Oracle High
Availability SolutionS
Introduction
One of the biggest responsibilities for a database administrator is to provide high availability and reduce planned or unplanned downtime for a database. However, this has become a major challenge as our database size increased so dramatically over the years and our critical business information system requires 24x7 uptime. In an unplanned downtime when a terabyte database was corrupted, it may take hours, even days to restore such a database. To minimize downtime and avoid data loss, we need database technologies that can provide high availability solutions.
Oracle technology meets such challenges. Oracle provides four popular high availability solutions:
- Oracle Advanced Replication
- Oracle Real Application Clusters (RAC)
- Oracle Data Guard (physical/logical standby database)
- Oracle Streams
This paper provides an overview of Oracle latest high
availability solutions. It offers an
introduction to the basic concepts and architectures of the four
products and
discusses the requirements and steps for setting up each high
availability
solution. It also provides performance
analysis and implementation tips for the four products. The
paper helps readers choose the right
high-availability solutions to fit their business needs at low cost.
High-Availability
Concepts
Computing environments configured to provide nearly full-time availability is known as high availability system. Such systems typically have redundant hardware and software that makes the system available despite failures. Well-designed high availability systems avoid having single points-of-failure.
When failures occur, the failover process moves processing performed by the failed component to the backup component. This process remasters system wide resources, recovers partial or failed transactions, and restores the system to normal, preferably within a matter of microseconds. The more transparent that failover is to users, the higher the availability of the system.
High
Availability Measurements
There are three types of metrics to measure high availability:
The
mean time to recovery (mttr)
It measures the average time to recover/restore a system after each failure.
The
mean time between failures (mtbf)
It measures frequency of system failure occurs. It is generally more applicable to hardware availability metrics.
Total
Uptime In a Year (%)
It measures the percentage of time the system is up and available in a year. The table below shows the percent of system uptime in a year from a 5 minutes downtime to a 2 days downtime.
|
Minutes of Downtime |
5 |
60 |
1440 |
2880 |
|
Minutes of Uptime |
525595 |
525540 |
524160 |
522720 |
|
Minutes in a Year |
525600 |
525600 |
525600 |
525600 |
|
Total Uptime in a Year (%) |
99.9990% |
99.9886% |
99.7260% |
99.4521% |
Oracle provides four popular high availability solutions:
1-
Oracle Advanced Replication
Replication is the process of copying and maintaining database objects, such as tables, in multiple database that make up a distributed database system. Changes applied at one site are captured and stored locally before being forwarded and applied at each of the remote locations.
Replication supports a variety of applications that often have different requirements. Some applications allow for relatively autonomous individual materialized view sites. Other applications require data on multiple servers to be synchronized in a continuous, nearly instantaneous manner to ensure that the service provided is available and equivalent at all times.
Replication
Components
Replication
Objects
· Tables and Indexes
· Views and Object Views
· Packages and Procedures
· Function and Triggers
· Synonyms
· Indextypes and user-Defined Operators
Replication
Groups
Oracle manages replication objects using replication groups. A replication group is a collection of replication objects that are logically related. Each replication object can be a member of only one replication group.
Replication
Sites
Masters Sites – A master site maintains a complete copy of all objects in a replication group. A replication group at a master site is more specifically referred to as master group.
Materialized View Sites – A materialized view site can contain all or a subset of the table data within a master group. A replication group at a materialized view site is based on a master group and is more specifically referred to as a materialized view group.
Types
of Replication
Advanced Replication supports the following types of replication environment:
Multimaster
Replication
Multimaster replication includes multiple master sites; each master site operates as an equal peer. Multimaster replication provides complete replicas of each replicated table at each of the master sites. Multimaster replication can be used to protect the availability of a mission critical database; therefore, it provides high availability to the database system during failover.
