentioned above, has a lot of benefits and uses. You can analyze the
data in a different database without affecting production too much. In
addition, you can build a central repository of AWR data collected from
multiple databases.
All these loading steps have been placed into a
single file awrload.sql located in $ORACLE_HOME/rdbms/bin directory.
Similarly, the script awrextr.sql contains all the steps for the
extraction process.