There are two types of multimaster replication:
Asynchronous Replication, also referred to as store-and-forward replication, is the default mode of replication. It captures any changes (also called deferred transaction), stores them in a queue, and propagates and applies these changes at remote sites at regular intervals
Synchronous Replication, also know as real-time replication, applies any changes or executes any replicated procedures at all sites participating in the replication environment as part of a single transaction. If the data changes or procedure fails at any site, then the entire transaction rolls back. This strict ensures data consistency at all sites in real-time.

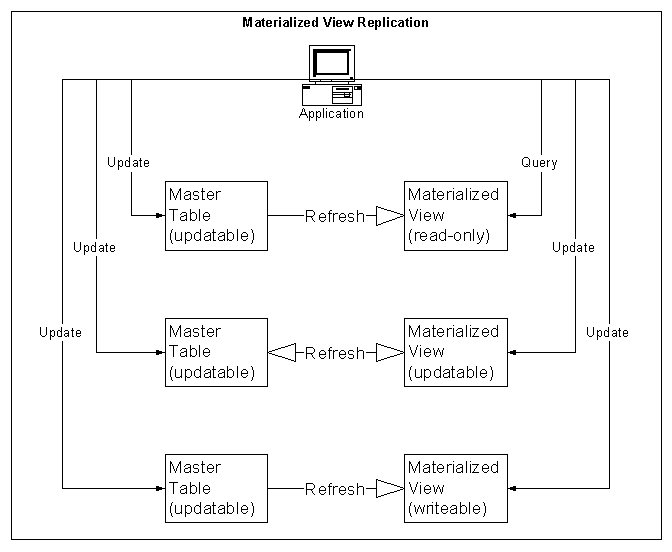
Materialized
View Replication
A materialized view is a replica of a target master from single point in time. Whereas in multimaster replication tables are continuously updated by other master sites, materialized views are updated from one or more masters through individual batch updates, known as a refreshes, from a single master site or master materialized view site.
The benefits of materialized views include:
· Ease Network Loads
· Create a Mass Deployment environment
· Enable Date Subsetting
· Enable Disconnected Computing
There are three types of materialized views:
Read-Only Materialized Views - Application can query data from read-only materialized views, however, data manipulation language (DML) changes must perform at the master site.
Updateable Materialized Views – Application can insert, update, and delete rows of the target master table or master materialized view by performing these operations on the materialized view.
Writeable Materialized Views – You can create a materialized view
using the FOR
UPDATE clause yet never add the materialized view to a materialized
view
group. Application can perform data
changes on the materialized view; however, changes will not pushed back
to the
master.
Administration
Tools for Replication Environment
Oracle
Oracle Enterprise Manager’s Replication Management tool helps to configure and administer replication environments.
Replication
Management API
The replication management API is a set of PL/SQL packages you can use to configure an Advanced Replication environment.
Replication
Catalog
The replication catalog contains administrative information about replication objects and replication groups in a replication environment.
2-
Oracle Real Application Clusters (RAC)
Oracle Real Application Clusters (RAC) allows multiple instances accessing a single database. The typical installation involves a cluster of nodes with access to a set of shared disks.
RAC
Components
Real Application Clusters consists of the following components:

Local
Disks
Local disks attached to each individual node. Each instance’s Oracle executables and archive logs are stored on each node’s local disks
Shared
Disks
The shared disks store database files, online redo, and control files.
Vendor
CMS
Vendor-provided Cluster Management Software allows multiple nodes to shared disks and communicate with each via cluster interconnect.
Cluster
Group Services (CGS)
A layer of Oracle software, the CGS provides an interface to the vendor’s CMS and performs its own instance validation checks.
Global
Resource Directory
The resources in the Global Resource Directory are re-mastered dynamically among different instances.
RAC
Background processes
LMSn (Global Cache Service Process) – This process transmits both the consistent read and the current blocks from holding instances to requesting instances.
LMON (Global Enqueue Service Monitor) – This process handles remote resource requests and monitors the health of the Global Cache Service.
LMD (Global Enqueue Service Daemon) – the resource agent process manages Global Enqueue Service resource requests. The LMD process also handles deadlock detection Global Enqueue Service requests.
Cache
Fusion (Global Cache
Services)
Cache Fusion is Oracle’s Global Cache Management technology. The key characteristic of Real Application Clusters database is their ability to maintain consistent and coherent database buffer caches across instances. It allows instances to combine their data caches into a shared global cache. This means that if a block is needed by an instance, the Global Cache Services will ensure that the instance is using the correct version of the block.
Transparent
Application Failover (TAF)
Transparent Application Failover (TAF) enables an application user to automatically reconnect to a database if the connection fails. Active transaction rollback, but the new database connection, made by way of a different node, is identical to the original. With TAF, a client notices no loss of connection as long as there is one instance left serving the application.
3-Oracle
Data Guard
Oracle Data Guard is the management, monitoring, and automation software that work with a production database and one or more standby databases to protect data against failures, errors, and corruption that might otherwise destroy your database.
Data
Guard Components
Oracle Data Guard consists of the following components:
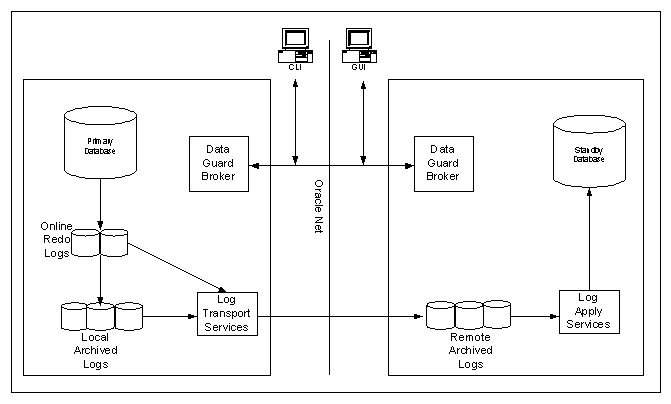
Primary
Database:
A primary database is a production database. The primary database is used to create a standby database. Every standby database is associated with one and only one primary database.
Standby
Database:
A physical or logical standby database is a database replica created from a backup of a primary database.
- A physical standby database is physically identical to the primary database on a block-for-block basis. It is updated by performing recovery from redo logs generated from the primary database.
- A logical standby database is logically identical to the primary database. It is updated using SQL statements.
Log
Transport Services:
Log transport services control the automated transfer of archived redo from the primary database to one or more standby sites.
Network
Configuration:
The primary database is connected to one or more remote standby database via Oracle Net.
Log
Apply Services:
Log apply services apply the archived redo logs to the standby database.
Data
Guard Broker:
Data Guard Broker is the management and monitoring component with which you configure, control, and monitor a fault tolerant system consisting of a primary database protected by one or more standby database.
Data
Guard Roles
A database can operate in one of the two mutually exclusive roles: primary or standby database.
Failover
During a failover, one of the standby databases takes the primary database role.
Switchover
In Oracle, primary and standby database can continue to alternate roles. The primary database can switch the role to a standby database; and one of the standby databases can switch roles to become the primary.
Data
Guard Interfaces
Oracle provides three ways to manage a Data Guard environment:
SQL*Plus
and SQL Statements
Using SQL*Plus and SQL commands to manage Data Guard environment.
The following SQL statement initiates a switchover operation:
SQL> alter database commit to switchover to physical standby;
Data
Guard Broker GUI Interface (Data Guard Manager)
Data Guard Manger is a GUI version of Data Guard broker interface that allows you to automate many of the tasks involved in configuring and monitoring a Data Guard environment.
Data
Guard Broker Command-Line Interface (CLI)
It
is an
alternative interface to using the Data Guard Manger.
It is useful if you want to use the broker
from batch programs or scripts. You can
perform most of the activities required to manage and monitor the Data
Guard
environment using the CLI.
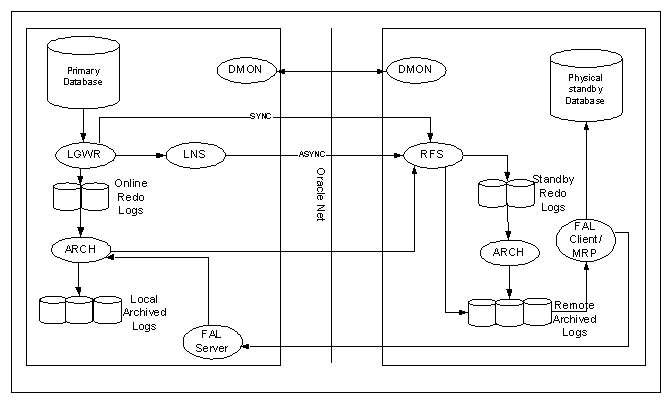
Physical
Standby Processes Architecture
The log transport services and log apply services use the following processes to ship and apply redo logs to the physical standby database:
On the primary database site, the log writer process (LGWR) collects transactions from the log buffer and writes to the online redo logs. The archiver process (ARCH) creates a copy of the online redo logs, and writes to the local archive destination. Depending on the configuration, the archiver process or log writer process can also transmit redo logs to standby database. When using the log writer process, you can specify synchronous or asynchronous network transmission of redo logs to remote destinations. Data Guard achieves synchronous network I/O using LGWR process. Data Guard achieves asynchronous network I/O using LGWR network server process (LNS). These network severs processes are deployed by LOG_ARCHIVE_DEST_n initialization parameter.
On the standby database site, the remote file server process (RFS) receives archived redo logs from the primary database. The primary site launches the RFS process during the first log transfer. The redo logs information received by the RFS process can be stored as either standby redo logs or archived redo logs. Data Guard introduces the concept of standby redo logs (separate pool of log file groups). Standby redo logs must be archived by the ARCH process to the standby archived destination before the managed recovery process (MRP) applies redo log information to the standby database.
The fetch archive log (FAL) client is the MRP process. The fetch archive log (FAL) server is a foreground process that runs on the primary database and services the fetch archive log requests coming from the FAL client. A separate FAL server is created for each incoming FAL client.
When using Data Guard broker (dg_broker_start = true), the monitor agent process named Data Guard Broker Monitor (DMON) is running on every site (primary and standby) and maintain a two-way communication.
Logical
Standby Processes Architecture
The major difference between the logical and physical standby database architectures is in its log apply services.
The logical standby process (LSP) is the coordinator process for two groups of parallel execution process (PX) that work concurrently to read, prepare, build, and apply completed SQL transactions from the archived redo logs sent from the primary database. The first group of PX processes read log files and extract the SQL statements by using LogMiner technology; the second group of PX processes apply these extracted SQL transactions to the logical standby database. The mining and applying process occurs in parallel. Logical standby database does not use standby online redo logs. Logical standby database does not have FAL capabilities in Oracle. All gaps are resolved by the proactive gap resolution mechanism running on the primary that polls the standby to see if they have a gap.
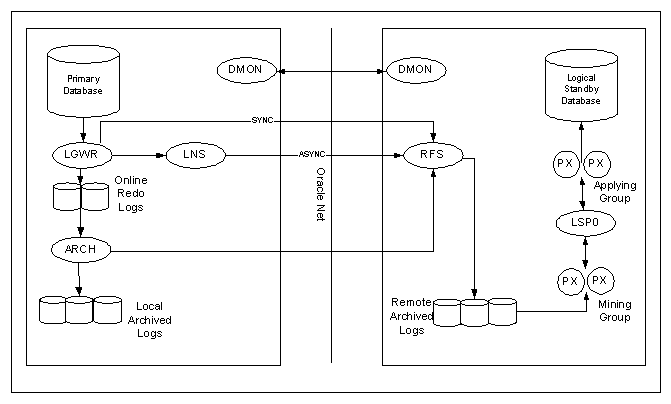
Note: Logical Standby database is an Oracle9i Release 2 feature. In 9.2, the LGWR SYNC actually does use the LNS as well. Only SYNC=NOPARALLEL goes directly from the LGWR. The default SYNC mode is SYNC=PARALLEL.
Data
Guard data protection modes:
Oracle provides three data
protection modes:
Maximum Protection: It offers the highest level of data availability for the primary database. Redo records are synchronously transmitted from the primary database to the standby database using LGWR process. Transaction is not committed on the primary database until it has been confirmed that the transaction data is available on at least one standby database. This mode is usually configured with at least two standby databases. If all standby databases become unavailable, it may result in primary instance shutdown. This ensures that no data is lost when the primary database loses contact with all the standby databases. Standby online redo logs are required in this mode. Therefore, logical standby database cannot participate in a maximum protection configuration.
Maximum Availability: It offers the next highest level of data availability for the primary database. Redo records are synchronously transmitted from the primary database to the standby database using LGWR process. The transaction is not complete on the primary database until it has been confirmed that the transaction data is available on the standby database. If standby database becomes unavailable, it will not shut down the primary database. Instead, the protection mode is temporarily switched to maximum performance mode until the fault has been corrected and the standby database will re-synchronize with the primary database. This protection mode supports both physical and logical standby databases.
Maximum Performance: It is the default protection mode. It offers slightly less primary database protection than maximum availability mode but with higher performance. Redo logs are asynchronously shipped from the primary database to the standby database using either LGWR or ARCH process. When operating in this mode, the primary database continues its transaction processing without regard to data availability on any standby databases and there is little or no effect on performance. This protection mode is similar to the combination of 9iR1’s Instance, Rapid, and Delay modes. It supports both physical and logical standby databases.
|
Mode |
Log Writing Process |
Network Trans Mode |
Disk Write Option |
Redo Log Reception Option |
Supported on |
|
Maximum Protection |
LGWR |
SYNC |
AFFIRM |
Standby redo logs are required |
Physical standby databases |
|
Maximum Availability |
LGWR |
SYNC |
AFFIRM |
Standby redo logs |
Physical and logical standby databases |
|
Maximum Performance |
LGWR or ARCH |
ASYNC if LGWR |
NOAFFIRM |
Standby redo logs |
Physical and logical standby databases |
4-Oracle
Streams
Oracle Streams enables you to share data and events in a stream. The stream can propagate this information within a database or from one database to another. The stream routes specified information to specified destinations.
Using Oracle Streams, you control what information is put into a stream, how the stream flows or is routed from database to database, what happens to events in the stream as they flow into each database, and how the stream terminates.
Streams can capture, stage, and manage events in the database automatically, including, but not limited to, data manipulation language (DML) changes and data definition language (DDL) changes. You can configure Stream to captures changes made to tables, schemas, or the entire database.
The most notable difference between a logical standby database and a Streams data replication environment is where the changes are captured.
Stream
Architecture Overview
Using Oracle Streams, you control what information is put into a stream, how the stream flows or is routed from database to database, what happens to events in the stream as they flow into each database, and how the stream terminates. By configuring specific capabilities of Streams, you can address specific requirements. Based on your specifications, Streams can capture, stage, and apply changes in the database automatically, including, but not limited to, data manipulation language (DML) changes and data definition language (DDL) changes. You can also put user-defined events into a stream. Streams can propagate the information to other databases or applications automatically. Again, based on your specifications, Streams can apply events at a destination database.
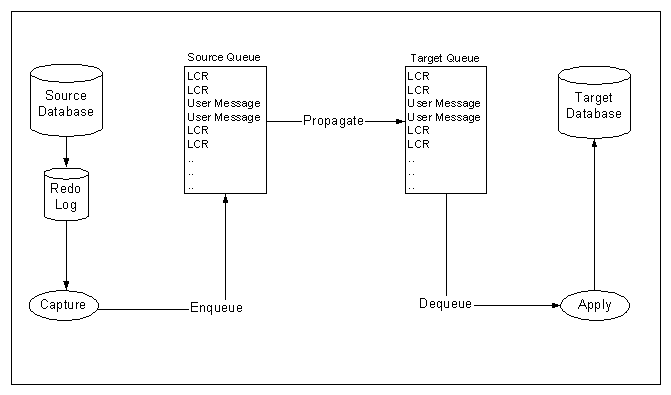
Below are five steps on how Oracle Streams replicate its information.
1. Capture changes at a database: You can configure a background capture process to capture changes made to tables, schemas, or the entire database. A capture process captures changes from the redo log and formats each captured change into a logical change record (LCR). The database where changes are generated in the redo log is called the source database.
2. Enqueue events into a queue. Two types of events may be staged in a Streams queue: LCRs and user messages. A capture process enqueues LCR events into a queue that you specify. The queue can then share the LCR events within the same database or with other databases. You can also enqueue user events explicitly with a user application. These explicitly enqueued events can be LCRs or user messages.
3. Propagate events from one queue to another. These queues may be in the same database or in different databases.
4. Dequeue events. A background apply process can dequeue events. You can also dequeue events explicitly with a user application.
5. Apply events at a database. You can configure an apply process to apply all of the events in a queue or only the events that you specify. You can also configure an apply process to call your own PL/SQL subprograms to process events. The database where LCR events are applied and other types of events are processed is called the destination database. In some configurations, the source database and the destination database may be the same.
Stream
Capture Process
A capture process (whose process name is cpnn, where nn is a capture process number) is an optional Oracle background process that reads the database redo log to capture DML and DDL changes made to database objects. A capture process reformats changes captured from the redo log into Logical Change Records (LCRs). An LCR is an object with specific format that describes a database change.
A Capture process captures two types of LCRs: row LCRs and DDL LCRs. A row LCR describes a change to the data in a single row or a change to a single LOB column in a row. A captured row LCR may also contain transaction control statements, such as COMMIT and ROLLBACK. These row LCRs are internal and are used by an apply process to maintain transaction consistency between a source database and a destination database. A DDL LCR describes a data definition language (DDL) change. A DDL statement changes the structure of the database, such as CREATE, ALTER, or DROP a database object.
A capture process never captures changes in the SYS and SYSTEM schemas. The system change number (SCN) are important for a capture process. The start SCN is the SCN from which a capture process begins to capture changes. The captured SCN is the SCN that corresponds to the most recent change captured by a capture process. The applied SCN for a capture process is the SCN of the most recent event dequeued by the relevant apply processes.
Event
Staging and Propagation
Streams use queues of type SYS.AnyData to stage event. There are two types of events that can be staged in a Streams queue: logical change records (LCRs) and user messages. LCRs are objects that contain information about a change to a database object, while user messages are custom messages created by users or applications.
The queue from which the events are propagated is called the source queue, and the queue that receives the events is call destination queue. There can be one-to-many, many-to-one, or many-to-many relationship between source and destination queues.
A directed network is one in which propagated events may pass through one or more intermediate database before arriving at a destination database. An intermediate database in a directed network may propagate events using queue forwarding or apply forwarding. Queue forwarding means that the events being forwarded at an intermediate database are the events received by the intermediate database. The source database for an event is the database where the event originated. Apply forwarding means that the events being forwarded at an intermediate database are first processed by an apply process. These events are then recaptured by a capture process at the intermediate database and forwarded. Then you use apply forwarding, the intermediate database becomes the new source database for events because the events are recaptured there.
In general, Streams queues and propagations use the infrastructure of AQ. However, unlike an AQ queue, which stages all events in a queue table, a Streams queue has a queue buffer to stage captured events in shared memory. A queue buffer is System Global Area (SGA) memory associated with a Streams queue that contains only captured events. A queue buffer enables Oracle to optimize captured events by buffering captured events in the SGA instead of always storing them in a queue table. User-enqueued LCR events and user-enqueued non-LCR events are always staged in queue tables, not in queue buffers.
A Streams propagation is configured internally using the DBMS_JOBS package. Therefore, a propagation job is the mechanism that propagates events from a source queue to a destination queue. Like other jobs configured using the DBMS_JOBSpackage, propagation jobs have an owner, and they use job queue processes (Jnnn) as needed to execute jobs.
Streams
Apply Process
An apply process is an optional Oracle background process that dequeues logical change records (LCRs) and user messages from a specific queue and either applies each one directly or passes it as a parameter to a user-defined procedure. The LCRs dequeued by an apply process contain data manipulation language (DML) changes or data definition language (DDL) changes that an apply process can apply to database objects in a destination database.
You can create, alter, start, stop, and drop an apply process, and you can define apply rules that control which events an apply process dequeues from the queue. The user who creates an apply process is, by default, the user who applies changes. An apply process also automatic detects conflicts and resolves conflicts.
Rules
You can setup rules to control which information to share and where to share it. Rules can be used during capture, propagation and apply process. You can define rules at three different levels:
· Table rules
· Schema rules
· Global rules
Administration
Tools for Oracle Streams
You can use the following three tools to configure, administer, and monitoring a Streams environment.
· Oracle-Supplied PL/SQL packages
· DBMS_STREAMS_ADM
· DBMS_CAPTURE_ADM
· DMBS_PROPAGATION_ADM
· DBMS_APPLY_ADM
· Data Dictionary Views
· DBA_APPLY
· DBA_CAPTURE
· V$STREAM_CAPTURE
· Oracle Enterprise Manager
Choosing
the Right Solution
The big question is which product should I choose for high-availability solution in an organization. The answer is that it all depends on the nature of your business. Let us examine it from the following catalogs:
Oracle
Licensing
|
Oracle High Availability Product |
|
|
Advanced Replication |
Included |
|
Real Application Clusters (RAC) |
Additional license fee |
|
Data Guard |
Included |
|
Streams |
Included |
Oracle
Streams and Logical Standby Database:
|
Supported Datatypes |
Unsupported Datatypes |
|
· CHAR, NCHAR · VARCHAR2, NVARCHAR2 · NUMBER · DATE · CLOB,BLOB · RAW · TIMESTAMP · TIMESTAMP WITH TIME ZONE · TIMESTAAMP WITH LOCAL TIME ZONE · INTERVAL YEAR TO MONTH · INTERVAL DAY TO SECOND |
· NCLOB · LONG · LONG RAW · BFILE · ROWID · UROWID · User-defined types · Object types · REFS · Varrays · Nested tables |
Major
Feature Comparison
|
|
Advanced Replication |
Real Application Clusters |
Data Guard Physical Standby |
Data Guard Logical Standby |
Oracle Streams |
|
Entire Database Replication |
YES |
N/A |
YES |
YES |
YES |
|
Schema Replication |
YES |
N/A |
NO |
NO |
YES |
|
Table Replication |
YES |
N/A |
NO |
NO |
YES |
|
DML Replication |
YES |
N/A |
YES |
YES |
YES |
|
DDL Replication |
YES |
N/A |
YES |
YES |
YES |
|
Instance Redundant |
YES |
YES |
YES |
YES |
YES |
|
Database Redundant |
YES |
NO |
YES |
YES |
YES |
|
Cluster Management Software |
NO |
YES |
NO |
NO |
NO |
|
Failover Mechanism |
Manual Failover |
Transparent Application Failover |
Failover and Switchover |
Failover and Switchover |
Manual Failover |
|
Load Balancing |
YES |
YES |
YES/Partial |
YES |
YES |
|
Change Captured |
Local |
Local |
Remote |
Remote |
Local |
|
OS Platform Between Source and Target |
Can Be Different |
Must Be Same |
Must Be Same |
Must Be Same |
Can Be Different |
|
Oracle Version Between Source and Target |
Can Be Different |
Must Be Same |
Must Be Same |
Must Be Same |
Can be Different |
|
Heterogeneous Database Support |
YES |
NO |
NO |
NO |
YES |
|
Physical Distinct between Source and Target |
Local/Remote |
Local |
Local/Remote |
Local/Remote |
Local/Remote |
|
Datatype Support |
ALL |
ALL |
Do not support all datatype |
Do not support all datatype |
Do not support all datatype |